大模型配置
目前新用户可以在引导页直接选择使用硅基流动提供的免费模型 API:
配置语音识别 API
在软件首页可以进入语音识别设置和 AI 后处理设置两个入口。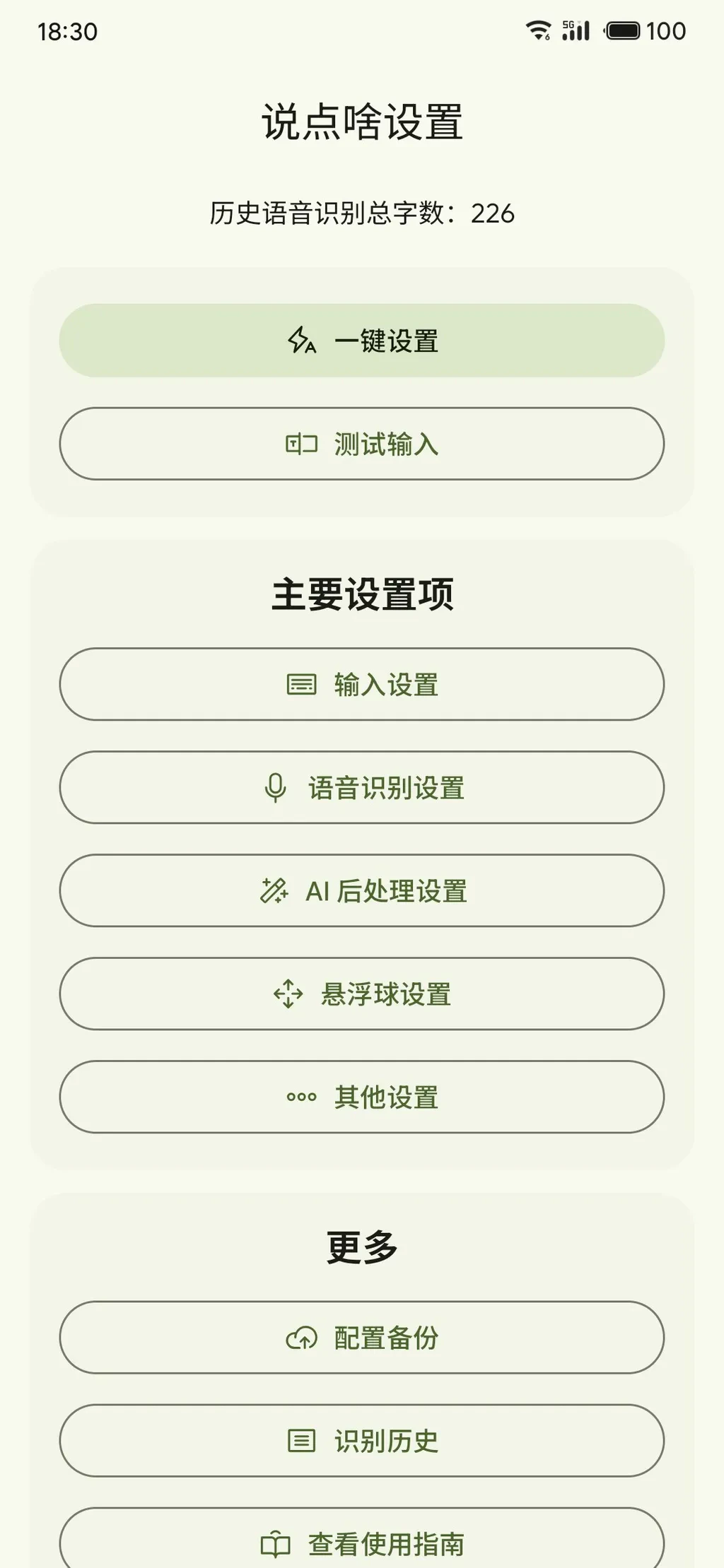
- TeleAI/TeleSpeechASR
- FunAudioLLM/SenseVoiceSmall
