1. 模型核心能力
1.1 基础功能
文本生成:根据上下文生成连贯的自然语言文本,支持多种文体和风格。 语义理解:深入解析用户意图,支持多轮对话管理,确保对话的连贯性和准确性。 知识问答:覆盖广泛的知识领域,包括科学、技术、文化、历史等,提供准确的知识解答。 代码辅助:支持多种主流编程语言(如Python、Java、C++等)的代码生成、解释和调试。1.2 进阶能力
长文本处理:支持4k至64k tokens的上下文窗口,适用于长篇文档生成和复杂对话场景。 指令跟随:精确理解复杂任务指令,如“用Markdown表格对比A/B方案”。 风格控制:通过系统提示词调整输出风格,支持学术、口语、诗歌等多种风格。 多模态支持:除了文本生成,还支持图像描述、语音转文字等多模态任务。2. 接口调用规范
2.1 基础请求结构
您可以通过 openai sdk进行端到端接口请求生成对话(点击查看详情)
生成对话(点击查看详情)
分析一幅图像(点击查看详情)
分析一幅图像(点击查看详情)
生成json数据(点击查看详情)
生成json数据(点击查看详情)
2.2 消息体结构说明
你想让模型遵循分层指令时,消息角色可以帮助你获得更好的输出。但它们并不是确定性的,所以使用的最佳方式是尝试不同的方法,看看哪种方法能给你带来好的结果。
3. 模型系列选型指南
可以进入模型广场,根据左侧的筛选功能,筛选支持不同功能的语言模型,根据模型的介绍,了解模型具体的价格、模型参数大小、模型上下文支持的最大长度及模型价格等内容。 支持在playground进行体验(playground只进行模型体验,暂时没有历史记录功能,如果您想要保存历史的回话记录内容,请自己保存会话内容),想要了解更多使用方式,可以参考API文档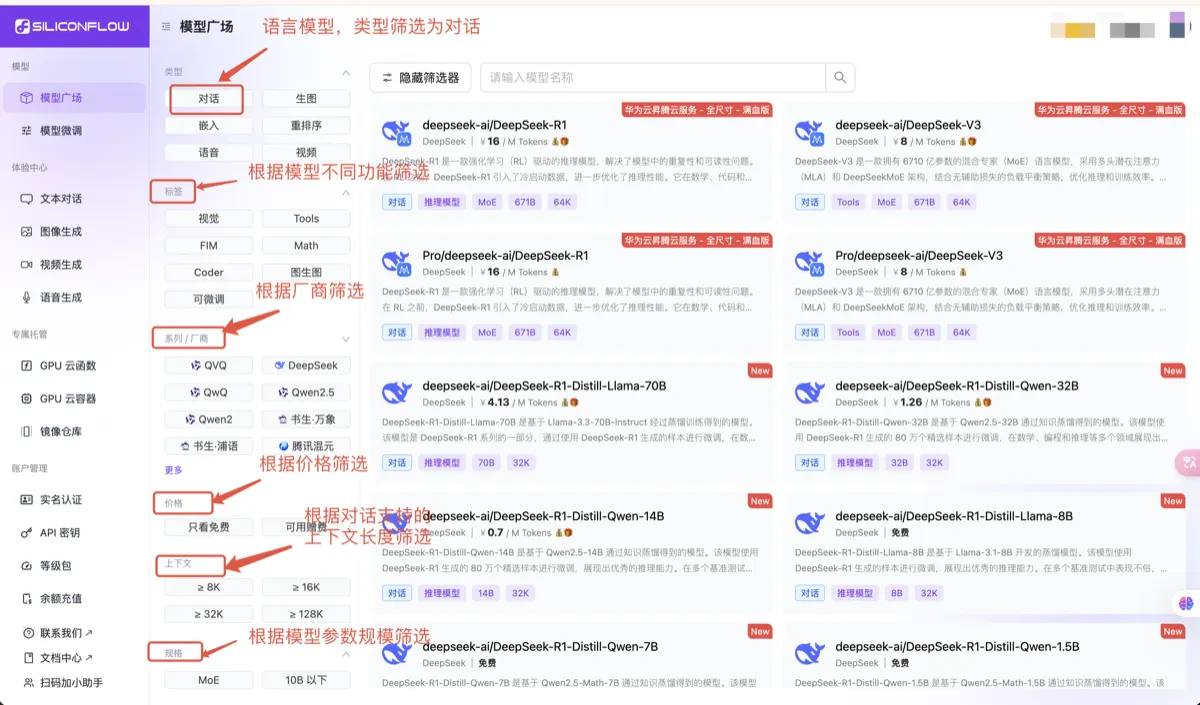
4. 核心参数详解
4.1 创造性控制
4.2 输出限制
4.3 语言模型场景问题汇总
1. 模型输出乱码 目前看到部分模型在不设置参数的情况下,容易出现乱码,遇到上述情况,可以尝试设置temperature,top_k,top_p,frequency_penalty这些参数。
