# 创建语音转文本请求
Source: https://docs.siliconflow.cn/cn/api-reference/audio/create-audio-transcriptions
post /audio/transcriptions
Creates an audio transcription.
# 创建文本转语音请求
Source: https://docs.siliconflow.cn/cn/api-reference/audio/create-speech
post /audio/speech
Generate audio from input text. The data generated by the interface is the binary data of the audio, which requires the user to handle it themselves. Reference:https://docs.siliconflow.cn/capabilities/text-to-speech#5
# 删除参考音频
Source: https://docs.siliconflow.cn/cn/api-reference/audio/delete-voice
post /audio/voice/deletions
Delete user-defined voice style
# 上传参考音频
Source: https://docs.siliconflow.cn/cn/api-reference/audio/upload-voice
post /uploads/audio/voice
Upload user-provided voice style, which can be in base64 encoding or file format. Refer to (https://docs.siliconflow.cn/capabilities/text-to-speech#2-2)
# 参考音频列表获取
Source: https://docs.siliconflow.cn/cn/api-reference/audio/voice-list
get /audio/voice/list
Get list of user-defined voice styles
# 取消batch任务
Source: https://docs.siliconflow.cn/cn/api-reference/batch/cancel-batch
post /batches/{batch_id}/cancel
This endpoint cancels a batch identified by its unique ID.
# 创建batch任务
Source: https://docs.siliconflow.cn/cn/api-reference/batch/create-batch
post /batches
Upload files
# 获取batch任务详情
Source: https://docs.siliconflow.cn/cn/api-reference/batch/get-batch
get /batches/{batch_id}
Retrieves a batch.
# 获取batch任务列表
Source: https://docs.siliconflow.cn/cn/api-reference/batch/get-batch-list
get /batches
List your organization's batches.
# 获取文件列表
Source: https://docs.siliconflow.cn/cn/api-reference/batch/get-file-list
get /files
Returns a list of files.
# 上传文件
Source: https://docs.siliconflow.cn/cn/api-reference/batch/upload-file
post /files
Upload files
# 创建文本对话请求
Source: https://docs.siliconflow.cn/cn/api-reference/chat-completions/chat-completions
post /chat/completions
Creates a model response for the given chat conversation.
# 创建嵌入请求
Source: https://docs.siliconflow.cn/cn/api-reference/embeddings/create-embeddings
post /embeddings
Creates an embedding vector representing the input text.
# 创建图片生成请求
Source: https://docs.siliconflow.cn/cn/api-reference/images/images-generations
post /images/generations
Creates an image response for the given prompt. The URL for the generated image is valid for one hour. Please make sure to download and store it promptly to avoid any issues due to URL expiration.
# 获取用户模型列表
Source: https://docs.siliconflow.cn/cn/api-reference/models/get-model-list
get /models
Retrieve models information.
# 创建重排序请求
Source: https://docs.siliconflow.cn/cn/api-reference/rerank/create-rerank
post /rerank
Creates a rerank request.
# 获取用户账户信息
Source: https://docs.siliconflow.cn/cn/api-reference/userinfo/get-user-info
get /user/info
Get user information including balance and status
# 获取视频生成链接请求
Source: https://docs.siliconflow.cn/cn/api-reference/videos/get_videos_status
post /video/status
Get the user-generated video. The URL for the generated video is valid for one hour. Please make sure to download and store it promptly to avoid any issues due to URL expiration.
# 创建视频生成请求
Source: https://docs.siliconflow.cn/cn/api-reference/videos/videos_submit
post /video/submit
Generate a video through the input prompt. This API returns the user's current request ID. The user needs to poll the status interface to get the specific video link. The generated result is valid for 10 minutes, so please retrieve the video link promptly.
# 实名认证
Source: https://docs.siliconflow.cn/cn/faqs/authentication
## 1. 为什么要进行实名认证?
《中华人民共和国网络安全法》 等法律法规要求:网络运营者为用户办理网络接入,在与用户签订协议或者确认提供服务时,应当要求用户提供真实身份信息。用户不提供真实身份信息的,网络运营者不得为其提供相关服务。
## 2. 如果不进行实名认证,会对账号产生什么影响?
如果不进行实名认证,账号将无法进行以下操作:
* 无法进行“账户充值”
* 无法申请“开具发票”
## 3. 个人实名和企业实名认证有哪些区别?
账号实名认证分为**个人实名认证**和**企业实名认证**两类:
* 个人实名认证:认证类型为个人,支持个人人脸识别认证。
* 企业实名认证:认证类型为企业(含普通企业、政府、事业单位、社会团体组织、个体工商户等),支持法人人脸识别认证、企业对公打款认证两种认证方式。
**实名认证类型对账号的影响:**
1. 影响账号的归属。
* 完成企业实名认证的账号**归属为企业**。
* 完成个人实名认证的账号**归属于个人**。
2. 影响账号的开票信息。
* 企业认证**可以开具企业抬头的增值税专用发票、增值税普通发票**。
* 个人认证**只能开具**个人抬头的增值税普通发票\*\*。
【注意事项】
* 实名认证信息对您的账号和资金安全等很重要,请**按实际情况**进行实名认证。
* 为了您的账号安全,企业用户不要进行个人实名认证。
* 当前账号只允许绑定一个认证主体,账号主体变更成功后原主体信息将与账号解绑。
## 4. 如何进行个人认证?
### 4.1 个人认证支持证件类型
个人认证支持证件类型有以下几种:
* 大陆身份证
* 港澳往来大陆通行证(回乡证)
* 台湾往来大陆通行证(台胞证)
* 港澳居民居住证
* 台湾居民居住证
* 外国人永久居留证
不具有以上证件的用户,暂时不支持线上个人认证,可以通过提交[表单](https://siliconflow.feishu.cn/share/base/form/shrcnF4a7pFS2eR4wJj9rneM7mc?auth_token=U7CK1RF-ddcuca83-7f21-437e-9ef2-208b950e9f7f-NN5W4\&ccm_open_type=form_v1_qrcode_share\&share_link_type=qrcode)的形式跟工作人员沟通,尝试进行其他方式认证。
### 4.2 个人认证流程
1. 登录 SiliconCloud 平台,点击[用户中心-实名认证](https://cloud.siliconflow.cn/account/authentication)。
2. 在实名认证页面,选择认证类型为"个人实名认证",然后填写个人信息。
3. 使用手机支付宝 App 扫描二维码,扫描后按照手机上的提示完成人脸识别认证,认证成功后,在网页端的弹窗上点击“已完成刷脸认证”。
 4. 认证成功后您可以**修改认证信息**或者**变更为企业用户**,30 天内只可以完成一次变更或修改。
【注意事项】
* 实名认证直接影响账号的归属。如果是企业用户,请您进行企业实名认证,以免人员变动等因素引起的不必要纠纷。更多信息请参见个人实名认证和企业实名认证的区别。
* 根据相关法律法规,我们不对未满 14 周岁的个人提供在线实名认证服务。
## 5. 如何进行企业认证?
1. 登录 SiliconCloud 平台,点击“用户中心-实名认证”。
2. 在实名认证页面,选择认证类型为“企业实名认证”,然后选择认证方式。认证方式有以下两种:
* 选择法人人脸识别认证
1. 填写企业名称、统一社会信用代码、法人姓名和法人身份证号,勾选同意协议。
2. 法人使用手机支付宝 App 扫描二维码,扫描后按照手机上的提示完成人脸认证,验证成功即可完成认证。
* 选择企业对公打款认证
1. 填写企业名称、统一社会信用代码和法人姓名,勾选同意协议。
2. 填写企业对公银行卡号,填写对公银行(精确到支行)名称,选择具体的开户行,确认无误后点击获取验证金额。
3. 等待随机打款金额到账,通常在 10 分钟以内。
4. 打款成功后,请跟财务核实收到的 1 元以下随机金额,将该金额回填到该页面,核实无误后即可认证成功。
认证成功后您可以**修改认证信息**,30 天内只可进行一次修改。
# 错误处理
Source: https://docs.siliconflow.cn/cn/faqs/error-code
**1. 尝试获取 HTTP 错误代码,初步定位问题**
a. 在代码中,尽量把错误码和报错信息(message)打印出来,利用这些信息,可以定位大部分问题。
```shell
HTTP/1.1 400 Bad Request
Date: Thu, 19 Dec 2024 08:39:19 GMT
Content-Type: application/json; charset=utf-8
Content-Length: 87
Connection: keep-alive
{"code":20012,"message":"Model does not exist. Please check it carefully.","data":null}
```
* 常见错误代码及原因:
* **400**:参数不正确,请参考报错信息(message)修正不合法的请求参数;
* **401**:API Key 没有正确设置;
* **403**:权限不够,最常见的原因是该模型需要实名认证,其他情况参考报错信息(message);
* **429**:触发了 rate limits;参考报错信息(message)判断触发的是 `RPM /RPD / TPM / TPD / IPM / IPD` 中的具体哪一种,可以参考 [Rate Limits](https://docs.siliconflow.cn/rate-limits/rate-limit-and-upgradation) 了解具体的限流策略
* **504 / 503**:
* 一般是服务系统负载比较高,可以稍后尝试;
* 对于对话和文本转语音请求,可以尝试使用流式输出("stream" : true),参考 [流式输出](https://docs.siliconflow.cn/faqs/stream-mode);
