1.关于 DB-GPT
DB-GPT 是一个开源的AI原生数据应用开发框架(AI Native Data App Development framework with AWEL(Agentic Workflow Expression Language) and Agents)。 目的是构建大模型领域的基础设施,通过开发多模型管理(SMMF)、Text2SQL效果优化、RAG框架以及优化、Multi-Agents框架协作、AWEL(智能体工作流编排)等多种技术能力,让围绕数据库构建大模型应用更简单,更方便。2.获取 API Key
2.1 打开 SiliconFlow 官网 并注册账号(如果注册过,直接登录即可)。 2.2 完成注册后,打开API密钥 ,创建新的 API Key,点击密钥进行复制,以备后续使用。3.部署 DB-GPT
3.1 克隆 DB-GPT 源码
3.2 创建虚拟环境并安装依赖
3.3 配置基础的环境变量
3.4 修改环境变量文件.env,配置 SiliconFlow 模型
SILICONFLOW_API_KEY、 PROXY_HTTP_OPENAPI_PROXY_SERVER_URL 和RERANK_PROXY_SILICONFLOW_PROXY_API_KEY环境变量是您在步骤 2 中获取的 SiliconFlow 的 Api Key。语言模型(SILICONFLOW_MODEL_VERSION)、 Embedding 模型(PROXY_HTTP_OPENAPI_PROXY_BACKEND)和 rerank 模型(RERANK_PROXY_SILICONFLOW_PROXY_BACKEND) 可以从 获取用户模型列表 - SiliconFlow 中获取。
3.5 启动 DB-GPT 服务
4.通过 DB-GPT Python SDK 使用 SiliconFlow 的模型
4.1 安装 DB-GPT Python 包
4.2. 使用 SiliconFlow 的大语言模型
4.3 使用 SiliconFlow 的 Embedding 模型
4.4 使用 SiliconFlow 的 rerank 模型