对应的 payload 修改为如下形式,不同语言酌情调整
max_tokens说明
max_tokens 与上下文长度相等,由于部分模型推理服务尚在更新中,请不要在请求时将 max_tokens 设置为最大值(上下文长度),建议留出 10k 左右作为输入内容的空间。
3. 关于context_length说明
不同的LLM模型,context_length是有差别的,具体可以在模型广场上搜索对应的模型,
查看模型具体信息。
4. 模型输出截断问题
可以从以下几方面进行问题的排查:
- 通过API请求时候,输出截断问题排查:
- max_tokens设置:max_token设置到合适值,输出大于max_token的情况下,会被截断。
- 设置流式输出请求:非流式请求时候,输出内容比较长的情况下,容易出现504超时。
- 设置客户端超时时间:把客户端超时时间设置大一些,防止未输出完成,达到客户端超时时间被截断。
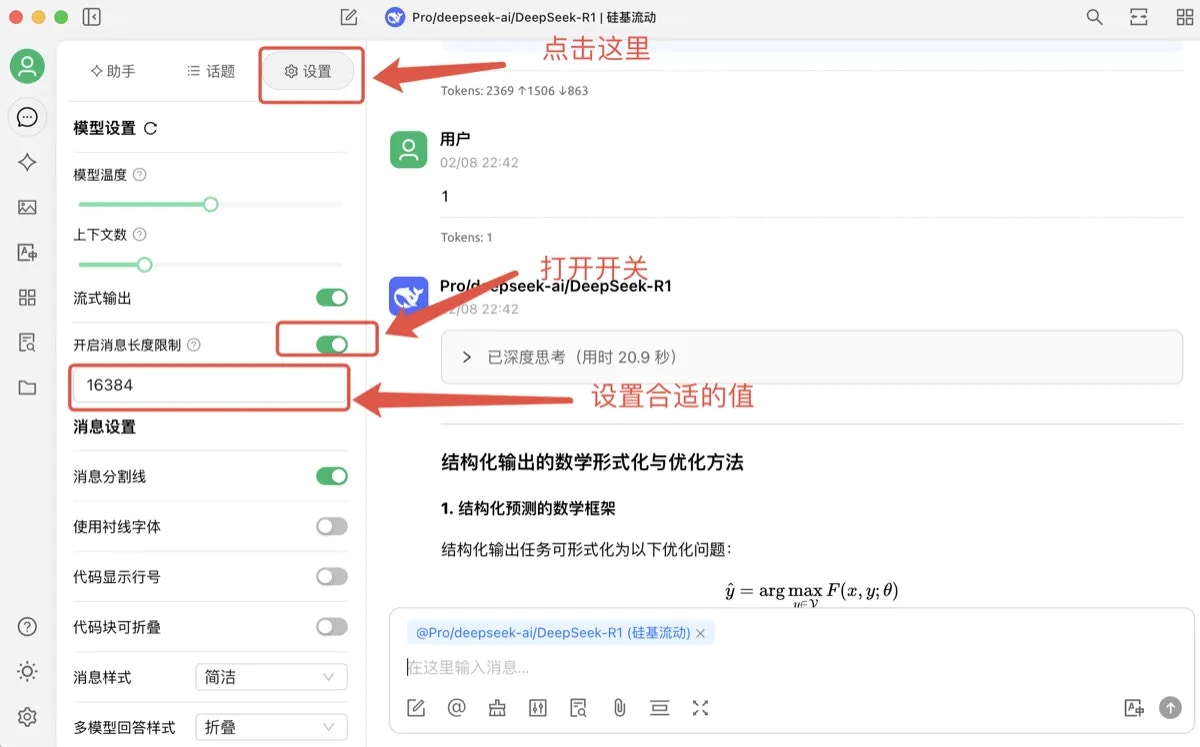
- 通过第三方客户端请求,输出截断问题排查:
- CherryStdio 默认的 max_tokens 是 4096,用户可以通过设置,打开“开启消息长度限制”的开关,将max_token设置到合适值
6. x-siliconcloud-trace-id
响应头(Response Headers)
说明
- x-siliconcloud-trace-id 是一个全局唯一的字符串,通常以 UUID 格式生成。
- 客户端可以在调试或排查问题时,将该 x-siliconcloud-trace-id 提供给后端开发人员,以便快速定位请求链路中的日志信息。
- 此字段由服务端自动生成并返回,客户端无需主动设置
5. 计费与配额管理
5.1 计费公式
总费用 = (输入tokens × 输入单价) + (输出tokens × 输出单价)
5.2 支持模型列表及单价
支持的模型及具体价格可以进入模型广场下的模型详情页查看。6. 应用案例
6.1 技术文档生成
6.2 数据分析报告
模型能力持续更新中,建议定期访问模型广场获取最新信息。