1. Introduction to Fine-tuning
Model fine-tuning is a technique that involves further training an existing pre-trained model using a specific task dataset. This allows the model to retain its general knowledge learned from large datasets while adapting to the nuances of specific tasks. The benefits of using fine-tuned models include:- Improved Performance: Fine-tuning can significantly enhance a model’s performance on specific tasks.
- Reduced Training Time: Fine-tuning typically requires less training time and computational resources compared to training from scratch.
- Adaptation to Specific Domains: Fine-tuning helps models better adapt to data and tasks specific to certain domains.
- Chat Models:
- Qwen/Qwen2.5-7B-Instruct
- Qwen/Qwen2.5-14B-Instruct
- Qwen/Qwen2.5-32B-Instruct
- Qwen/Qwen2.5-72B-Instruct
2. Usage Flow
2.1 Data Preparation
2.1.1 Data Preparation for Language Models
Only.jsonl files are supported, and they must meet the following requirements:
- Each line is an independent JSON object.
- Each object must contain an array with the key messages, and the array must not be empty.
- Each element in the messages array must contain role and content fields.
- role can only be system, user, or assistant.
- If there are system role messages, they must be at the beginning of the array.
- The first non-system message must be from the user role.
- user and assistant role messages should alternate and appear in pairs, with at least one pair.
2.2 Create and Configure Fine-Tuning Task
- Choose Chat Model Fine-Tuning or Image Generation Model Fine-Tuning
- Fill in the task name
- Select the base model
- Upload or select already uploaded training data
- Set validation data, which can be split from the training set (default 10%) or selected separately
- Configure training parameters
2.3 Start Training
- Click “Start Fine-Tuning”
- Wait for the task to complete
- Get the model identifier
2.4 Call Fine-Tuned Model
2.4.1 Calling Fine-Tuned Chat Model
- Copy the model identifier
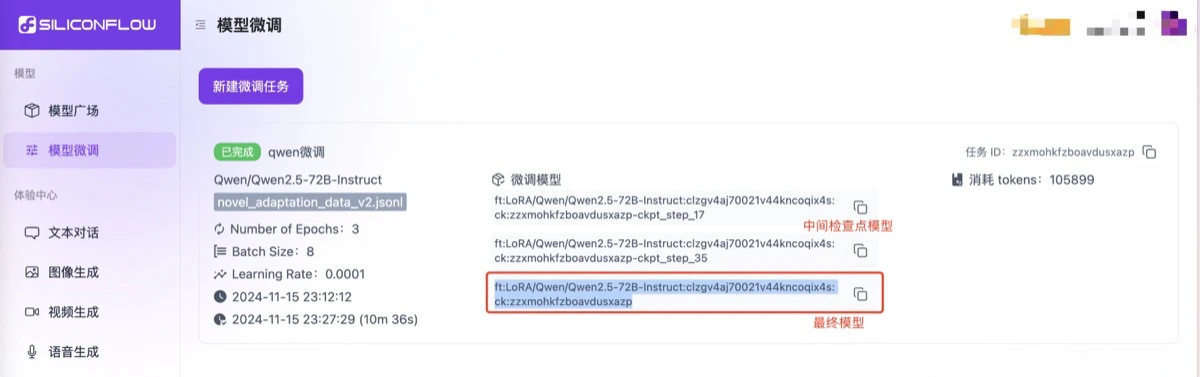
- Call the fine-tuned model directly through the
/chat/completionsAPI.
3. Detailed Configuration of Parameters
- Basic Training Parameters
- LoRA Parameters
- Scenario Configuration Scheme
4. Optimizing Business Practice with SiliconFlow Fine-Tuning Service
Previously, SiliconFlow developed the Zhi Shuo Xin Yu application, providing a complex prompt to let the large model generate “golden sentence” style descriptions. Now, we can use the platform’s fine-tuning function to compress the prompt and enhance the effect, making the text generation style more uniform, faster, and further optimizing costs.4.1 Fine-tune the data from the “Zhi Shuo Xin Yu” corpus on the platform
according to the above steps. See Model Fine-Tuning Usage Flow for details. Detailed corpus and test code can be found in siliconcloud-cookbook.4.2 Compare the effects before and after fine-tuning.
See Model Fine-Tuning Call Model for usage.4.2.1 Model Input
-
Before Fine-Tuning:
Qwen2.5-7B-Instruct System Prompt:
-
Qwen2.5-7B-Instruct+Zhi Shuo Xin Yu Fine-Tuned Prompt:
4.2.2 Model Output
4.2.3 Fine-Tuning Summary
- The output content after fine-tuning is more uniform in style, and the output effect is more stable and controllable.
- The entire input length is significantly reduced after fine-tuning, from 553 tokens to 8 tokens, greatly reducing the input token length, making it faster and further optimizing costs.