1. Model Core Capabilities
1.1 Basic Functions
Text Generation: Generate coherent natural language text based on context, supporting various styles and genres. Semantic Understanding: Deeply parse user intent, supporting multi-round dialogue management to ensure the coherence and accuracy of conversations. Knowledge Q&A: Cover a wide range of knowledge domains, including science, technology, culture, history, etc., providing accurate knowledge answers. Code Assistance: Support code generation, explanation, and debugging for multiple mainstream programming languages (such as Python, Java, C++, etc.).1.2 Advanced Capabilities
Long Text Processing: Support context windows of 4k to 64k tokens, suitable for long document generation and complex dialogue scenarios. Instruction Following: Precisely understand complex task instructions, such as “compare A/B schemes using a Markdown table.” Style Control: Adjust output style through system prompts, supporting various styles such as academic, conversational, and poetry. Multimodal Support: In addition to text generation, support tasks such as image description and speech-to-text.2. API Call Specifications
2.1 Basic Request Structure
You can make end-to-end API requests using the OpenAI SDKGenerate Dialogue (Click to View Details)
Generate Dialogue (Click to View Details)
Analyze an Image (Click to View Details)
Analyze an Image (Click to View Details)
Generate JSON Data (Click to View Details)
Generate JSON Data (Click to View Details)
2.2 Message Body Structure Description
When you want the model to follow layered instructions, message roles can help you get better outputs. However, they are not deterministic, so the best approach is to try different methods and see which one gives you the desired results.
3. Model Series Selection Guide
You can enter the Models and filter language models that support different functionalities using the filters on the left. Based on the model descriptions, you can understand the specific pricing, model parameter size, maximum context length supported by the model, and other details. You can experience the models in the playground (the playground only provides model experience and does not have a history record function. If you want to save the conversation records, please save the session content yourself). For more usage instructions, you can refer to the API Documentation.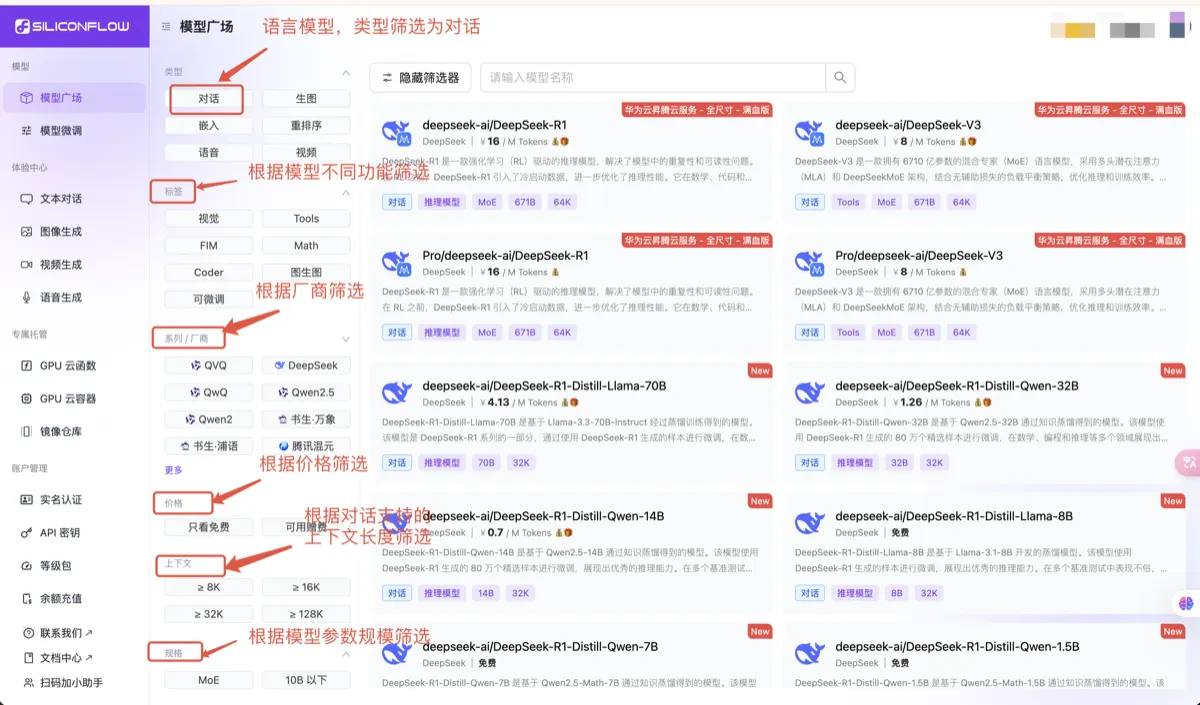
4.Detailed Explanation of Core Parameters
4.1 Creativity Control
4.2 Output Constraints
4.3 Summary of Language Model Scenarios
1. Model Output Encoding Issues Currently, some models are prone to encoding issues when parameters are not set. If you encounter such issues, you can try setting the temperature, top_k, top_p, and frequency_penalty parameters. Modify the payload as follows, adjusting as needed for different languages:- When encountering output truncation through API requests:
- Max Tokens Setting: Set the max_token to an appropriate value. If the output exceeds the max_token, it will be truncated.