* **500**:服务发生了未知的错误,可以联系相关人员进行排查
4. 认证成功后您可以**修改认证信息**或者**变更为企业用户**,30 天内只可以完成一次变更或修改。
【注意事项】
* 实名认证直接影响账号的归属。如果是企业用户,请您进行企业实名认证,以免人员变动等因素引起的不必要纠纷。更多信息请参见个人实名认证和企业实名认证的区别。
* 根据相关法律法规,我们不对未满 14 周岁的个人提供在线实名认证服务。
## 5. 如何进行企业认证?
1. 登录 SiliconCloud 平台,点击“用户中心-实名认证”。
2. 在实名认证页面,选择认证类型为“企业实名认证”,然后选择认证方式。认证方式有以下两种:
* 选择法人人脸识别认证
1. 填写企业名称、统一社会信用代码、法人姓名和法人身份证号,勾选同意协议。
2. 法人使用手机支付宝 App 扫描二维码,扫描后按照手机上的提示完成人脸认证,验证成功即可完成认证。
* 选择企业对公打款认证
1. 填写企业名称、统一社会信用代码和法人姓名,勾选同意协议。
2. 填写企业对公银行卡号,填写对公银行(精确到支行)名称,选择具体的开户行,确认无误后点击获取验证金额。
3. 等待随机打款金额到账,通常在 10 分钟以内。
4. 打款成功后,请跟财务核实收到的 1 元以下随机金额,将该金额回填到该页面,核实无误后即可认证成功。
认证成功后您可以**修改认证信息**,30 天内只可进行一次修改。
# 错误处理
Source: https://docs.siliconflow.cn/cn/faqs/error-code
**1. 尝试获取 HTTP 错误代码,初步定位问题**
a. 在代码中,尽量把错误码和报错信息(message)打印出来,利用这些信息,可以定位大部分问题。
```shell
HTTP/1.1 400 Bad Request
Date: Thu, 19 Dec 2024 08:39:19 GMT
Content-Type: application/json; charset=utf-8
Content-Length: 87
Connection: keep-alive
{"code":20012,"message":"Model does not exist. Please check it carefully.","data":null}
```
* 常见错误代码及原因:
* **400**:参数不正确,请参考报错信息(message)修正不合法的请求参数;
* **401**:API Key 没有正确设置;
* **403**:权限不够,最常见的原因是该模型需要实名认证,其他情况参考报错信息(message);
* **429**:触发了 rate limits;参考报错信息(message)判断触发的是 `RPM /RPD / TPM / TPD / IPM / IPD` 中的具体哪一种,可以参考 [Rate Limits](https://docs.siliconflow.cn/rate-limits/rate-limit-and-upgradation) 了解具体的限流策略
* **504 / 503**:
* 一般是服务系统负载比较高,可以稍后尝试;
* 对于对话和文本转语音请求,可以尝试使用流式输出("stream" : true),参考 [流式输出](https://docs.siliconflow.cn/faqs/stream-mode);
* **500**:服务发生了未知的错误,可以联系相关人员进行排查
 b. 如果客户端没有输出相应的信息,可以考虑在命令行下运行 curl 命令 (以 LLM 模型为例):
```shell
curl --request POST \
--url https://api.siliconflow.cn/v1/chat/completions \
--header 'accept: application/json' \
--header 'authorization: Bearer 改成你的apikey' \
--header 'content-type: application/json' \
--data '
{
"model": "记得改模型",
"messages": [
{
"role": "user",
"content": "你好"
}
],
"max_tokens": 128
}' -i
```
**2. 可以尝试换一个模型,看看问题是否依旧**
**3. 如果开了代理,可以考虑将代理关闭后再尝试访问**
如遇其他问题,请点击[硅基流动MaaS线上需求收集表](https://m09tqret04o.feishu.cn/share/base/form/shrcnaamvQ4C7YKMixVnS32k1G3)反馈。
# 开具发票
Source: https://docs.siliconflow.cn/cn/faqs/invoice
## 1. 开票主体信息
开票主体:北京硅基流动科技有限公司
b. 如果客户端没有输出相应的信息,可以考虑在命令行下运行 curl 命令 (以 LLM 模型为例):
```shell
curl --request POST \
--url https://api.siliconflow.cn/v1/chat/completions \
--header 'accept: application/json' \
--header 'authorization: Bearer 改成你的apikey' \
--header 'content-type: application/json' \
--data '
{
"model": "记得改模型",
"messages": [
{
"role": "user",
"content": "你好"
}
],
"max_tokens": 128
}' -i
```
**2. 可以尝试换一个模型,看看问题是否依旧**
**3. 如果开了代理,可以考虑将代理关闭后再尝试访问**
如遇其他问题,请点击[硅基流动MaaS线上需求收集表](https://m09tqret04o.feishu.cn/share/base/form/shrcnaamvQ4C7YKMixVnS32k1G3)反馈。
# 开具发票
Source: https://docs.siliconflow.cn/cn/faqs/invoice
## 1. 开票主体信息
开票主体:北京硅基流动科技有限公司
## 2. 开票时效性
通常发票会在您申请开票后2个工作日内开具完成
## 3. 开票金额
仅`已消费金额`可以申请开具发票,充值未消费的充值余额不可开具发票,您可酌情申请退款;已开票金额不可重复开票。
## 4. 发票类型
目前平台仅提供数电发票
企业认证用户可以开具企业抬头的增值税专用发票/增值税普通发票;
个人认证只能开具个人抬头的增值税普通发票
## 5. 开票流程
### 5.1 用户自助开票
* 登陆 [SiliconCloud](https://cloud.siliconflow.cn/),进入到 [开具发票](https://cloud.siliconflow.cn/invoice) 页面
* 点击`申请开票`按钮,
* 在页面中填入`申请开票金额`
* 选择`费用名称`
* 选择`抬头名称和税号`
* 选择`发票类型`
* 勾选`发票接收方式`
* 点击`申请发票`按钮
* 已申请开具的发票会在发票记录中显示,开具成功后`下载`即可
### 5.2 用户登记后,平台开票
根据我国税收相关政策要求,发票抬头需与实名认证主体名称一致,个人账号无法开具机构抬头发票;如有需要,您可以[变更认证主体](https://cloud.siliconflow.cn/account/authentication);若完成认证确有困难,请通过[开具发票](https://cloud.siliconflow.cn/invoice)页面中的登记页进行登记。
 # 上架指南
Source: https://docs.siliconflow.cn/cn/faqs/listing_guide
# 硅基流动AI应用合规上架指南
以下材料适用国家为:中国
## 背景依据
硅基流动 MaaS服务平台面向广大开发者提供相关开源大模型加速框架推理等技术支持,开发者开发的应用/小程序中通过硅基流动 MaaS服务平台接入了DeepSeek、通义千问等系列开源大模型。
若开发者想要将接入了开源大模型的应用或小程序上架到应用市场或小程序平台中,因应用市场或小程序平台的应用场景存在差异,可能需要开发者提供各种相关资料,本篇将基于法律合规要求引导各位开发者如何获取对应资料。
## 📌 关键提示
### 1. 责任提示
#### ⚠️ 行动前必读:
1. 建议您研读《生成式人工智能服务管理暂行办法》原文或咨询法律专家
2. 主动追踪政策变化,定期核验最新要求,并依据业务场景寻求专业法律意见
3. 您需独立承担应用/小程序的全部法律责任
### 2. 平台声明
#### 本文仅提供:
1. 备案材料清单与获取路径
2. 所接入模型的备案信息查询指引
3. 不构成任何法律意见
#### 重要法律定位:
即使使用本站模型服务,您仍是法定“服务提供者”,须履行包括:
① 内容审核 ② 用户保护 ③ 数据安全 ④ 标识规范 等全链条义务
硅基流动不保证您的小程序或APP 通过该方案可以 100% 通过审核,具体审核规则由对应的审核方负责。硅基流动仅可证明贵方在使用硅基流动的服务。
## 需备案的场景:
### 1、微信小程序上架场景
# 上架指南
Source: https://docs.siliconflow.cn/cn/faqs/listing_guide
# 硅基流动AI应用合规上架指南
以下材料适用国家为:中国
## 背景依据
硅基流动 MaaS服务平台面向广大开发者提供相关开源大模型加速框架推理等技术支持,开发者开发的应用/小程序中通过硅基流动 MaaS服务平台接入了DeepSeek、通义千问等系列开源大模型。
若开发者想要将接入了开源大模型的应用或小程序上架到应用市场或小程序平台中,因应用市场或小程序平台的应用场景存在差异,可能需要开发者提供各种相关资料,本篇将基于法律合规要求引导各位开发者如何获取对应资料。
## 📌 关键提示
### 1. 责任提示
#### ⚠️ 行动前必读:
1. 建议您研读《生成式人工智能服务管理暂行办法》原文或咨询法律专家
2. 主动追踪政策变化,定期核验最新要求,并依据业务场景寻求专业法律意见
3. 您需独立承担应用/小程序的全部法律责任
### 2. 平台声明
#### 本文仅提供:
1. 备案材料清单与获取路径
2. 所接入模型的备案信息查询指引
3. 不构成任何法律意见
#### 重要法律定位:
即使使用本站模型服务,您仍是法定“服务提供者”,须履行包括:
① 内容审核 ② 用户保护 ③ 数据安全 ④ 标识规范 等全链条义务
硅基流动不保证您的小程序或APP 通过该方案可以 100% 通过审核,具体审核规则由对应的审核方负责。硅基流动仅可证明贵方在使用硅基流动的服务。
## 需备案的场景:
### 1、微信小程序上架场景
 ## 获取备案信息的操作指引
### 步骤一:查询模型备案号
#### 模型备案主体信息示例:
DeepSeek:
查询地址:[https://beian.cac.gov.cn/#/searchResult](https://beian.cac.gov.cn/#/searchResult)
## 获取备案信息的操作指引
### 步骤一:查询模型备案号
#### 模型备案主体信息示例:
DeepSeek:
查询地址:[https://beian.cac.gov.cn/#/searchResult](https://beian.cac.gov.cn/#/searchResult)
 | 模型名称 | 备案说明 | 备案号 | 链接 |
| --------------------- | ------------------- | --------------------------------- | --------------------------------------------------------------------------------------------------------------------- |
| Deepseek Chat | 生成式人工智能服务备案 | Beijing-DeepseekChat-202404280016 | [https://www.cac.gov.cn/2024-04/02/c\_1713729983803145.htm](https://www.cac.gov.cn/2024-04/02/c_1713729983803145.htm) |
| DeepSeek大语言模型算法 | 深度合成服务算法备案(服务技术支持者) | 网信算备110108970550101240011号 | [https://www.cac.gov.cn/2024-04/11/c\_1714509267496697.htm](https://www.cac.gov.cn/2024-04/11/c_1714509267496697.htm) |
| DeepSeekChat 求索对话生成算法 | 深度合成服务算法备案(服务提供者) | 网信算备330105747635301240017号 | [https://www.cac.gov.cn/2024-06/12/c\_1719783421546747.htm](https://www.cac.gov.cn/2024-06/12/c_1719783421546747.htm) |
