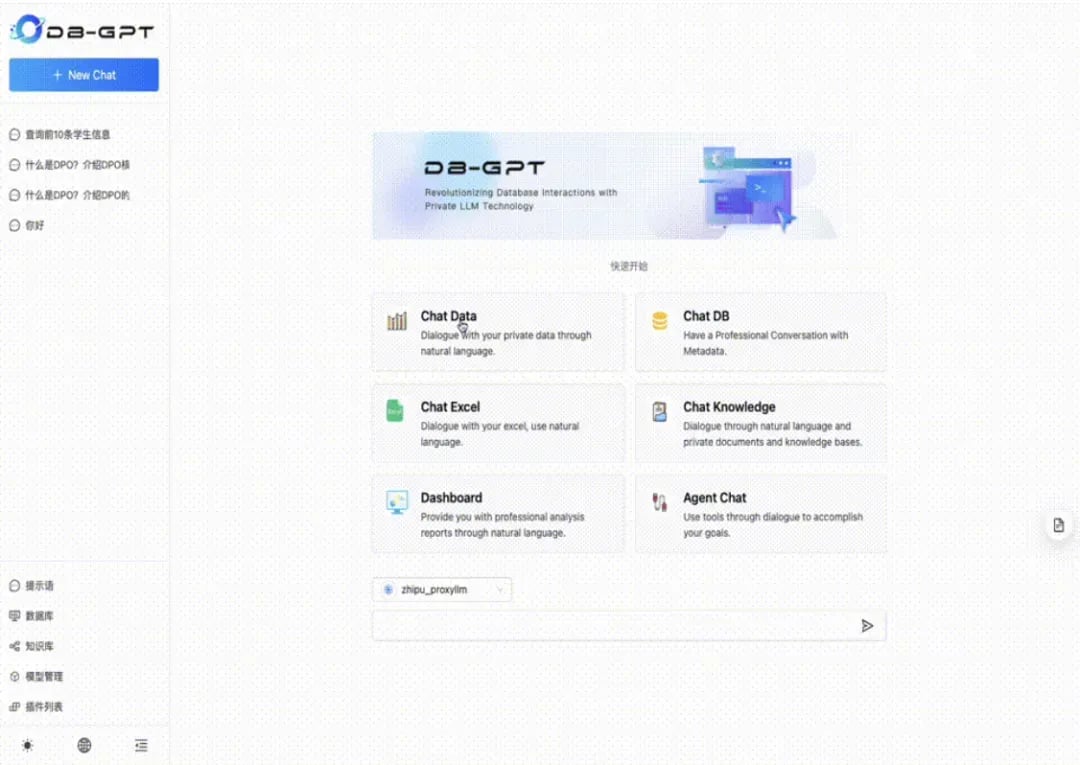
1.About DB-GPT
DB-GPT is an open-source AI-native data framework with AWEL (Agentic Workflow Expression Language) and Agents. The goal is to build infrastructure for the large model domain, through the development of multiple capabilities such as Multi-Model Management (SMMF), Text2SQL performance optimization, RAG framework and optimization, multi-agents framework collaboration, and AWEL (intelligent orchestration). This makes it easier and more convenient to build data model applications around databases.2.Obtain API key
2.1. Open the SiliconFlow website and register an account (if you have an existing account, log in directly). 2.2. After completing the registration, go to the API Keys to create API the future use.3.Deploy DB-GPT