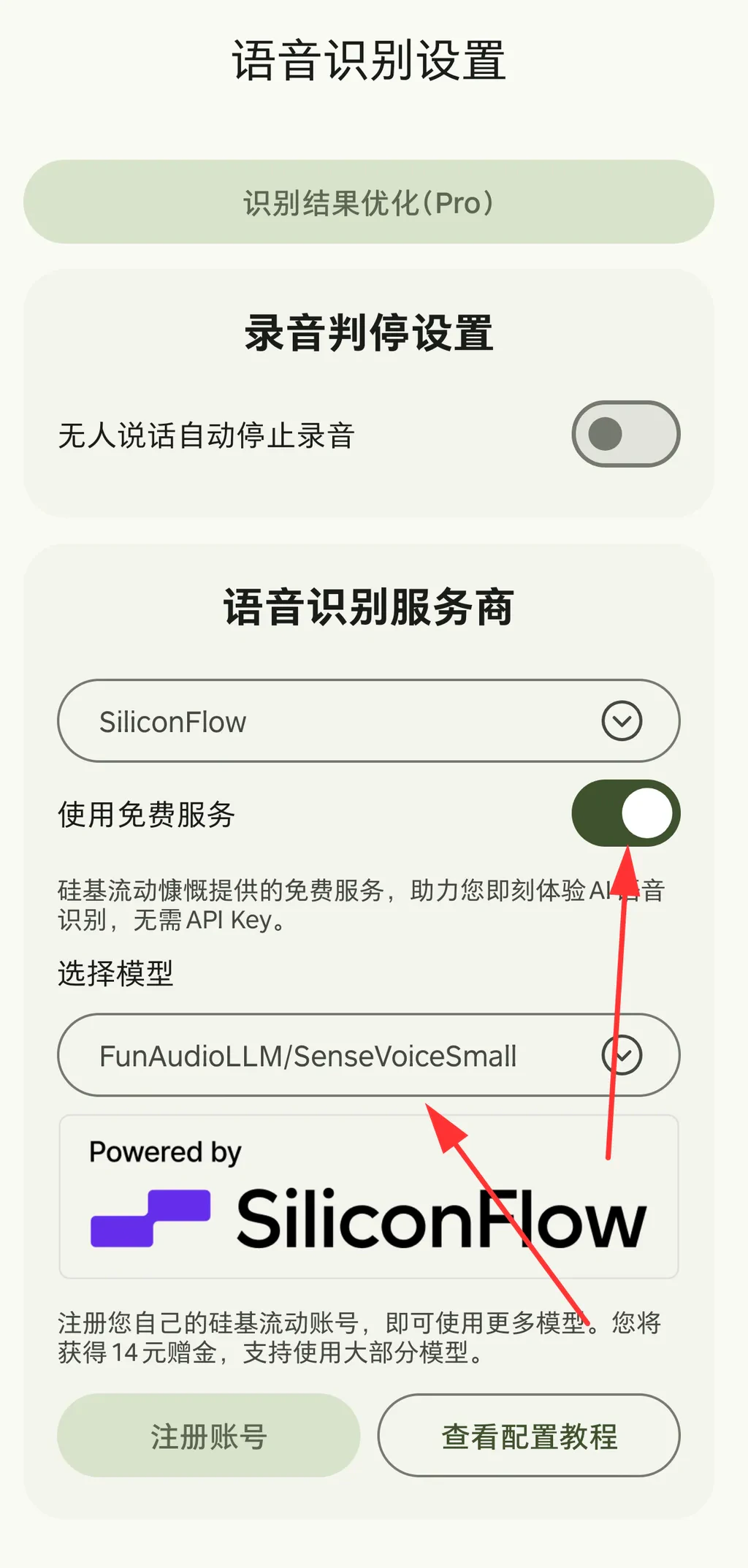
- Qwen/Qwen3-Omni-30B-A3B-Instruct(多模态模型,可输入音频,更好更快)
- Qwen/Qwen3-Omni-30B-A3B-Thinking(多模态模型,可输入音频,效果最好但略慢)
- TeleAI/TeleSpeechASR
- FunAudioLLM/SenseVoiceSmall
