1. 模型输出乱码
目前看到部分模型在不设置参数的情况下,容易出现乱码,遇到上述情况,可以尝试设置temperature,top_k,top_p,frequency_penalty这些参数。
对应的 payload 修改为如下形式,不同语言酌情调整
2. 关于max_tokens说明
max_tokens 与上下文长度相等,由于部分模型推理服务尚在更新中,请不要在请求时将 max_tokens 设置为最大值(上下文长度),建议留出 10k 左右作为输入内容的空间。
3. 关于context_length说明
不同的LLM模型,context_length是有差别的,具体可以在模型广场上搜索对应的模型,查看模型具体信息。
4. Pro 和非 Pro 模型有什么区别
- 对于部分模型,平台同时提供免费版和收费版。免费版按原名称命名;收费版在名称前加上“Pro/”以示区分。免费版的 Rate Limits 固定,收费版的 Rate Limits 可变,具体规则请参考:Rate Limits。
-
对于
DeepSeek R1和DeepSeek V3模型,平台根据支付方式的不同要求区分命名。Pro 版仅支持充值余额支付,非 Pro 版支持赠费余额和充值余额支付。
5. 语音模型中,对用户自定义音色有时间音质要求么
- cosyvoice2 上传音色必须小于30s
6. 模型输出截断问题
可以从以下几方面进行问题的排查:- 通过API请求时候,输出截断问题排查:
- max_tokens设置:max_token设置到合适值,输出大于max_token的情况下,会被截断。
- 设置流式输出请求:非流式请求时候,输出内容比较长的情况下,容易出现504超时。
- 设置客户端超时时间:把客户端超时时间设置大一些,防止未输出完成,达到客户端超时时间被截断。
- 通过第三方客户端请求,输出截断问题排查:
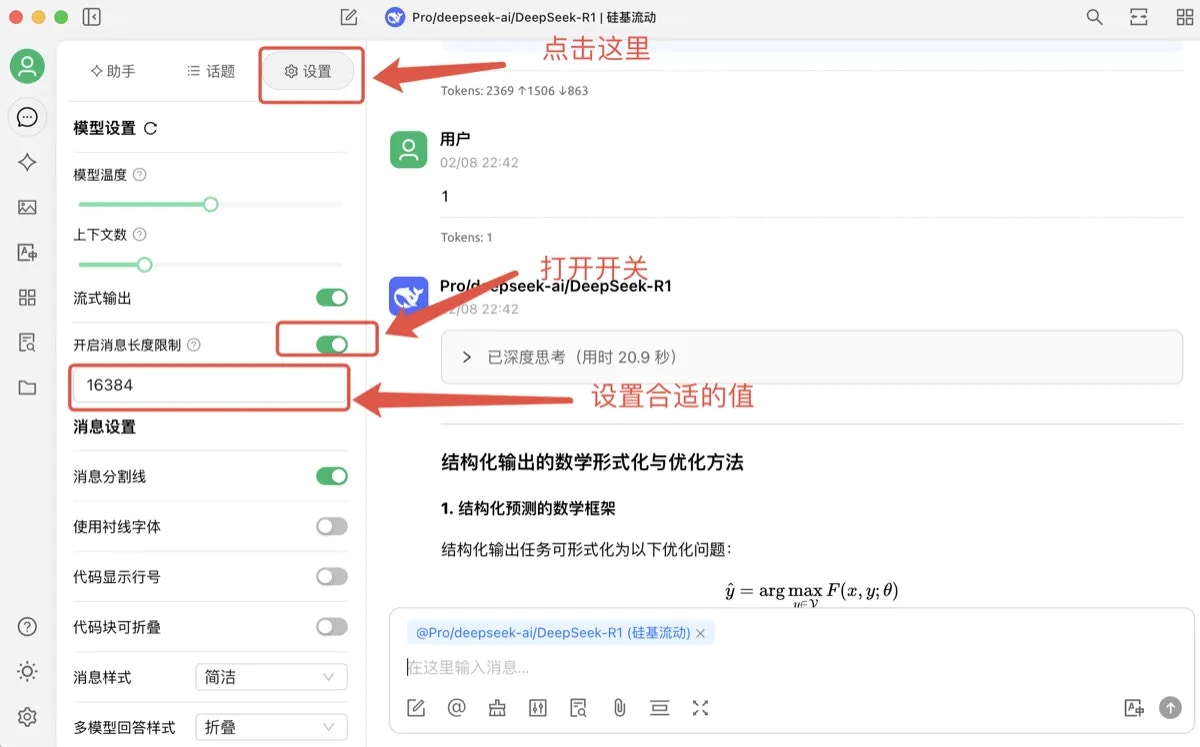
- CherryStdio 默认的 max_tokens 是 4096,用户可以通过设置,打开“开启消息长度限制”的开关,将max_token设置到合适值
7. 模型使用过程中返回429错误排查
可以从以下几方面进行问题的排查:- 普通用户:检查用户等级及模型对应的 Rate Limits(速率限制)。如果请求超出 Rate Limits,建议稍后再尝试请求。
- 专属实例用户:专属实例通常没有 Rate Limits 限制。如果出现 429 错误,首先确认是否调用了专属实例的正确模型名称,并检查使用的 api_key 是否与专属实例匹配。
8. 已充值成功,仍然提示账户余额不足
可以从以下几方面进行问题的排查:- 确认使用的 api_key 是否与刚刚充值的账户匹配。
- 如果 api_key 无误,可能是充值过程中存在网络延迟,建议等待几分钟后再重试。
9. 已实名认证,还是无法访问部分模型
可以从以下几方面进行问题的排查:- 确认使用的 api_key 是否与刚刚完成实名认证的账户匹配。
- 如果 api_key 无误,可以进入实名认证页面,检查认证状态。如果状态显示为“认证中”,可以尝试取消并重新进行认证。
10. fnlp/MOSS-TTSD-v0.5 使用问题
- 该模型输入的文字过短时候,容易出现错误
- 使用该模型进行对话合成时,输入文案格式如下:
- [S1]发言人1说话内容。[S2]发言人2说话内容。
如遇其他问题,请点击硅基流动MaaS线上需求收集表反馈。