| 大模型 | 算法名称 | 备案主体角色 | 备案主体 | 主要用途 | 备案号 |
| ---- | ------------- | ------- | ----------------- | -------------------------------------------------------------- | -------------------------- |
| 通义千问 | 达摩院交互式多能型合成算法 | 服务技术支持者 | 阿里巴巴达摩院(杭州)科技有限公司 | 应用于开放域多模态内容生成场景,服务于问答、咨询类的企业端客户,通过API提供根据用户输入生成多模态信息的功能。 | 网信算备330110507206401230035号 |
| 通义万相 | 达摩院图像合成算法 | 服务技术支持者 | 阿里巴巴达摩院(杭州)科技有限公司 | 应用于数字图像处理、计算机视觉、虚拟现实、人工智能等领域,在图像生成、图像增强、图像分割、图像识别等方面具有广泛的应用前景。 | 网信算备330110507206401230027号 |
| 通义万相 | 通义万相视频生成算法 | 服务技术支持者 | 通义云启(杭州)信息技术有限公司 | 应用于视频生成场景,服务于企业端客户,根据用户输入的文本或图像,生成符合广告媒体领域要求的视频。 | 网信算备330106003156001240091号 |
通义千问:
| 模型名称 | 备案说明 | 备案号 | 链接 |
| --------------------- | ------------------- | --------------------------------- | --------------------------------------------------------------------------------------------------------------------- |
| Deepseek Chat | 生成式人工智能服务备案 | Beijing-DeepseekChat-202404280016 | [https://www.cac.gov.cn/2024-04/02/c\_1713729983803145.htm](https://www.cac.gov.cn/2024-04/02/c_1713729983803145.htm) |
| DeepSeek大语言模型算法 | 深度合成服务算法备案(服务技术支持者) | 网信算备110108970550101240011号 | [https://www.cac.gov.cn/2024-04/11/c\_1714509267496697.htm](https://www.cac.gov.cn/2024-04/11/c_1714509267496697.htm) |
| DeepSeekChat 求索对话生成算法 | 深度合成服务算法备案(服务提供者) | 网信算备330105747635301240017号 | [https://www.cac.gov.cn/2024-06/12/c\_1719783421546747.htm](https://www.cac.gov.cn/2024-06/12/c_1719783421546747.htm) |
| 大模型 | 算法名称 | 备案主体角色 | 备案主体 | 主要用途 | 备案号 |
| ---- | ------------- | ------- | ----------------- | -------------------------------------------------------------- | -------------------------- |
| 通义千问 | 达摩院交互式多能型合成算法 | 服务技术支持者 | 阿里巴巴达摩院(杭州)科技有限公司 | 应用于开放域多模态内容生成场景,服务于问答、咨询类的企业端客户,通过API提供根据用户输入生成多模态信息的功能。 | 网信算备330110507206401230035号 |
| 通义万相 | 达摩院图像合成算法 | 服务技术支持者 | 阿里巴巴达摩院(杭州)科技有限公司 | 应用于数字图像处理、计算机视觉、虚拟现实、人工智能等领域,在图像生成、图像增强、图像分割、图像识别等方面具有广泛的应用前景。 | 网信算备330110507206401230027号 |
| 通义万相 | 通义万相视频生成算法 | 服务技术支持者 | 通义云启(杭州)信息技术有限公司 | 应用于视频生成场景,服务于企业端客户,根据用户输入的文本或图像,生成符合广告媒体领域要求的视频。 | 网信算备330106003156001240091号 |
通义千问:
 ### 步骤二:获取合作协议
#### 合作协议获取流程:
1. 确保您的账号完成了企业实名认证:认证链接:[https://cloud.siliconflow.cn/account/authentication](https://cloud.siliconflow.cn/account/authentication)
2. 添加我们企微客服:
### 步骤二:获取合作协议
#### 合作协议获取流程:
1. 确保您的账号完成了企业实名认证:认证链接:[https://cloud.siliconflow.cn/account/authentication](https://cloud.siliconflow.cn/account/authentication)
2. 添加我们企微客服:
 3. 按照客服指引填写表单,我们将在 5 个工作日内提供相关合作协议电子签约版本。
#### 需要注意:
1. 您的小程序/应用主体名称,需要和签订合作协议以及硅基流动账号实名认证企业为同一个,不进行硅基流动企业实名认证则无法提供相应协议。
2. 准确填写您的小程序应用场景和应用模型,将有助于您通过审核。
#### 主要法律依据:
1. 《生成式人工智能服务管理暂行办法》
[https://www.moj.gov.cn/pub/sfbgw/flfggz/flfggzbmgz/202401/t20240109\_493171.html](https://www.moj.gov.cn/pub/sfbgw/flfggz/flfggzbmgz/202401/t20240109_493171.html)
2. 《具有舆论属性或社会动员能力的互联网信息服务安全评估规定》
[https://www.gov.cn/zhengce/zhengceku/2018-11/30/content\_5457763.htm](https://www.gov.cn/zhengce/zhengceku/2018-11/30/content_5457763.htm)
3. 《互联网信息服务算法推荐管理规定》
[https://www.gov.cn/zhengce/zhengceku/2022-01/04/content\_5666429.htm](https://www.gov.cn/zhengce/zhengceku/2022-01/04/content_5666429.htm)
# 模型问题
Source: https://docs.siliconflow.cn/cn/faqs/misc
## 1. 模型输出乱码
目前看到部分模型在不设置参数的情况下,容易出现乱码,遇到上述情况,可以尝试设置`temperature`,`top_k`,`top_p`,`frequency_penalty`这些参数。
对应的 payload 修改为如下形式,不同语言酌情调整
```python
payload = {
"model": "Qwen/Qwen2.5-Math-72B-Instruct",
"messages": [
{
"role": "user",
"content": "1+1=?",
}
],
"max_tokens": 200, # 按需添加
"temperature": 0.7, # 按需添加
"top_k": 50, # 按需添加
"top_p": 0.7, # 按需添加
"frequency_penalty": 0 # 按需添加
}
```
## 2. 关于`max_tokens`说明
平台提供的LLM模型中,
* max\_tokens 限制为 `16384` 的模型:
* deepseek-ai/DeepSeek-R1
* Pro/deepseek-ai/DeepSeek-R1
* Pro/deepseek-ai/DeepSeek-R1-0120
* Qwen/QVQ-72B-Preview
* deepseek-ai/DeepSeek-R1-Distill-Qwen-32B
* deepseek-ai/DeepSeek-R1-Distill-Qwen-14B
* deepseek-ai/DeepSeek-R1-Distill-Qwen-7B
* deepseek-ai/DeepSeek-R1-Distill-Qwen-1.5B
* Pro/deepseek-ai/DeepSeek-R1-Distill-Qwen-7B
* Pro/deepseek-ai/DeepSeek-R1-Distill-Qwen-1.5B
* max\_tokens 限制为 `8192` 的模型:
* Qwen/QwQ-32B-Preview
* max\_tokens 限制为 `4096`的模型:
* 除上述提到的其他LLM模型的
如有特殊需求,建议您点击[硅基流动MaaS线上需求收集表](\(https://m09tqret04o.feishu.cn/share/base/form/shrcnaamvQ4C7YKMixVnS32k1G3\))进行反馈。
## 3. 关于`context_length`说明
不同的LLM模型,`context_length`是有差别的,具体可以在[模型广场](https://cloud.siliconflow.cn/models)上搜索对应的模型,查看模型具体信息。
{/*## 4. 关于 `DeepSeek-R1` 和 `DeepSeek-V3` 模型调用返回 `429` 说明
1. `未实名用户`用户:每天仅能访问 `100次`。如果当天访问次数超过 `100次`,将收到 `429` 错误,并提示 "Details: RPD limit reached. Could only send 100 requests per day without real name verification",可以通过实名解锁更高的 Rate Limit。
2. `实名用户`:拥有更高的 Rate Limit,具体值参考[模型广场](https://cloud.siliconflow.cn/models)
如果访问次数超过这些限制,也会收到 `429` 错误。
*/}
## 4. Pro 和非 Pro 模型有什么区别
1. 对于部分模型,平台同时提供免费版和收费版。免费版按原名称命名;收费版在名称前加上“Pro/”以示区分。免费版的 Rate Limits 固定,收费版的 Rate Limits 可变,具体规则请参考:[Rate Limits](https://docs.siliconflow.cn/cn/userguide/rate-limits/rate-limit-and-upgradation)。
2. 对于 `DeepSeek R1` 和 `DeepSeek V3` 模型,平台根据`支付方式`的不同要求区分命名。`Pro 版`仅支持`充值余额`支付,`非 Pro 版`支持`赠费余额`和`充值余额`支付。
## 5. 语音模型中,对用户自定义音色有时间音质要求么
* cosyvoice2 上传音色必须小于30s
## 6. 模型输出截断问题
可以从以下几方面进行问题的排查:
* 通过API请求时候,输出截断问题排查:
* max\_tokens设置:max\_token设置到合适值,输出大于max\_token的情况下,会被截断,deepseek R1系列的max\_token最大可设置为16384。
* 设置流式输出请求:非流式请求时候,输出内容比较长的情况下,容易出现504超时。
* 设置客户端超时时间:把客户端超时时间设置大一些,防止未输出完成,达到客户端超时时间被截断。
* 通过第三方客户端请求,输出截断问题排查:
* CherryStdio 默认的 max\_tokens 是 4096,用户可以通过设置,打开“开启消息长度限制”的开关,将max\_token设置到合适值
3. 按照客服指引填写表单,我们将在 5 个工作日内提供相关合作协议电子签约版本。
#### 需要注意:
1. 您的小程序/应用主体名称,需要和签订合作协议以及硅基流动账号实名认证企业为同一个,不进行硅基流动企业实名认证则无法提供相应协议。
2. 准确填写您的小程序应用场景和应用模型,将有助于您通过审核。
#### 主要法律依据:
1. 《生成式人工智能服务管理暂行办法》
[https://www.moj.gov.cn/pub/sfbgw/flfggz/flfggzbmgz/202401/t20240109\_493171.html](https://www.moj.gov.cn/pub/sfbgw/flfggz/flfggzbmgz/202401/t20240109_493171.html)
2. 《具有舆论属性或社会动员能力的互联网信息服务安全评估规定》
[https://www.gov.cn/zhengce/zhengceku/2018-11/30/content\_5457763.htm](https://www.gov.cn/zhengce/zhengceku/2018-11/30/content_5457763.htm)
3. 《互联网信息服务算法推荐管理规定》