配置后处理 API
后处理功能帮助优化语音识别效果或完成部分特色功能,例如识别完成后进行翻译、总结识别内容中的代办信息等。硅基流动免费提供两个快速模型:- Qwen/Qwen-3-8B(推理模型)
- THUDM/GLM-4-9B-0414
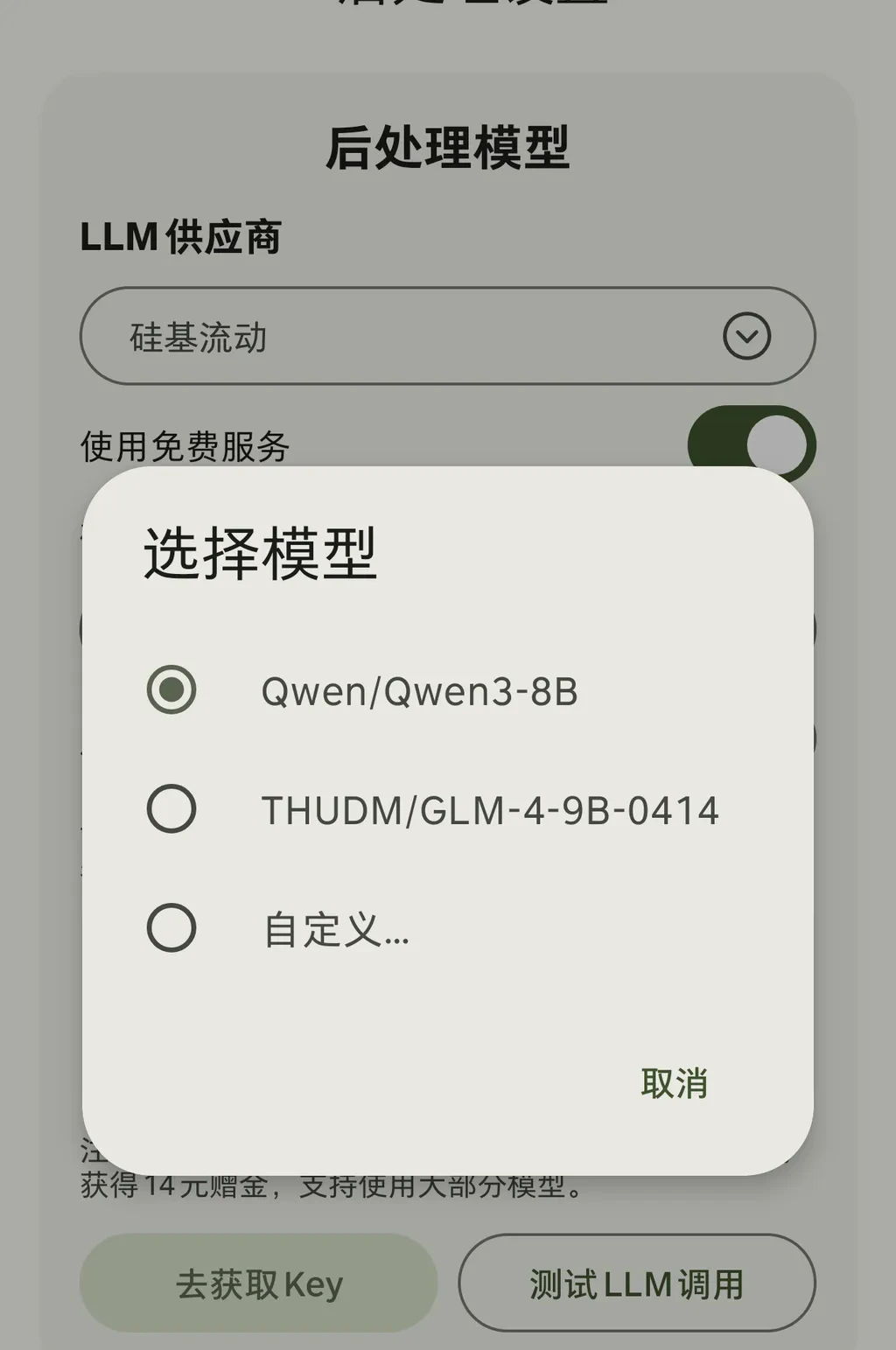