- Stream Request Setting: In non-stream requests, long output content is prone to 504 timeout issues.
- Client Timeout Setting: Increase the client timeout to prevent truncation before the output is fully completed.
- When encountering output truncation through third-party client requests:
- CherryStdio has a default max_tokens of 4,096. Users can enable the “Enable Message Length Limit” switch to set the max_token to an appropriate value.
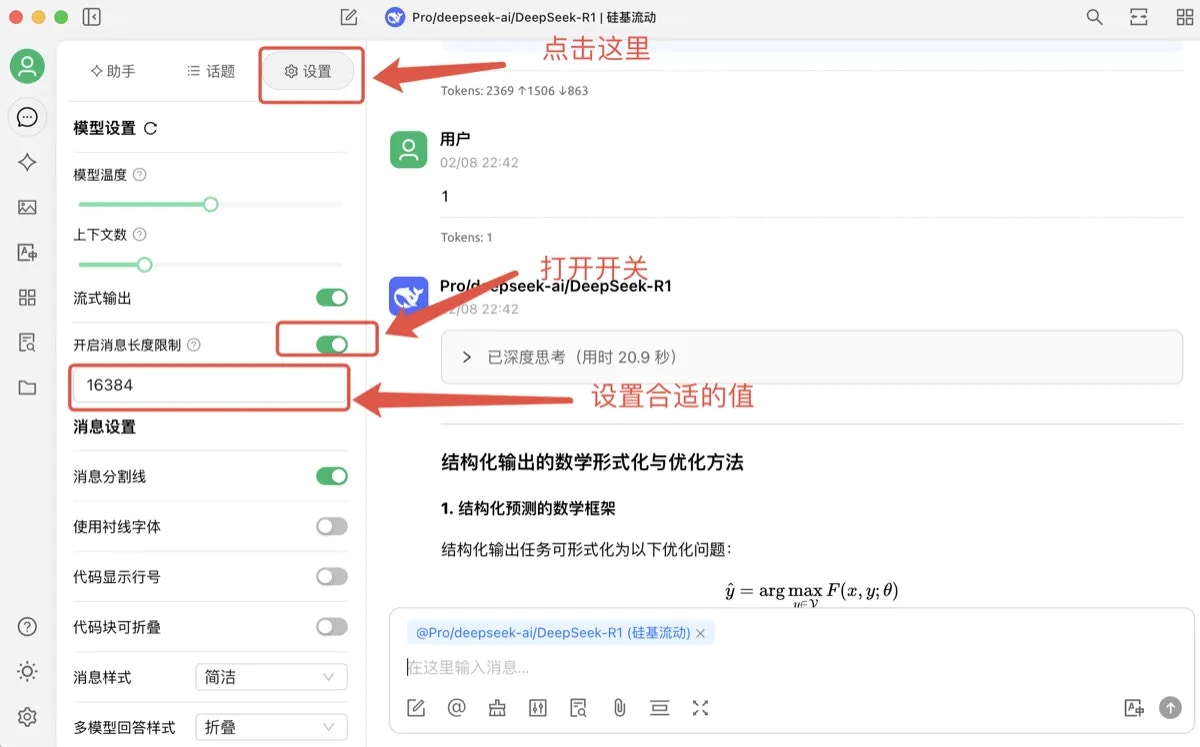
5. Billing and Quota Management
5.1 Billing Formula
Total Cost = (Input tokens × Input price) + (Output tokens × Output price)
5.2 Example Pricing for Each Series
The specific pricing for each model can be viewed on the Model Details Page in the Models.6. Case Studies
6.1 Technical Documentation Generation
6.2 Data Analysis Report
Model capabilities are continuously being updated. We recommend visiting the Models regularly to get the latest information.