[https://www.gov.cn/zhengce/zhengceku/2022-01/04/content\_5666429.htm](https://www.gov.cn/zhengce/zhengceku/2022-01/04/content_5666429.htm)
# 模型问题
Source: https://docs.siliconflow.cn/cn/faqs/misc
## 1. 模型输出乱码
目前看到部分模型在不设置参数的情况下,容易出现乱码,遇到上述情况,可以尝试设置`temperature`,`top_k`,`top_p`,`frequency_penalty`这些参数。
对应的 payload 修改为如下形式,不同语言酌情调整
```python
payload = {
"model": "Qwen/Qwen2.5-Math-72B-Instruct",
"messages": [
{
"role": "user",
"content": "1+1=?",
}
],
"max_tokens": 200, # 按需添加
"temperature": 0.7, # 按需添加
"top_k": 50, # 按需添加
"top_p": 0.7, # 按需添加
"frequency_penalty": 0 # 按需添加
}
```
## 2. 关于`max_tokens`说明
平台提供的LLM模型中,
* max\_tokens 限制为 `16384` 的模型:
* deepseek-ai/DeepSeek-R1
* Pro/deepseek-ai/DeepSeek-R1
* Pro/deepseek-ai/DeepSeek-R1-0120
* Qwen/QVQ-72B-Preview
* deepseek-ai/DeepSeek-R1-Distill-Qwen-32B
* deepseek-ai/DeepSeek-R1-Distill-Qwen-14B
* deepseek-ai/DeepSeek-R1-Distill-Qwen-7B
* deepseek-ai/DeepSeek-R1-Distill-Qwen-1.5B
* Pro/deepseek-ai/DeepSeek-R1-Distill-Qwen-7B
* Pro/deepseek-ai/DeepSeek-R1-Distill-Qwen-1.5B
* max\_tokens 限制为 `8192` 的模型:
* Qwen/QwQ-32B-Preview
* max\_tokens 限制为 `4096`的模型:
* 除上述提到的其他LLM模型的
如有特殊需求,建议您点击[硅基流动MaaS线上需求收集表](\(https://m09tqret04o.feishu.cn/share/base/form/shrcnaamvQ4C7YKMixVnS32k1G3\))进行反馈。
## 3. 关于`context_length`说明
不同的LLM模型,`context_length`是有差别的,具体可以在[模型广场](https://cloud.siliconflow.cn/models)上搜索对应的模型,查看模型具体信息。
{/*## 4. 关于 `DeepSeek-R1` 和 `DeepSeek-V3` 模型调用返回 `429` 说明
1. `未实名用户`用户:每天仅能访问 `100次`。如果当天访问次数超过 `100次`,将收到 `429` 错误,并提示 "Details: RPD limit reached. Could only send 100 requests per day without real name verification",可以通过实名解锁更高的 Rate Limit。
2. `实名用户`:拥有更高的 Rate Limit,具体值参考[模型广场](https://cloud.siliconflow.cn/models)
如果访问次数超过这些限制,也会收到 `429` 错误。
*/}
## 4. Pro 和非 Pro 模型有什么区别
1. 对于部分模型,平台同时提供免费版和收费版。免费版按原名称命名;收费版在名称前加上“Pro/”以示区分。免费版的 Rate Limits 固定,收费版的 Rate Limits 可变,具体规则请参考:[Rate Limits](https://docs.siliconflow.cn/cn/userguide/rate-limits/rate-limit-and-upgradation)。
2. 对于 `DeepSeek R1` 和 `DeepSeek V3` 模型,平台根据`支付方式`的不同要求区分命名。`Pro 版`仅支持`充值余额`支付,`非 Pro 版`支持`赠费余额`和`充值余额`支付。
## 5. 语音模型中,对用户自定义音色有时间音质要求么
* cosyvoice2 上传音色必须小于30s
## 6. 模型输出截断问题
可以从以下几方面进行问题的排查:
* 通过API请求时候,输出截断问题排查:
* max\_tokens设置:max\_token设置到合适值,输出大于max\_token的情况下,会被截断,deepseek R1系列的max\_token最大可设置为16384。
* 设置流式输出请求:非流式请求时候,输出内容比较长的情况下,容易出现504超时。
* 设置客户端超时时间:把客户端超时时间设置大一些,防止未输出完成,达到客户端超时时间被截断。
* 通过第三方客户端请求,输出截断问题排查:
* CherryStdio 默认的 max\_tokens 是 4096,用户可以通过设置,打开“开启消息长度限制”的开关,将max\_token设置到合适值
 ## 7. 模型使用过程中返回429错误排查
可以从以下几方面进行问题的排查:
* 普通用户:检查用户等级及模型对应的 Rate Limits(速率限制)。如果请求超出 Rate Limits,建议稍后再尝试请求。
* 专属实例用户:专属实例通常没有 Rate Limits 限制。如果出现 429 错误,首先确认是否调用了专属实例的正确模型名称,并检查使用的 api\_key 是否与专属实例匹配。
## 8. 已充值成功,仍然提示账户余额不足
可以从以下几方面进行问题的排查:
* 确认使用的 api\_key 是否与刚刚充值的账户匹配。
* 如果 api\_key 无误,可能是充值过程中存在网络延迟,建议等待几分钟后再重试。
## 9. 已实名认证,还是无法访问部分模型
可以从以下几方面进行问题的排查:
* 确认使用的 api\_key 是否与刚刚完成实名认证的账户匹配。
* 如果 api\_key 无误,可以进入[实名认证](https://cloud.siliconflow.cn/account/authentication)页面,检查认证状态。如果状态显示为“认证中”,可以尝试取消并重新进行认证。
如遇其他问题,请点击[硅基流动MaaS线上需求收集表](https://m09tqret04o.feishu.cn/share/base/form/shrcnaamvQ4C7YKMixVnS32k1G3)反馈。
# 财务问题
Source: https://docs.siliconflow.cn/cn/faqs/misc_finance
## 1. 如何充值
1. 电脑端登录 [SiliconCloud](https://cloud.siliconflow.cn/) 官网。
2. 点击左侧边栏 “[实名认证](https://cloud.siliconflow.cn/account/authentication)” 进行认证。
3. 点击左侧边栏 “[余额充值](https://cloud.siliconflow.cn/expensebill)” 进行充值。
## 7. 模型使用过程中返回429错误排查
可以从以下几方面进行问题的排查:
* 普通用户:检查用户等级及模型对应的 Rate Limits(速率限制)。如果请求超出 Rate Limits,建议稍后再尝试请求。
* 专属实例用户:专属实例通常没有 Rate Limits 限制。如果出现 429 错误,首先确认是否调用了专属实例的正确模型名称,并检查使用的 api\_key 是否与专属实例匹配。
## 8. 已充值成功,仍然提示账户余额不足
可以从以下几方面进行问题的排查:
* 确认使用的 api\_key 是否与刚刚充值的账户匹配。
* 如果 api\_key 无误,可能是充值过程中存在网络延迟,建议等待几分钟后再重试。
## 9. 已实名认证,还是无法访问部分模型
可以从以下几方面进行问题的排查:
* 确认使用的 api\_key 是否与刚刚完成实名认证的账户匹配。
* 如果 api\_key 无误,可以进入[实名认证](https://cloud.siliconflow.cn/account/authentication)页面,检查认证状态。如果状态显示为“认证中”,可以尝试取消并重新进行认证。
如遇其他问题,请点击[硅基流动MaaS线上需求收集表](https://m09tqret04o.feishu.cn/share/base/form/shrcnaamvQ4C7YKMixVnS32k1G3)反馈。
# 财务问题
Source: https://docs.siliconflow.cn/cn/faqs/misc_finance
## 1. 如何充值
1. 电脑端登录 [SiliconCloud](https://cloud.siliconflow.cn/) 官网。
2. 点击左侧边栏 “[实名认证](https://cloud.siliconflow.cn/account/authentication)” 进行认证。
3. 点击左侧边栏 “[余额充值](https://cloud.siliconflow.cn/expensebill)” 进行充值。
 ## 2. 赠送余额有期限吗
赠送余额目前没有有效期限制。
## 3. 如何查询使用账单
1. 电脑端登录 [SiliconCloud](https://cloud.siliconflow.cn/) 官网。
2. 点击左侧边栏 “[费用账单](https://cloud.siliconflow.cn/bills)” 了解。
## 2. 赠送余额有期限吗
赠送余额目前没有有效期限制。
## 3. 如何查询使用账单
1. 电脑端登录 [SiliconCloud](https://cloud.siliconflow.cn/) 官网。
2. 点击左侧边栏 “[费用账单](https://cloud.siliconflow.cn/bills)” 了解。
如您需要开发票,请根据 [开具发票](https://docs.siliconflow.cn/faqs/invoice) 发邮件,我们会根据您的实际消耗费用开发票。
 ## 4. 模型微调的计费规则
模型微调功能会按照训练和推理两个不同场景独立计费。
费用查看路径:[模型微调](https://cloud.siliconflow.cn/fine-tune) - 新建微调任务,选择所需的“基础模型”后,页面会显示对应的“微调训练价格”和“微调推理价格”。
## 4. 模型微调的计费规则
模型微调功能会按照训练和推理两个不同场景独立计费。
费用查看路径:[模型微调](https://cloud.siliconflow.cn/fine-tune) - 新建微调任务,选择所需的“基础模型”后,页面会显示对应的“微调训练价格”和“微调推理价格”。
 如遇其他问题,请点击[硅基流动MaaS线上需求收集表](https://m09tqret04o.feishu.cn/share/base/form/shrcnaamvQ4C7YKMixVnS32k1G3)反馈。
# Rate Limits 问题
Source: https://docs.siliconflow.cn/cn/faqs/misc_rate
## 1. 免费模型如何提升 Rate Limits
* 所有免费模型的 Rate Limits 是固定的。
如遇其他问题,请点击[硅基流动MaaS线上需求收集表](https://m09tqret04o.feishu.cn/share/base/form/shrcnaamvQ4C7YKMixVnS32k1G3)反馈。
# Rate Limits 问题
Source: https://docs.siliconflow.cn/cn/faqs/misc_rate
## 1. 免费模型如何提升 Rate Limits
* 所有免费模型的 Rate Limits 是固定的。
* 对于部分模型,平台同时提供免费版和收费版。免费版按照原名称命名;收费版会在名称前加上“Pro/”以示区分。
* 收费版模型支持通过月消费金额解锁更宽松的 Rate Limits,也可以单独购买[等级包](https://cloud.siliconflow.cn/package)快速提升 Rate Limits。
* 对于 `DeepSeek R1` 和 `DeepSeek V3` 模型,Rate Limits 是固定的。
如遇其他问题,请点击[硅基流动MaaS线上需求收集表](https://m09tqret04o.feishu.cn/share/base/form/shrcnaamvQ4C7YKMixVnS32k1G3)反馈。
# 使用问题
Source: https://docs.siliconflow.cn/cn/faqs/misc_use
## 1. 如何注销账号
请发送您的账户 ID和联系方式,到[contact@siliconflow.cn](mailto:contact@siliconflow.cn) 核实后将在 15 个工作日内处理。