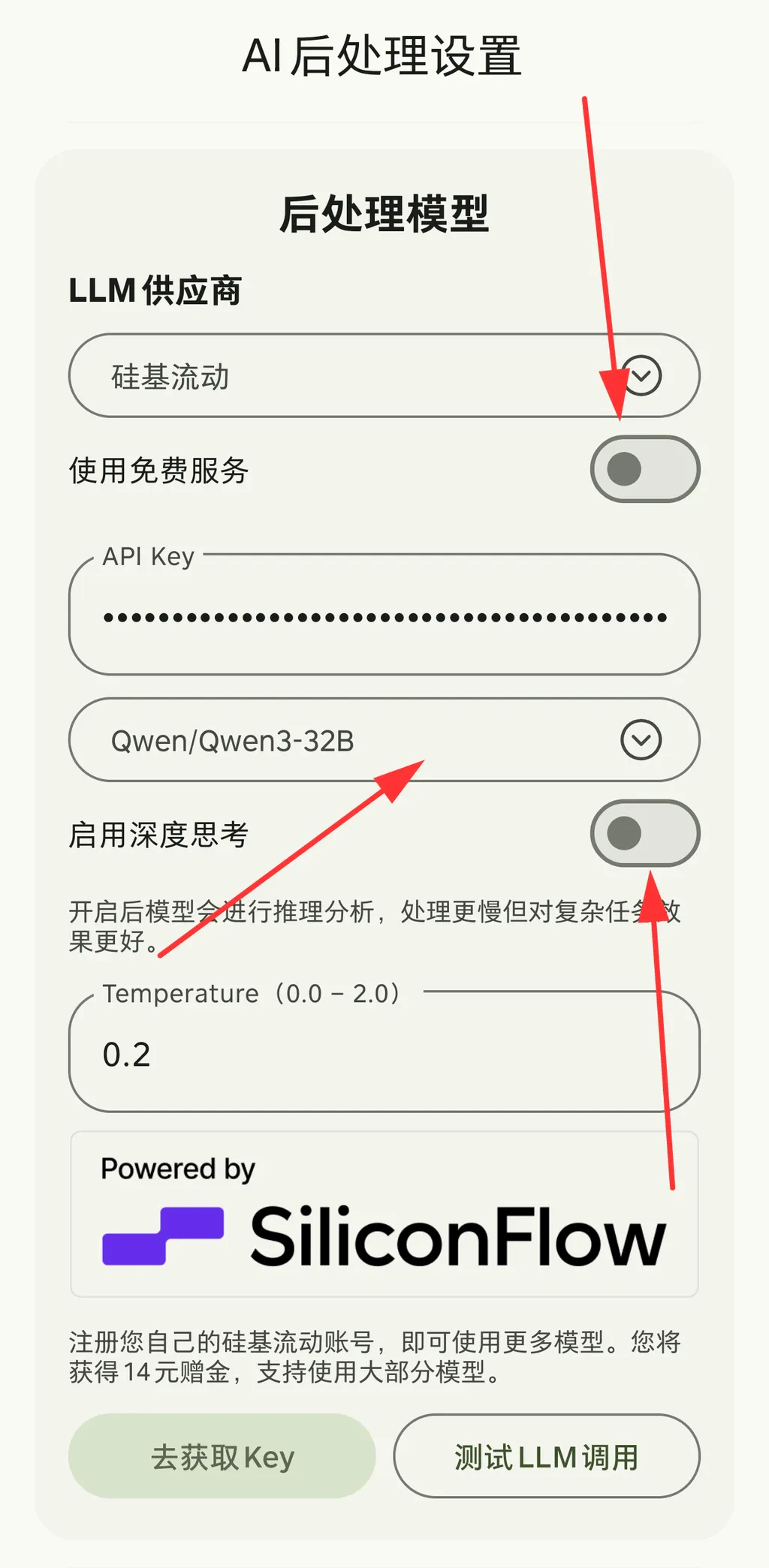
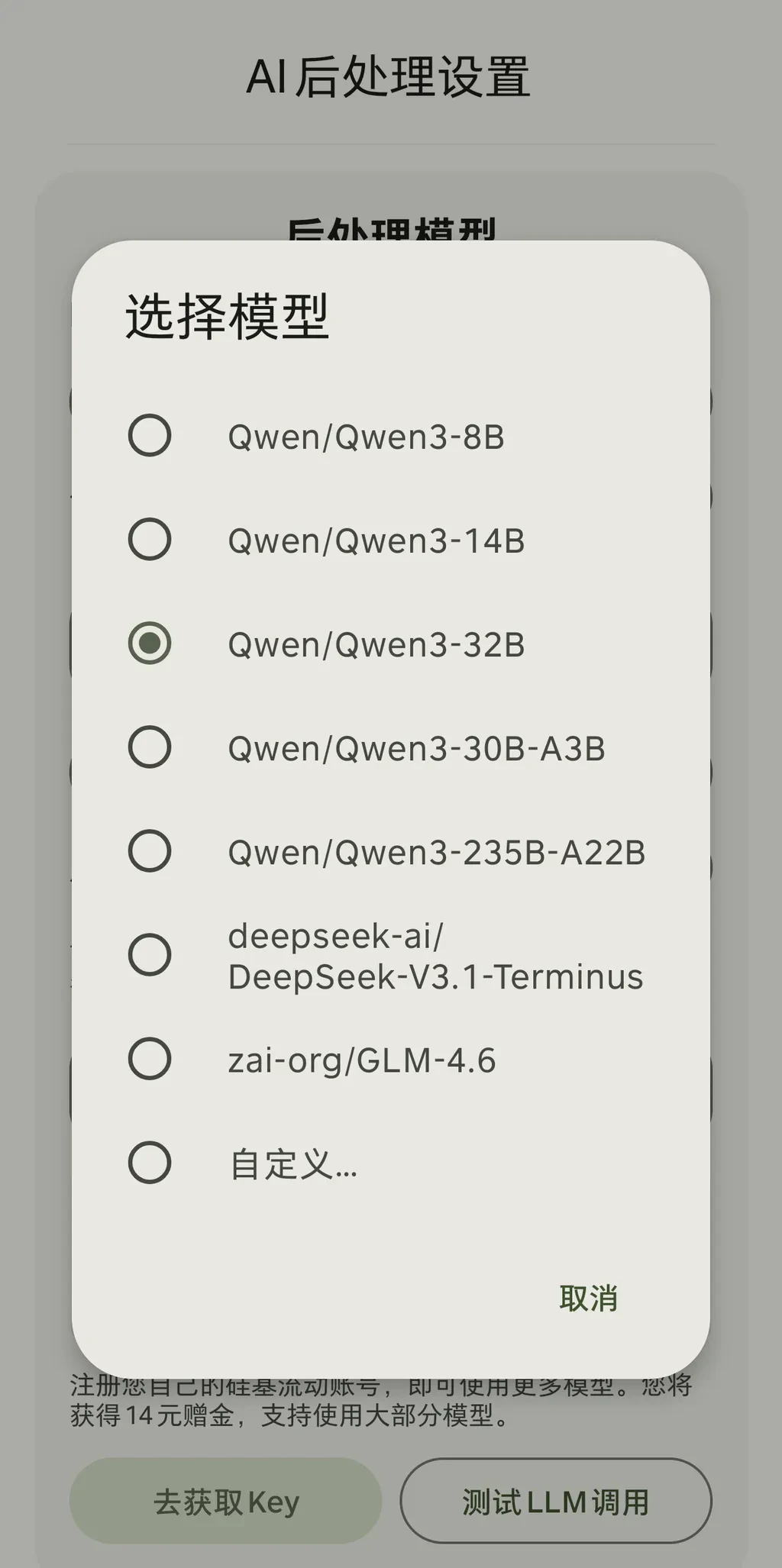
除了内置的已适配模型,还可以通过自定义选项填入其他模型ID。
部分模型支持深度思考模式切换开关,帮助用户在更快的响应速度和更好的处理效果之间选择。
使用示例
完成配置后,让我们测试一下语音识别是否正常工作:- 打开输入框
- 进行语音输入
- 确认当前输入法为说点啥
- 长按键盘上的麦克风按钮(大按钮),开始说话
- 说完后松开按钮,等待识别结果
- 查看结果
- 如果配置正确,识别结果会自动输入到文本框中
- 如果出现错误,报错信息会自动复制到粘贴板中,请检查:
- API Key 是否正确
- 网络连接是否正常
- 麦克风权限是否已授予
- 是否有语音输入(检查音量波形)