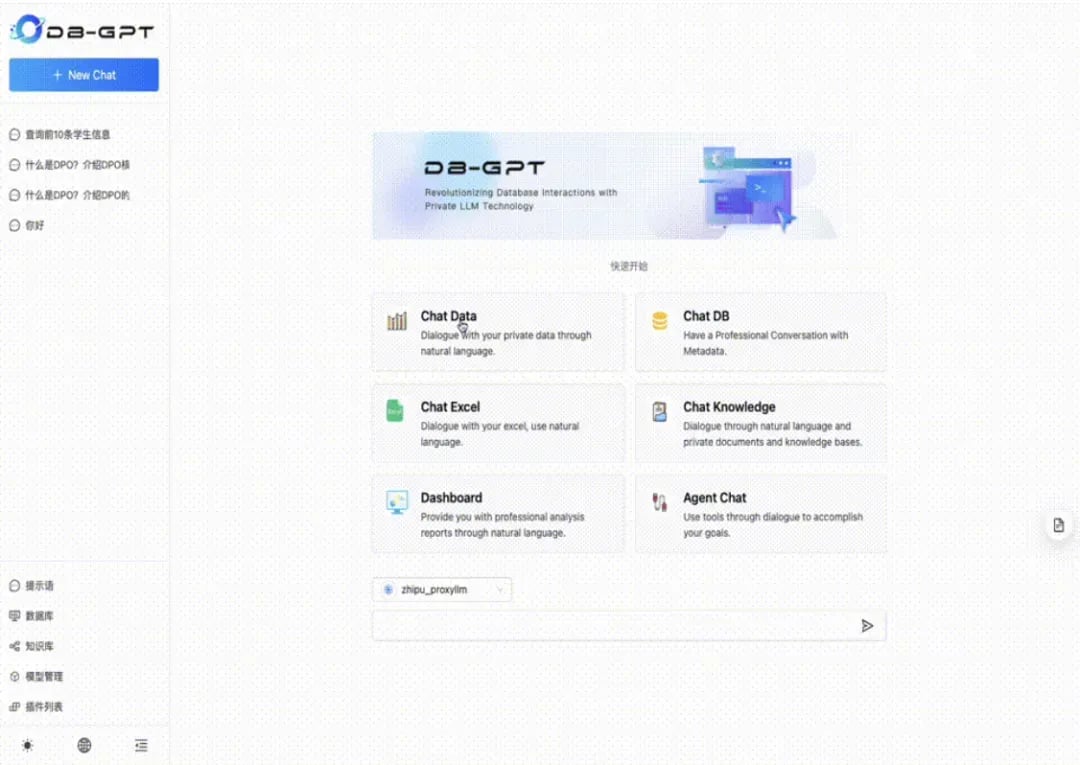
5. 上手指南
以数据对话案例为例,数据对话能力是通过自然语言与数据进行对话,目前主要是结构化与半结构化数据的对话,可以辅助做数据分析与洞察。以下为具体操作流程:1. 添加数据源
首先选择左侧数据源添加,添加数据库,目前DB-GPT支持多种数据库类型。选择对应的数据库类型添加即可。这里我们选择的是MySQL作为演示,演示的测试数据参见测试样例(https://github.com/eosphoros-ai/DB-GPT/tree/main/docker/examples/sqls)。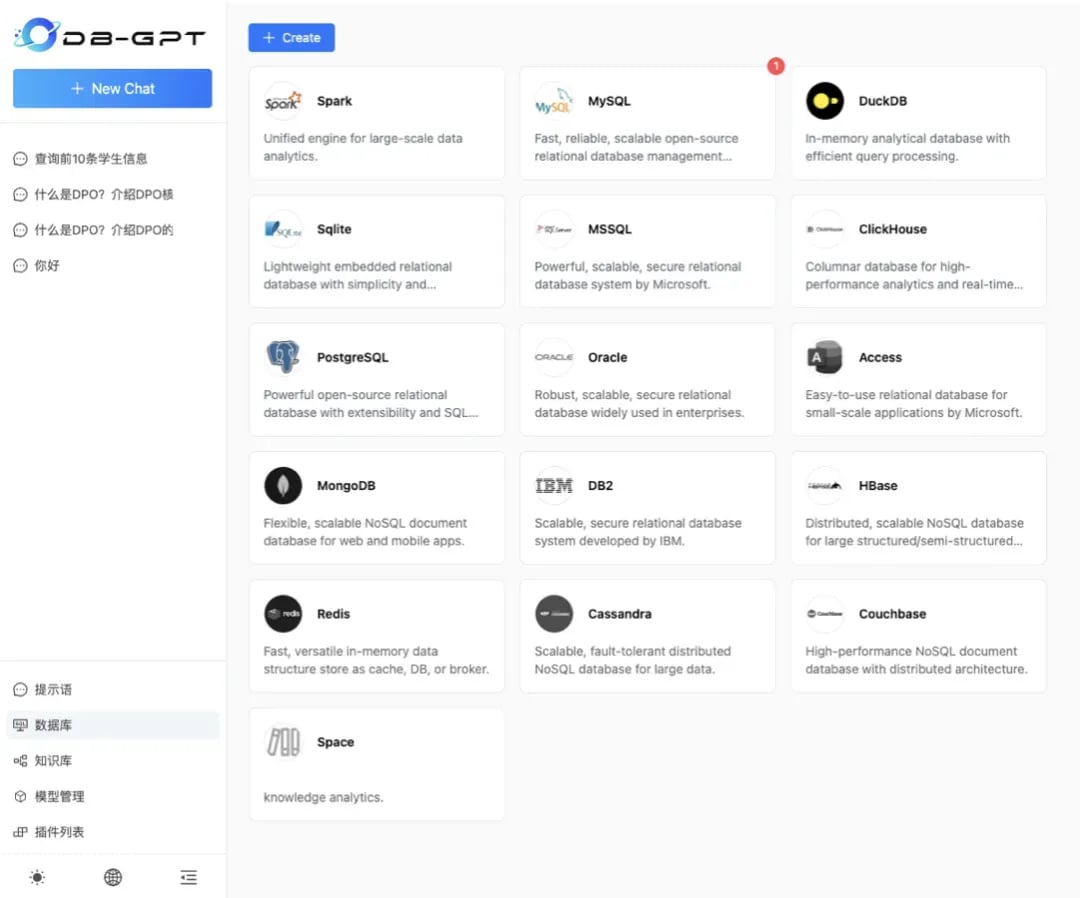
2. 选择对话类型
选择ChatData对话类型。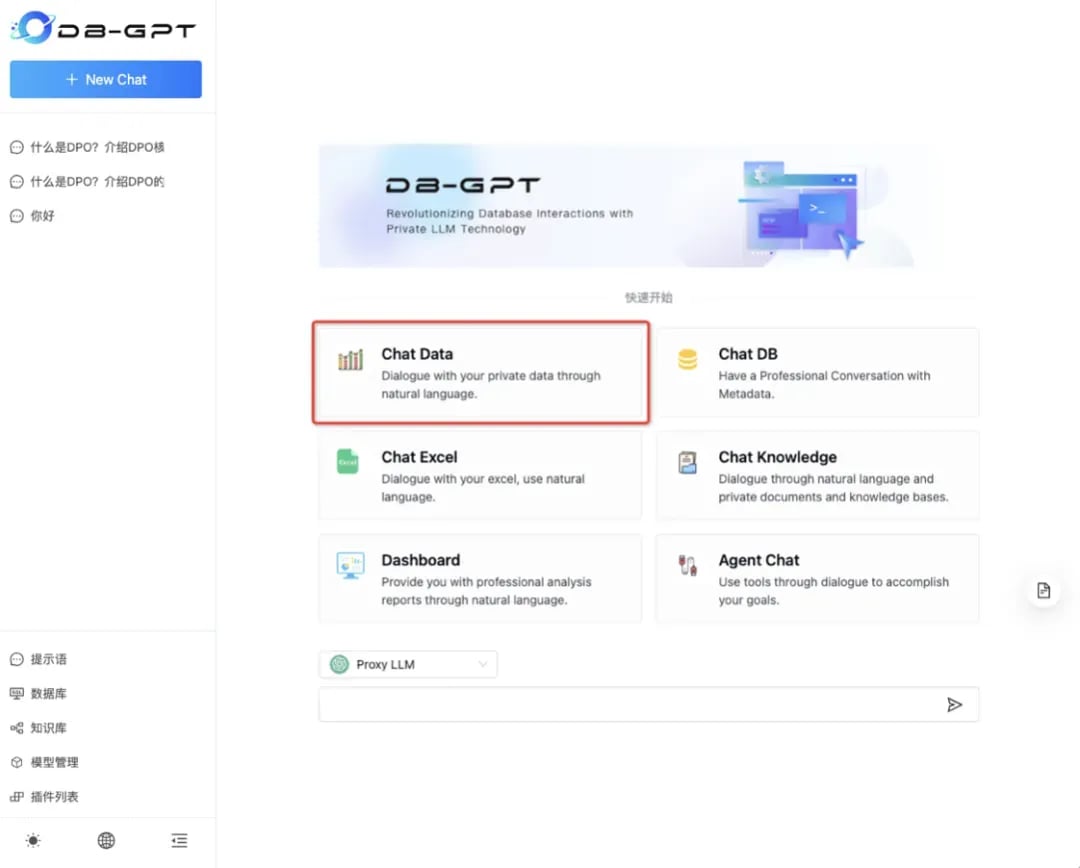
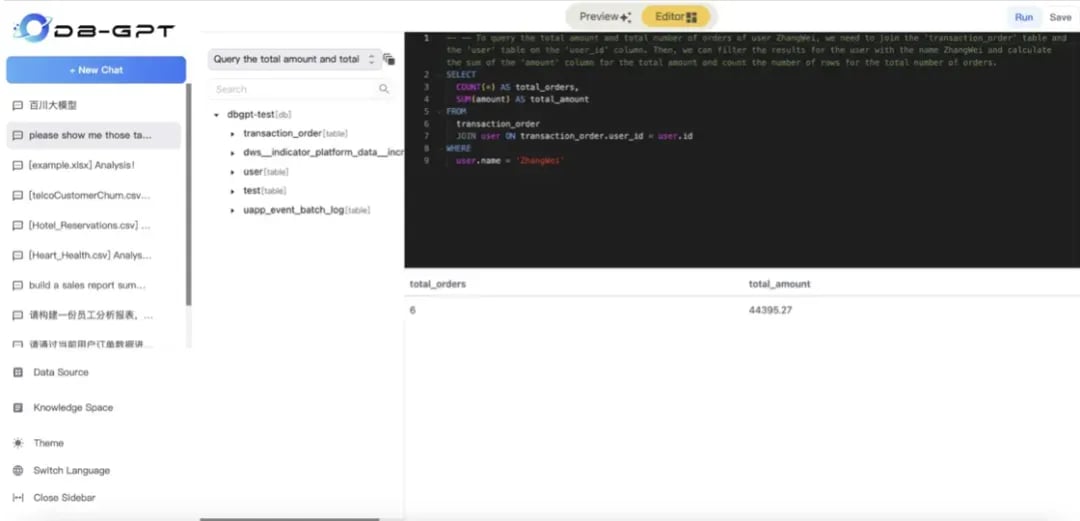
3. 开始数据对话
注意:在对话时,选择对应的模型与数据库。同时DB-GPT也提供了预览模式与编辑模式。