## 2. 如何邀请
1. 电脑端登录 [SiliconCloud](https://cloud.siliconflow.cn/) 官网。
2. 点击左侧边栏 “[我的邀请](https://cloud.siliconflow.cn/invitation)” — “复制邀请链接”。
3. 分享邀请信息。
4. 邀请成功的具体信息会显示在 “[我的邀请](https://cloud.siliconflow.cn/invitation)”页面。
有三种邀请方式供选择:二维码、邀请码和邀请链接。
 ## 3. 为什么我的手机号无法注册或绑定?
为保障平台用户的账户安全与服务体验,平台对部分可能存在安全风险的手机号号段(如部分虚拟运营商号段)做了注册与绑定限制。此举旨在为您提供更加安全、稳定的服务环境,降低因恶意行为对正常使用可能带来的干扰和影响。
建议您使用中国大陆常见运营商(如中国移动、中国联通、中国电信)所提供的常规手机号进行注册或绑定操作。
如您使用的是正规手机号但仍出现提示,建议尝试更换号码;如仍有疑问,可添加小助手微信,我们将及时协助您解决。
## 3. 为什么我的手机号无法注册或绑定?
为保障平台用户的账户安全与服务体验,平台对部分可能存在安全风险的手机号号段(如部分虚拟运营商号段)做了注册与绑定限制。此举旨在为您提供更加安全、稳定的服务环境,降低因恶意行为对正常使用可能带来的干扰和影响。
建议您使用中国大陆常见运营商(如中国移动、中国联通、中国电信)所提供的常规手机号进行注册或绑定操作。
如您使用的是正规手机号但仍出现提示,建议尝试更换号码;如仍有疑问,可添加小助手微信,我们将及时协助您解决。
 如遇其他问题,请点击[硅基流动MaaS线上需求收集表](https://m09tqret04o.feishu.cn/share/base/form/shrcnaamvQ4C7YKMixVnS32k1G3)反馈。
# 流式输出
Source: https://docs.siliconflow.cn/cn/faqs/stream-mode
## 1. 在 python 中使用流式输出
### 1.1 基于 OpenAI 库的流式输出
在一般场景中,推荐您使用 OpenAI 的库进行流式输出。
```python
from openai import OpenAI
client = OpenAI(
base_url='https://api.siliconflow.cn/v1',
api_key='your-api-key'
)
# 发送带有流式输出的请求
response = client.chat.completions.create(
model="deepseek-ai/DeepSeek-V2.5",
messages=[
{"role": "user", "content": "SiliconCloud公测上线,每用户送3亿token 解锁开源大模型创新能力。对于整个大模型应用领域带来哪些改变?"}
],
stream=True # 启用流式输出
)
# 逐步接收并处理响应
for chunk in response:
if not chunk.choices:
continue
if chunk.choices[0].delta.content:
print(chunk.choices[0].delta.content, end="", flush=True)
if chunk.choices[0].delta.reasoning_content:
print(chunk.choices[0].delta.reasoning_content, end="", flush=True)
```
### 1.2 基于 requests 库的流式输出
如果您有非 openai 的场景,如您需要基于 request 库使用 siliconcloud API,请您注意:
除了 payload 中的 stream 需要设置外,request 请求的参数也需要设置stream = True, 才能正常按照 stream 模式进行返回。
```python
from openai import OpenAI
import requests
import json
url = "https://api.siliconflow.cn/v1/chat/completions"
payload = {
"model": "deepseek-ai/DeepSeek-V2.5", # 替换成你的模型
"messages": [
{
"role": "user",
"content": "SiliconCloud公测上线,每用户送3亿token 解锁开源大模型创新能力。对于整个大模型应用领域带来哪些改变?"
}
],
"stream": True # 此处需要设置为stream模式
}
headers = {
"accept": "application/json",
"content-type": "application/json",
"authorization": "Bearer your-api-key"
}
response = requests.post(url, json=payload, headers=headers, stream=True) # 此处request需要指定stream模式
# 打印流式返回信息
if response.status_code == 200:
full_content = ""
full_reasoning_content = ""
for chunk in response.iter_lines():
if chunk:
chunk_str = chunk.decode('utf-8').replace('data: ', '')
if chunk_str != "[DONE]":
chunk_data = json.loads(chunk_str)
delta = chunk_data['choices'][0].get('delta', {})
content = delta.get('content', '')
reasoning_content = delta.get('reasoning_content', '')
if content:
print(content, end="", flush=True)
full_content += content
if reasoning_content:
print(reasoning_content, end="", flush=True)
full_reasoning_content += reasoning_content
else:
print(f"请求失败,状态码:{response.status_code}")
```
## 2. curl 中使用流式输出
curl 命令的处理机制默认情况下,curl 会缓冲输出流,所以即使服务器分块(chunk)发送数据,也需要等缓冲区填满或连接关闭后才看到内容。传入 `-N`(或 `--no-buffer`)选项,可以禁止此缓冲,让数据块立即打印到终端,从而实现流式输出。
```bash
curl -N -s \
--request POST \
--url https://api.siliconflow.cn/v1/chat/completions \
--header 'Authorization: Bearer token' \
--header 'Content-Type: application/json' \
--data '{
"model": "Qwen/Qwen2.5-72B-Instruct",
"messages": [
{"role":"user","content":"有诺贝尔数学奖吗?"}
],
"stream": true
}'
```
# 主体变更协议
Source: https://docs.siliconflow.cn/cn/legals/agreement-for-account-ownership-transfer
更新日期:2025年2月12日
在您正式提交账号主体变更申请前,请您务必认真阅读本协议。**本协议将通过加粗或加下划线的形式提示您特别关注对您的权利及义务将产生重要影响的相应条款。** 如果您对本协议的条款有疑问的,请向[contact@siliconflow.cn](mailto:contact@siliconflow.cn)咨询,如果您不同意本协议的内容,或者无法准确理解Siliconcloud平台(本平台)对条款的解释,请不要进行后续操作。
当您通过网络页面直接确认、接受引用本页面链接及提示遵守内容、签署书面协议、以及本平台认可的其他方式,或以其他法律法规或惯例认可的方式选择接受本协议,即表示您与本平台已达成协议,并同意接受本协议的全部约定内容。自本协议约定的生效之日起,本协议对您具有法律约束力。
**请您务必在接受本协议,且确信通过账号主体变更的操作,能够实现您所希望的目的,且您能够接受因本次变更行为的相关后果与责任后,再进行后续操作。**
## 一、定义和解释
1.1 “本平台官网”:是指包含域名为[https://siliconflow.cn的网站。](https://siliconflow.cn的网站。)
1.2 “本平台账号”:是指本平台分配给注册用户的数字ID,以下简称为“本平台账号”、“账号”。
1.3 “本平台账号持有人”,是指注册、持有并使用本平台账号的用户。
已完成实名认证的账号,除有相反证据外,本平台将根据用户的实名认证信息来确定账号持有人,如用户填写信息与实名认证主体信息不同的,以实名认证信息为准;未完成实名认证的账号,本平台将根据用户的填写信息,结合其他相关因素合理判断账号持有人。
1.4 “账号实名认证主体变更”:是指某一本平台账号的实名认证主体(原主体),变更为另一实名认证主体(新主体),本协议中简称为“账号主体变更”。
1.5 本协议下的“账号主体变更”程序、后果,仅适用于依据账号原主体申请发起、且被账号新主体接受的本平台账号实名认证主体变更情形。
## 二. 协议主体、内容与生效
**2.1** 本协议是特定本平台账号的账号持有人(“您”、“原主体”)与本平台之间,就您申请将双方之前就本次申请主体变更的本平台账号所达成的《SiliconCloud平台产品用户协议》的权利义务转让给第三方,及相关事宜所达成的一致条款。
**2.2 本协议为附生效条件的协议,仅在以下四个条件同时满足的情况下,** 才对您及本平台产生法律效力:
2.2.1 您所申请变更的本平台账号已完成了实名认证,且您为该实名认证主体;
2.2.2 本平台审核且同意您的账号主体变更申请;
2.2.3 您申请将账号下权利义务转让给第三方(“新主体”),且其同意按照《SiliconCloud平台产品用户协议》的约定继续履行相应的权利及义务;
2.2.4 新主体仅为企业主体,不能为自然人主体。
**2.3 您与新主体就账号下所有的产品、服务、资金、债权、债务等(统称为“账号下资源”)转让等相关事项,由您与新主体之间另外自行约定。但如果您与新主体之间的约定如与本协议约定冲突的,应优先适用本协议的约定。**
## 三. 变更的条件及程序
**3.1** 本平台仅接受符合以下条件下的账号主体变更申请;
3.1.1 由于原账号主体发生合并、分立、重组、解散、死亡等原因,需要进行账号主体变更的;
3.1.2 根据生效判决、裁定、裁决、决定等生效法律文书,需要账号主体变更的;