3.1 Clone the DB-GPT Source Code
3.2 Create a Virtual Environment and Install Dependencies
3.3 Configure basic environment variables
3.4 Modify the environment variables file .env to configure siliconCloud models
3.5 Start DB-GPT service
4.Use SiliconFlow models via DB-GPT python SDK
4.1 Install the DB-GPT Python Package
4.2. Use the large language model from SiliconFlow
4.3 Use the embedding model from SiliconFlow
4.4 Use the rerank model from SiliconFlow
5. Hands-on guide
For a data conversation example, data conversation capabilities involve natural language interaction with structured and semi-structured data, which can assist in data analysis and insights. Below are the specific operational steps:1. Add data sources
First, select the data on the left side. Add a database, currently, DB-GPT supports various database Choose the corresponding database type to add. Here, we use MySQL as a demonstration. The test data for the demonstration can be found in the [test examples](https://github.com/eosphoros-ai/DB-GPT/tree/main/docker/examples/sqls).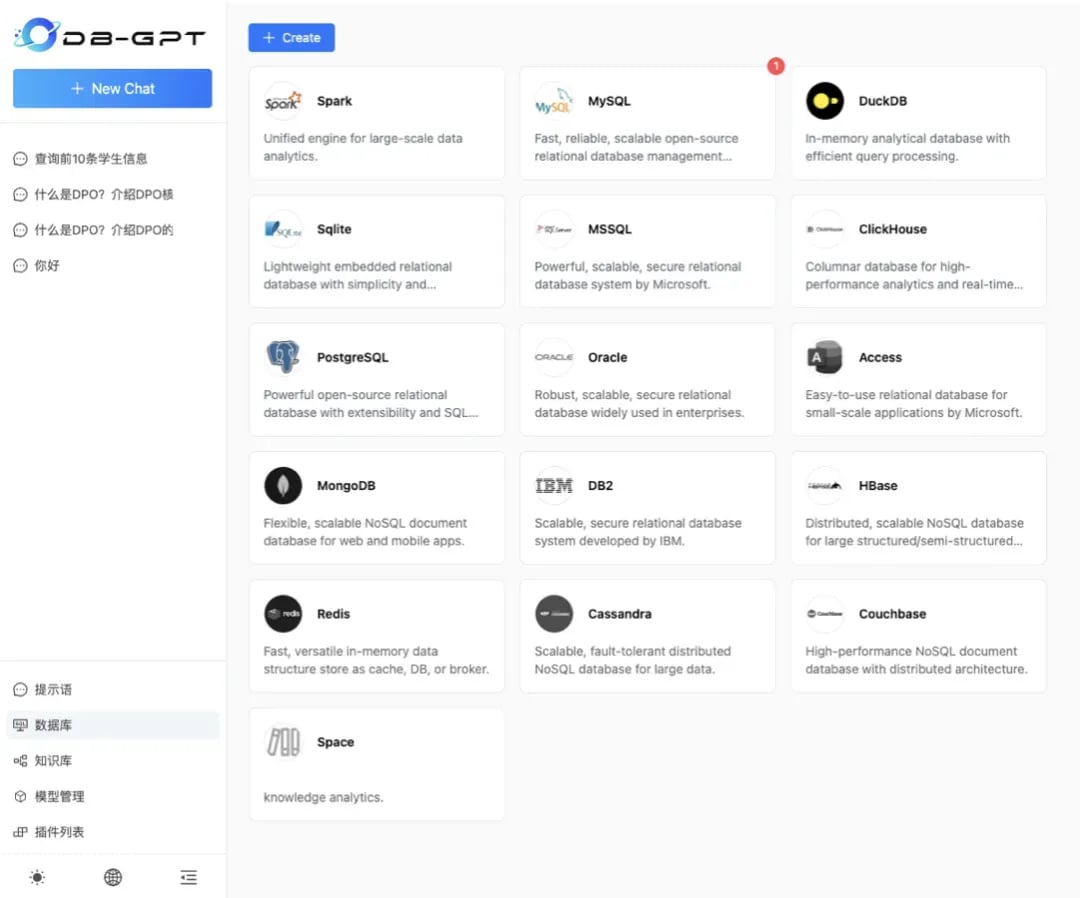
2. Select conversation type
Select the ChatData conversation type.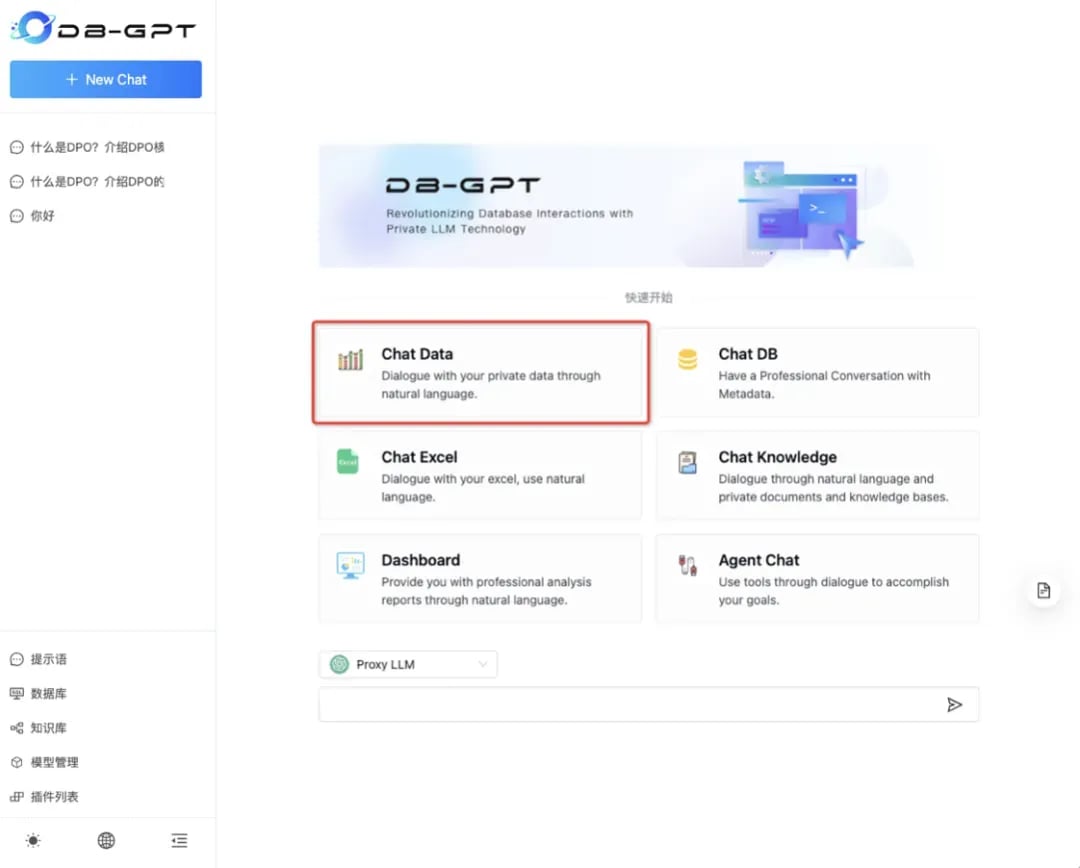
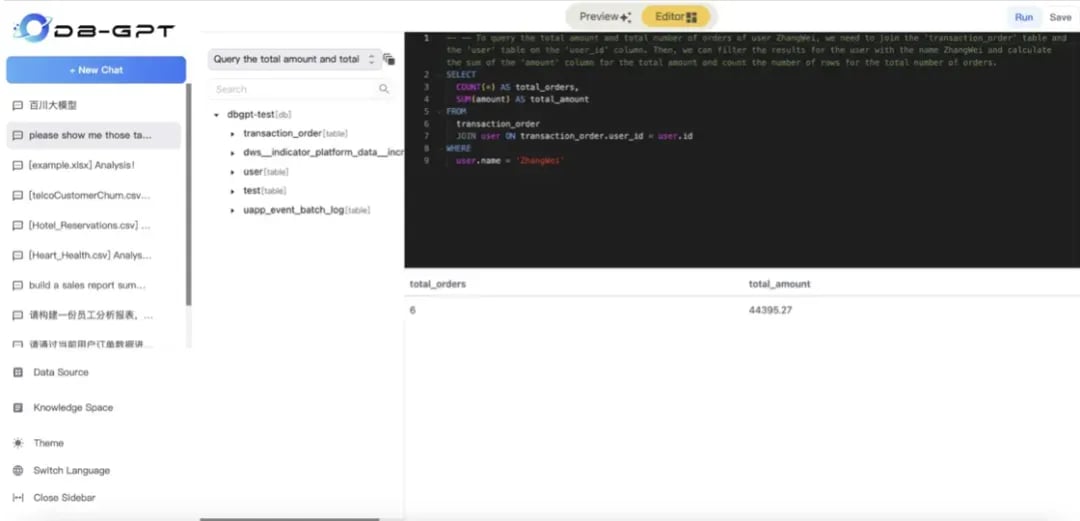
3. Start data conversation
Note: When conversing, select the corresponding model and database. DB-GPT also provides preview and edit modes.