1. 模型微调简介
模型微调是一种在已有预训练模型的基础上,通过使用特定任务的数据集进行进一步训练的技术。这种方法允许模型在保持其在大规模数据集上学到的通用知识的同时,适应特定任务的细微差别。使用微调模型,可以获得以下好处:- 提高性能:微调可以显著提高模型在特定任务上的性能。
- 减少训练时间:相比于从头开始训练模型,微调通常需要较少的训练时间和计算资源。
- 适应特定领域:微调可以帮助模型更好地适应特定领域的数据和任务。
- 对话模型已支持:
- Qwen/Qwen2.5-7B-Instruct
- Qwen/Qwen2.5-14B-Instruct
- Qwen/Qwen2.5-32B-Instruct
- Qwen/Qwen2.5-72B-Instruct
2. 使用流程
2.1 准备数据
2.2.1 语言模型数据准备
仅支持.jsonl 文件,且需符合以下要求:
- 每行是一个独立的
JSON对象; - 每个对象必须包含键名为
messages的数组,数组不能为空; messages中每个元素必须包含role和content两个字段;role只能是system、user或assistant;- 如果有
system角色消息,必须在数组首位; - 第一条非
system消息必须是user角色; user和assistant角色的消息应当交替、成对出现,不少于1对
2.2 新建并配置微调任务
- 选择
对话模型微调或者生图模型微调 - 填写任务名称
- 选择基础模型
- 上传或选取已上传的训练数据
- 设置验证数据,支持训练集按比例切分(默认 10%),或单独选定验证集
- 配置训练参数
2.3 开始训练
- 点击”开始微调”
- 等待任务完成
- 获取模型标识符
2.4 调用微调模型
2.4.1 对话微调模型调用
- 复制模型标识符 在模型微调页复制对应的模型标识符。
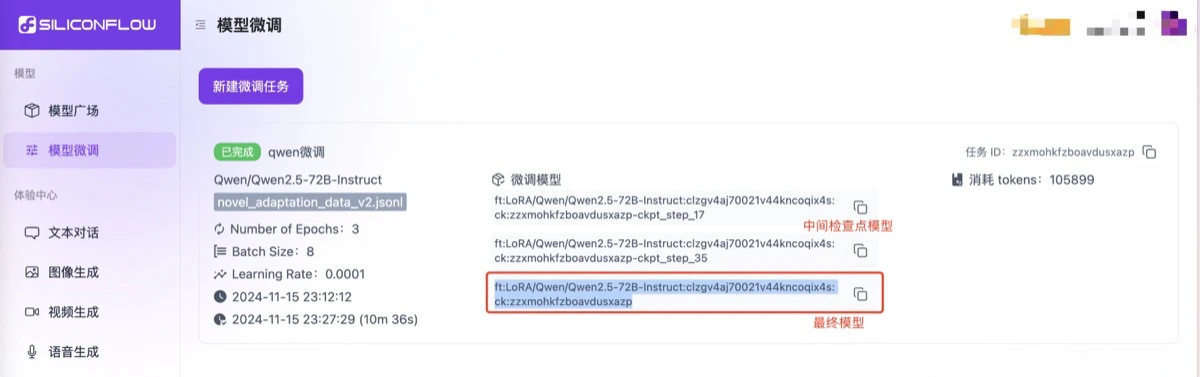
- 通过
/chat/completionsAPI 即可直接调用微调后的模型
3. 参数配置详解
- 基础训练参数
- LoRA参数
- 场景化配置方案
4. 基于SiliconFlow微调服务来优化业务实战
之前硅基流动开发了智说新语应用,我们通过提示词工程提供一个复杂的提示词来让大模型生成“金句”风格的描述语句。 现在,我们可通过平台的微调功能来压缩提示词并提升效果,让整个的文本生成风格更统一,速度更快,且进一步优化成本。4.1 在平台上使用“智说新语”的语料按照上述进行微调。
步骤见模型微调使用流程详细语料和测试代码见siliconcloud-cookbook
4.2 对比微调前后的效果
使用方式见模型微调调用模型4.2.1 模型输入
-
微调前:
Qwen2.5-7B-Instruct 系统Prompt:
-
Qwen2.5-7B-Instruct+智说新语微调后的Prompt:
4.2.2 模型输出
4.2.3 微调总结
- 微调后的输出内容风格更统一,输出效果更稳定可控。
- 微调后整个输入长度大大降低,从原始的553个token,降低至8个token,显著降低了输入tokens长度,速度更快,成本得以进一步优化。