3.1.3 账号实际持有人与账号实名认证主体不一致,且提供了明确证明的;
3.1.4 根据法律法规规定,应当进行账号主体变更的;
3.1.5 本平台经过审慎判断,认为可以进行账号主体变更的其他情形。
**3.2** 您发起账号主体变更,应遵循如下程序要求:
3.2.1 您应在申请变更的本平台账号下发起账号主体变更申请;
3.2.2 本平台有权通过手机号、人脸识别等进行二次验证、要求您出具授权证明(当您通过账号管理人发起变更申请时)、以及其他本平台认为有必要的材料,确认本次申请账号主体变更的行为确系您本人意愿;
3.2.3 您应同意本协议的约定,接受本协议对您具有法律约束力;
3.2.4 您应遵守与账号主体变更相关的其他本平台规则、制度等的要求。
**3.3 您理解并同意,**
**3.3.1 在新主体确认接受且完成实名认证前,您可以撤回、取消本账号主体变更流程;**
**3.3.2 当新主体确认接受且完成实名认证后,您的撤销或取消请求本平台将不予支持;**
**3.3.3 且您有义务配合新主体完成账号管理权的转交。**
**3.3.4 在您进行实名认证主体变更期间,本账号下的登录和操作行为均视为您的行为,您应注意和承担账号的操作风险。**
**3.4 您理解并同意,如果发现以下任一情形的,本平台有权随时终止账号主体变更程序或采取相应处理措施:**
**3.4.1 第三方对该账号发起投诉,且尚未处理完毕的;**
**3.4.2 该账号正处于国家主管部门的调查中;**
**3.4.3 该账号正处于诉讼、仲裁或其他法律程序中;**
**3.4.4 该账号下存在与本平台的信控关系、伙伴关系等与原主体身份关联的合作关系的;**
**3.4.5 存在其他可能损害国家、社会利益,或者损害本平台或其他第三方权利的情形的;**
**3.4.6 该账号因存在频繁变更引起的账号纠纷或账号归属不明确的情形。**
## 四. 账号主体变更的影响
**4.1** 当您的账号主体变更申请经本平台同意,且新主体确认并完成实名认证后,该账号主体将完成变更,变更成功以本平台系统记录为准,变更成功后会对您产生如下后果:
**4.1.1您本账号下的权益转让给变更后的实名主体,权益包括不限于账号控制权、账号下已开通的服务、账号下未消耗的充值金额等;**
4.1.2 该账号及该账号下的全部资源的归属权全部转由新主体拥有。**但本平台有权终止,原主体通过该账号与本平台另行达成的关于优惠政策、信控、伙伴合作等相关事项的合作协议,或与其他本平台账号之间存在的关联关系等;**
**4.1.3 本平台不接受您以和新主体之间的协议为由或以其他理由,要求将该账号下一项或多项业务、权益转移给您指定的其他账号的要求;**
**4.1.4 本平台有权拒绝您以和新主体之间存在纠纷为由或以其他理由,要求撤销该账号主体变更的请求;**
**4.1.5 本平台有权在您与新主体之间就账号管理权发生争议或纠纷时,采取相应措施使得新主体获得该账号的实际管理权。**
**4.2 您理解并确认,账号主体变更并不代表您自变更之时起已对该账号下的所有行为和责任得到豁免或减轻:**
**4.2.1 您仍应对账号主体变更前,该账号下发生的所有行为承担责任;**
**4.2.2 您还需要对于变更之前已经产生,变更之后继续履行的合同及其他事项,对新主体在变更之后的履行行为及后果承担连带责任。**
## 五. 双方权利与义务
**5.1** 您应承诺并保证,
5.1.1 您在账号主体变更流程中所填写的内容及提交的资料均真实、准确、有效,且不存在任何误导或可能误导本平台同意接受该项账号主体变更申请的行为;
5.1.2 您不存在利用本平台的账号主体变更服务进行任何违反法律、法规、部门规章和国家政策等,或侵害任何第三方权利的行为;
**5.1.3 您进行账号主体变更的操作不会置本平台于违约或者违法的境地。因该账号主体变更行为而产生的任何纠纷、争议、损失、侵权、违约责任等,本平台不承担法律明确规定外的责任。**
**您进一步承诺,如上述原因给本平台造成损失的,您应向本平台承担相应赔偿责任。**
**5.2** 您理解并同意,
5.2.1 本平台有权在您发起申请后的任一时刻,要求您提供书面材料或其他证明,证明您有权进行变更账号主体的操作;
5.2.2 本平台有权依据自己谨慎的判断来确定您的申请是否符合法律法规或政策的规定及账号协议的约定,如存在违法违规或其他不适宜变更的情形的,本平台有权拒绝;
5.2.3 本平台有权记录账号实名认证主体变更前后的账号主体、交易流水、合同等相关信息,以遵守法律法规的规定,以及维护自身的合法权益;
5.2.4 如果您存在违反本协议第5.1条的行为的,本平台一经发现,有权直接终止账号主体变更流程,或者撤销已完成的账号主体变更操作,将账号主体恢复为没有进行变更前的状态。
## 六. 附则
**6.1** 您理解并接受,本协议的订立、执行和解释及争议的解决均应适用中华人民共和国法律,与法律规定不一致或存在冲突的,该不一致或冲突条款不具有法律约束力。
**6.2** 就本协议内容或其执行发生任何争议,双方应进行友好协商;协商不成时,任一方均可向被告方所在地有管辖权的人民法院提起诉讼。
**6.3** 本协议如果与双方以前签署的有关条款或者本平台的有关陈述不一致或者相抵触的,以本协议约定为准。
**您在此再次保证已经完全阅读并理解了上述《申请账号主体变更协议》,并自愿正式进入账号主体变更的后续流程,接受上述条款的约束。**
# 隐私政策
Source: https://docs.siliconflow.cn/cn/legals/privacy-policy
更新日期:2025年02月27日
欢迎您使用SiliconCloud高性价比的GenAI开放平台。北京硅基流动科技有限公司及其关联方(**“硅基流动”或“我们”**)非常重视用户(**“您”**)信息的保护。您在注册、登录、使用[https://siliconflow.cn](https://siliconflow.cn) (**“本平台”**)时,我们收集并保存您基于注册和正常使用本平台功能所需的相关**用户信息**(定义见 1.1)。我们并不收集或保存您使用本平台过程中与开源模型、第三方网站、软件、应用程序或服务之间的**交互数据**(定义见 1.4.1)“用户信息”和“交互数据”的核心差异对比见脚注1。
如我们的服务可能包含指向第三方网站、应用程序或服务的链接,本政策不适用于第三方提供的任何产品、服务、网站或内容。如您(或您的公司等经营实体)借助我们的产品或服务为您(或您的公司等经营实体)的客户提供服务,您(或您的公司等经营实体)需要自行制定符合交易场景及相关法律的隐私政策。如您(或您的公司等经营实体)同意借用我们的产品或服务访问第三方网站、应用程序或服务的链接,您(或您的公司等经营实体)需要自行遵守第三方网站、应用程序或服务的相关政策。
我们希望通过本隐私政策向您介绍我们对您的用户信息和交互数据的处理方式。在您开始使用我们的服务前,请您务必先仔细阅读和理解本政策,特别应重点阅读我们以粗体标识的条款,确保您充分理解和同意后再开始使用。如果您不同意本隐私政策,您应当立即停止使用服务。当您选择使用服务时,将视为您接受和认可我们按照本隐私政策对您的相关信息进行处理。
# 概述
本隐私政策将帮助您了解:
1. 我们如何收集和使用您的用户信息
2. 对Cookie和同类技术的使用
3. 我们如何存储您的用户信息
4. 我们如何共享、转让、公开披露您的信息
5. 我们如何保护您的信息安全
6. 我们如何管理您的用户信息
7. 未成年人使用条款
8. 隐私政策的修订和通知
9. 适用范围
## 1. 我们如何收集和使用您的用户信息
### 1.1 我们主动收集您的用户信息
为了保证您正常使用我们的平台,且在法律允许的情况下,我们会在如下场景和业务活动中收集您在使用服务时主动提供的信息,以及我们通过自动化手段收集您在使用服务过程中产生的信息,包括但不限于您提供的个人信息(**“用户信息”**)。**特别提示您注意,如信息无法单独或结合其他信息识别到您的个人身份且与您无关,其不属于法律意义上您的个人信息**;当您的信息可以单独或结合其他信息识别到您的个人身份或与您有关时,或我们将无法与任何特定用户建立联系的数据与其他您的用户信息结合使用时,则在结合使用期间,这些信息将作为您的用户信息按照本隐私政策处理与保护。**需要澄清的是,个人信息不包括经匿名化处理后的信息。**
**1.1.1 您注册、认证、登录本平台账号时**
如遇其他问题,请点击[硅基流动MaaS线上需求收集表](https://m09tqret04o.feishu.cn/share/base/form/shrcnaamvQ4C7YKMixVnS32k1G3)反馈。
# 流式输出
Source: https://docs.siliconflow.cn/cn/faqs/stream-mode
## 1. 在 python 中使用流式输出
### 1.1 基于 OpenAI 库的流式输出
在一般场景中,推荐您使用 OpenAI 的库进行流式输出。
```python
from openai import OpenAI
client = OpenAI(
base_url='https://api.siliconflow.cn/v1',
api_key='your-api-key'
)
# 发送带有流式输出的请求
response = client.chat.completions.create(
model="deepseek-ai/DeepSeek-V2.5",
messages=[
{"role": "user", "content": "SiliconCloud公测上线,每用户送3亿token 解锁开源大模型创新能力。对于整个大模型应用领域带来哪些改变?"}
],
stream=True # 启用流式输出
)
# 逐步接收并处理响应
for chunk in response:
if not chunk.choices:
continue
if chunk.choices[0].delta.content:
print(chunk.choices[0].delta.content, end="", flush=True)
if chunk.choices[0].delta.reasoning_content:
print(chunk.choices[0].delta.reasoning_content, end="", flush=True)
```
### 1.2 基于 requests 库的流式输出
如果您有非 openai 的场景,如您需要基于 request 库使用 siliconcloud API,请您注意:
除了 payload 中的 stream 需要设置外,request 请求的参数也需要设置stream = True, 才能正常按照 stream 模式进行返回。
```python
from openai import OpenAI
import requests
import json
url = "https://api.siliconflow.cn/v1/chat/completions"
payload = {
"model": "deepseek-ai/DeepSeek-V2.5", # 替换成你的模型
"messages": [
{
"role": "user",
"content": "SiliconCloud公测上线,每用户送3亿token 解锁开源大模型创新能力。对于整个大模型应用领域带来哪些改变?"
}
],
"stream": True # 此处需要设置为stream模式
}
headers = {
"accept": "application/json",
"content-type": "application/json",
"authorization": "Bearer your-api-key"
}
response = requests.post(url, json=payload, headers=headers, stream=True) # 此处request需要指定stream模式
# 打印流式返回信息
if response.status_code == 200:
full_content = ""
full_reasoning_content = ""
for chunk in response.iter_lines():
if chunk:
chunk_str = chunk.decode('utf-8').replace('data: ', '')
if chunk_str != "[DONE]":
chunk_data = json.loads(chunk_str)
delta = chunk_data['choices'][0].get('delta', {})
content = delta.get('content', '')
reasoning_content = delta.get('reasoning_content', '')
if content:
print(content, end="", flush=True)
full_content += content
if reasoning_content:
print(reasoning_content, end="", flush=True)
full_reasoning_content += reasoning_content
else:
print(f"请求失败,状态码:{response.status_code}")
```
## 2. curl 中使用流式输出
curl 命令的处理机制默认情况下,curl 会缓冲输出流,所以即使服务器分块(chunk)发送数据,也需要等缓冲区填满或连接关闭后才看到内容。传入 `-N`(或 `--no-buffer`)选项,可以禁止此缓冲,让数据块立即打印到终端,从而实现流式输出。
```bash
curl -N -s \
--request POST \
--url https://api.siliconflow.cn/v1/chat/completions \
--header 'Authorization: Bearer token' \
--header 'Content-Type: application/json' \
--data '{
"model": "Qwen/Qwen2.5-72B-Instruct",
"messages": [
{"role":"user","content":"有诺贝尔数学奖吗?"}
],
"stream": true
}'
```
# 主体变更协议
Source: https://docs.siliconflow.cn/cn/legals/agreement-for-account-ownership-transfer
更新日期:2025年2月12日
在您正式提交账号主体变更申请前,请您务必认真阅读本协议。**本协议将通过加粗或加下划线的形式提示您特别关注对您的权利及义务将产生重要影响的相应条款。** 如果您对本协议的条款有疑问的,请向[contact@siliconflow.cn](mailto:contact@siliconflow.cn)咨询,如果您不同意本协议的内容,或者无法准确理解Siliconcloud平台(本平台)对条款的解释,请不要进行后续操作。
当您通过网络页面直接确认、接受引用本页面链接及提示遵守内容、签署书面协议、以及本平台认可的其他方式,或以其他法律法规或惯例认可的方式选择接受本协议,即表示您与本平台已达成协议,并同意接受本协议的全部约定内容。自本协议约定的生效之日起,本协议对您具有法律约束力。
**请您务必在接受本协议,且确信通过账号主体变更的操作,能够实现您所希望的目的,且您能够接受因本次变更行为的相关后果与责任后,再进行后续操作。**
## 一、定义和解释
1.1 “本平台官网”:是指包含域名为[https://siliconflow.cn的网站。](https://siliconflow.cn的网站。)
1.2 “本平台账号”:是指本平台分配给注册用户的数字ID,以下简称为“本平台账号”、“账号”。
1.3 “本平台账号持有人”,是指注册、持有并使用本平台账号的用户。
已完成实名认证的账号,除有相反证据外,本平台将根据用户的实名认证信息来确定账号持有人,如用户填写信息与实名认证主体信息不同的,以实名认证信息为准;未完成实名认证的账号,本平台将根据用户的填写信息,结合其他相关因素合理判断账号持有人。
1.4 “账号实名认证主体变更”:是指某一本平台账号的实名认证主体(原主体),变更为另一实名认证主体(新主体),本协议中简称为“账号主体变更”。
1.5 本协议下的“账号主体变更”程序、后果,仅适用于依据账号原主体申请发起、且被账号新主体接受的本平台账号实名认证主体变更情形。
## 二. 协议主体、内容与生效
**2.1** 本协议是特定本平台账号的账号持有人(“您”、“原主体”)与本平台之间,就您申请将双方之前就本次申请主体变更的本平台账号所达成的《SiliconCloud平台产品用户协议》的权利义务转让给第三方,及相关事宜所达成的一致条款。
**2.2 本协议为附生效条件的协议,仅在以下四个条件同时满足的情况下,** 才对您及本平台产生法律效力:
2.2.1 您所申请变更的本平台账号已完成了实名认证,且您为该实名认证主体;
2.2.2 本平台审核且同意您的账号主体变更申请;
2.2.3 您申请将账号下权利义务转让给第三方(“新主体”),且其同意按照《SiliconCloud平台产品用户协议》的约定继续履行相应的权利及义务;
2.2.4 新主体仅为企业主体,不能为自然人主体。
**2.3 您与新主体就账号下所有的产品、服务、资金、债权、债务等(统称为“账号下资源”)转让等相关事项,由您与新主体之间另外自行约定。但如果您与新主体之间的约定如与本协议约定冲突的,应优先适用本协议的约定。**
## 三. 变更的条件及程序
**3.1** 本平台仅接受符合以下条件下的账号主体变更申请;
3.1.1 由于原账号主体发生合并、分立、重组、解散、死亡等原因,需要进行账号主体变更的;
3.1.2 根据生效判决、裁定、裁决、决定等生效法律文书,需要账号主体变更的;
3.1.3 账号实际持有人与账号实名认证主体不一致,且提供了明确证明的;
3.1.4 根据法律法规规定,应当进行账号主体变更的;
3.1.5 本平台经过审慎判断,认为可以进行账号主体变更的其他情形。
**3.2** 您发起账号主体变更,应遵循如下程序要求:
3.2.1 您应在申请变更的本平台账号下发起账号主体变更申请;
3.2.2 本平台有权通过手机号、人脸识别等进行二次验证、要求您出具授权证明(当您通过账号管理人发起变更申请时)、以及其他本平台认为有必要的材料,确认本次申请账号主体变更的行为确系您本人意愿;
3.2.3 您应同意本协议的约定,接受本协议对您具有法律约束力;
3.2.4 您应遵守与账号主体变更相关的其他本平台规则、制度等的要求。
**3.3 您理解并同意,**
**3.3.1 在新主体确认接受且完成实名认证前,您可以撤回、取消本账号主体变更流程;**
**3.3.2 当新主体确认接受且完成实名认证后,您的撤销或取消请求本平台将不予支持;**
**3.3.3 且您有义务配合新主体完成账号管理权的转交。**
**3.3.4 在您进行实名认证主体变更期间,本账号下的登录和操作行为均视为您的行为,您应注意和承担账号的操作风险。**
**3.4 您理解并同意,如果发现以下任一情形的,本平台有权随时终止账号主体变更程序或采取相应处理措施:**
**3.4.1 第三方对该账号发起投诉,且尚未处理完毕的;**
**3.4.2 该账号正处于国家主管部门的调查中;**
**3.4.3 该账号正处于诉讼、仲裁或其他法律程序中;**
**3.4.4 该账号下存在与本平台的信控关系、伙伴关系等与原主体身份关联的合作关系的;**
**3.4.5 存在其他可能损害国家、社会利益,或者损害本平台或其他第三方权利的情形的;**
**3.4.6 该账号因存在频繁变更引起的账号纠纷或账号归属不明确的情形。**
## 四. 账号主体变更的影响
**4.1** 当您的账号主体变更申请经本平台同意,且新主体确认并完成实名认证后,该账号主体将完成变更,变更成功以本平台系统记录为准,变更成功后会对您产生如下后果:
**4.1.1您本账号下的权益转让给变更后的实名主体,权益包括不限于账号控制权、账号下已开通的服务、账号下未消耗的充值金额等;**
4.1.2 该账号及该账号下的全部资源的归属权全部转由新主体拥有。**但本平台有权终止,原主体通过该账号与本平台另行达成的关于优惠政策、信控、伙伴合作等相关事项的合作协议,或与其他本平台账号之间存在的关联关系等;**
**4.1.3 本平台不接受您以和新主体之间的协议为由或以其他理由,要求将该账号下一项或多项业务、权益转移给您指定的其他账号的要求;**
**4.1.4 本平台有权拒绝您以和新主体之间存在纠纷为由或以其他理由,要求撤销该账号主体变更的请求;**
**4.1.5 本平台有权在您与新主体之间就账号管理权发生争议或纠纷时,采取相应措施使得新主体获得该账号的实际管理权。**
**4.2 您理解并确认,账号主体变更并不代表您自变更之时起已对该账号下的所有行为和责任得到豁免或减轻:**
**4.2.1 您仍应对账号主体变更前,该账号下发生的所有行为承担责任;**
**4.2.2 您还需要对于变更之前已经产生,变更之后继续履行的合同及其他事项,对新主体在变更之后的履行行为及后果承担连带责任。**
## 五. 双方权利与义务
**5.1** 您应承诺并保证,
5.1.1 您在账号主体变更流程中所填写的内容及提交的资料均真实、准确、有效,且不存在任何误导或可能误导本平台同意接受该项账号主体变更申请的行为;
5.1.2 您不存在利用本平台的账号主体变更服务进行任何违反法律、法规、部门规章和国家政策等,或侵害任何第三方权利的行为;
**5.1.3 您进行账号主体变更的操作不会置本平台于违约或者违法的境地。因该账号主体变更行为而产生的任何纠纷、争议、损失、侵权、违约责任等,本平台不承担法律明确规定外的责任。**
**您进一步承诺,如上述原因给本平台造成损失的,您应向本平台承担相应赔偿责任。**
**5.2** 您理解并同意,
5.2.1 本平台有权在您发起申请后的任一时刻,要求您提供书面材料或其他证明,证明您有权进行变更账号主体的操作;
5.2.2 本平台有权依据自己谨慎的判断来确定您的申请是否符合法律法规或政策的规定及账号协议的约定,如存在违法违规或其他不适宜变更的情形的,本平台有权拒绝;
5.2.3 本平台有权记录账号实名认证主体变更前后的账号主体、交易流水、合同等相关信息,以遵守法律法规的规定,以及维护自身的合法权益;
5.2.4 如果您存在违反本协议第5.1条的行为的,本平台一经发现,有权直接终止账号主体变更流程,或者撤销已完成的账号主体变更操作,将账号主体恢复为没有进行变更前的状态。
## 六. 附则
**6.1** 您理解并接受,本协议的订立、执行和解释及争议的解决均应适用中华人民共和国法律,与法律规定不一致或存在冲突的,该不一致或冲突条款不具有法律约束力。
**6.2** 就本协议内容或其执行发生任何争议,双方应进行友好协商;协商不成时,任一方均可向被告方所在地有管辖权的人民法院提起诉讼。
**6.3** 本协议如果与双方以前签署的有关条款或者本平台的有关陈述不一致或者相抵触的,以本协议约定为准。
**您在此再次保证已经完全阅读并理解了上述《申请账号主体变更协议》,并自愿正式进入账号主体变更的后续流程,接受上述条款的约束。**
# 隐私政策
Source: https://docs.siliconflow.cn/cn/legals/privacy-policy
更新日期:2025年02月27日
欢迎您使用SiliconCloud高性价比的GenAI开放平台。北京硅基流动科技有限公司及其关联方(**“硅基流动”或“我们”**)非常重视用户(**“您”**)信息的保护。您在注册、登录、使用[https://siliconflow.cn](https://siliconflow.cn) (**“本平台”**)时,我们收集并保存您基于注册和正常使用本平台功能所需的相关**用户信息**(定义见 1.1)。我们并不收集或保存您使用本平台过程中与开源模型、第三方网站、软件、应用程序或服务之间的**交互数据**(定义见 1.4.1)“用户信息”和“交互数据”的核心差异对比见脚注1。
如我们的服务可能包含指向第三方网站、应用程序或服务的链接,本政策不适用于第三方提供的任何产品、服务、网站或内容。如您(或您的公司等经营实体)借助我们的产品或服务为您(或您的公司等经营实体)的客户提供服务,您(或您的公司等经营实体)需要自行制定符合交易场景及相关法律的隐私政策。如您(或您的公司等经营实体)同意借用我们的产品或服务访问第三方网站、应用程序或服务的链接,您(或您的公司等经营实体)需要自行遵守第三方网站、应用程序或服务的相关政策。
我们希望通过本隐私政策向您介绍我们对您的用户信息和交互数据的处理方式。在您开始使用我们的服务前,请您务必先仔细阅读和理解本政策,特别应重点阅读我们以粗体标识的条款,确保您充分理解和同意后再开始使用。如果您不同意本隐私政策,您应当立即停止使用服务。当您选择使用服务时,将视为您接受和认可我们按照本隐私政策对您的相关信息进行处理。
# 概述
本隐私政策将帮助您了解:
1. 我们如何收集和使用您的用户信息
2. 对Cookie和同类技术的使用
3. 我们如何存储您的用户信息
4. 我们如何共享、转让、公开披露您的信息
5. 我们如何保护您的信息安全
6. 我们如何管理您的用户信息
7. 未成年人使用条款
8. 隐私政策的修订和通知
9. 适用范围
## 1. 我们如何收集和使用您的用户信息
### 1.1 我们主动收集您的用户信息
为了保证您正常使用我们的平台,且在法律允许的情况下,我们会在如下场景和业务活动中收集您在使用服务时主动提供的信息,以及我们通过自动化手段收集您在使用服务过程中产生的信息,包括但不限于您提供的个人信息(**“用户信息”**)。**特别提示您注意,如信息无法单独或结合其他信息识别到您的个人身份且与您无关,其不属于法律意义上您的个人信息**;当您的信息可以单独或结合其他信息识别到您的个人身份或与您有关时,或我们将无法与任何特定用户建立联系的数据与其他您的用户信息结合使用时,则在结合使用期间,这些信息将作为您的用户信息按照本隐私政策处理与保护。**需要澄清的是,个人信息不包括经匿名化处理后的信息。**
**1.1.1 您注册、认证、登录本平台账号时**
当您在本平台注册账号时,您可以通过手机号创建账号。我们将通过发送短信验证码来验证您的身份是否有效,收集这些信息是为了帮助您完成注册和登录。 如果您使用其他平台的账号登录本平台,您授权我们获得您其他平台账号的相关信息,例如微信等第三方平台的账户/账号信息(包括但不限于名称、头像以及您授权的其他信息)。
**1.1.2 您订购及开通使用服务时**
在您订购或开通使用我们提供的任一项服务前,根据中华人民共和国大陆地区(不含中国香港、澳门、台湾地区)相关法律法规的规定,我们需要对您进行实名认证。
(1) 如果您是个人用户,您可能需要提供您的真实身份信息,包括真实姓名、身份证件号码、身份证件正反面照片、中国银联成员机构I类银行账户卡号或 信用卡 号、银行预留手机号码等信息以完成实名认证。
(2) 如果您是单位用户,您可能需要提供您的相关信息,包括您的主体名称、统一社会信用代码、就注册账号所出具的授权委托书(加盖单位公章)、法人或组织的登记/资格证明(证件类型包括:企业营业执照、组织机构代码证、事业单位法人证书、社会团体法人登记证书、行政执法主体资格证等)、开户行、开户行账号(中国银联成员机构I类银行账户或信用卡号)、法定代表人或被授权人姓名、身份证件号码、身份证件正反面照片、法定代表人证件照片等信息以完成实名认证。另外,您可能需要提供企业联系人的个人信息,包括姓名、手机号码、电子邮箱。我们可能通过这些信息验证您的用户身份,并向您推广、介绍服务,发送业务通知、开具发票或与您进行业务沟通等。如您提供的上述信息包含第三方的个人信息或用户信息,您承诺并保证您向我们提供这些信息前已经获得了相关权利人的授权许可。
(3) 上述实名认证过程中,如果您通过人脸识别来进行实名认证的,您还需要提供面部特征的生物识别信息,并授权我们通过国家权威可信身份认证机构进行信息核验。
**1.1.3 您使用服务时**
(1) 我们致力于为您提供安全、可信的产品与使用环境,提供优质而可靠的服务与信息是我们的核心目标。为了维护我们服务的正常运行,保护您或其他用户或公众的合法利益免受损失,我们会收集用于维护产品或服务安全稳定运行的必要信息。
(2) 当您浏览或使用本平台时,为了保障网站和服务的正常运行及运营安全,预防网络攻击、侵入风险,更准确地识别违反法律法规或本平台的相关协议、服务规则的情况,我们会收集您的分辨率、时区和语言等设备信息、网络接入方式及类型信息、网页浏览记录。这些信息是我们提供服务和保障服务正常运行和网络安全所必须收集的基本信息。
(3) 为让您体验到更好的服务,并保障您的使用安全,我们可能记录网络日志信息,以及使用本平台及相关服务的频率、崩溃数据、使用情况及相关性能数据信息。
(4) 当您参与本平台调研、抽奖活动时,本平台可能会留存您的账号ID、姓名、地址、手机号、职务身份、产品和服务使用情况等信息,以后续与您取得联系,核实身份信息,并按照有关活动规则为您提供奖励(如有),具体调研、抽奖活动规则与本协议不一致的,以活动规则为准。
(5) 我们可能收集您使用本平台及相关服务而产生的用户咨询记录、报障记录和针对用户故障的排障过程(如通信或通话记录),我们将通过记录、分析这些信息以便更及时响应您的帮助请求,以及用于改进服务。
(6) 合同信息,如果您需要申请线下交付或进行产品测试等,请联系[contact@siliconflow.cn](mailto:contact@siliconflow.cn)。
(7) 为了向您提供域名服务,依据工信部相关要求,我们会收集域名持有者名称、联系人姓名、通讯地址、地区、邮编、电子邮箱、固定电话/手机号码、证件号码、证件照片。您理解并授权我们和第三方域名服务机构使用这些信息资料为您提供域名服务。
(8) 为了向您提供证书中心服务,依据数字证书认证机构相关要求,我们会收集联系人姓名、联系人邮箱、联系人手机号码、企业名称、企业所在城市、企业地址。您理解并授权我们和第三方证书服务机构使用这些信息资料为您提供证书中心服务。
(9) 您知悉并同意,对于您在使用产品及/或服务的过程中提供的您的联系方式(即联系电话及电子邮箱),我们在运营中可能会向其中的一种或多种发送通知,用于用户消息告知、身份验证、安全验证、用户使用体验调研等用途;此外,我们也可能会向在前述过程中收集的手机号码通过短信、电话的方式,为您提供您可能感兴趣的服务、功能或活动等商业性信息的用途,但请您放心,如您不愿接受这些信息,您可以通过手机短信或回复邮件退订方式进行退订,也可以直接与我们联系进行退订。
### 1.2 我们可能从第三方获得的用户信息
为了给您提供更好、更优、更加个性化的服务,或共同为您提供服务,或为了预防互联网欺诈的目的,我们的关联公司、合作伙伴可能会依据法律规定或与您的约定或征得您同意前提下,向我们分享您的信息。我们会根据相关法律法规规定和/或该身份认证功能所必需,采用行业内通行的方式及尽最大的商业努力来保护您用户信息的安全。
### 1.3 收集、使用用户信息目的变更的处理
请您了解,随着我们业务的发展,我们提供的功能或服务可能有所调整变化。原则上,当新功能或服务与我们当前提供的功能或服务相关时,收集与使用的用户信息将与原处理目的具有直接或合理关联。仅在与原处理目的无直接或合理关联的场景下,我们收集、使用您的用户信息,会再次按照法律法规及国家标准的要求以页面提示、交互流程、协议确认方式另行向您进行告知说明。
### 1.4 业务和客户数据
请您理解,您的业务和客户数据不同于用户信息,本平台将按如下方式处理:
**1.4.1** 您通过本平台提供的服务(不包括第三方服务)与开源模型、第三方网站、软件、应用程序或服务之间进行输入、反馈、修正、加工、存储、上传、下载、分发以及通过其他方式所产生或处理(**“处理”**)的数据,均为您的业务和客户数据(**“交互数据”**),您完全拥有您的交互数据。本平台作为中立的技术服务提供者,本平台提供的技术服务只会严格执行您的指示处理您的交互数据,除非法律法规另有规定、依据特定产品规则另行约定或基于您的要求为您提供技术协助进行故障排除或解决技术问题,我们不会访问您的交互数据,亦不会对您的交互数据进行任何非授权的使用或披露。
**1.4.2** 您应对您的交互数据来源及内容负责,我们提示您谨慎判断数据来源及内容的合法性。您应保证有权授权本平台通过提供技术服务对该等交互数据进行处理,且前述处理活动均符合相关法律法规的要求,不存在任何违法违规、侵权或违反与第三方合同约定的情形,亦不会将数据用于违法违规目的。若因您的交互数据内容或您处理以及您授权本平台处理交互数据行为违反法律法规、部门规章或国家政策而造成的全部结果及责任均由您自行承担。
**1.4.3** 受限于前款规定,若您提供的交互数据包含任何个人信息或需要获得授权后才能使用的信息时(**“需授权信息”**),您应当自行依法提前向相关信息主体履行告知义务,并取得相关信息主体的单独同意,并保证:
(1)在我们要求时,您能就需授权信息的来源及其合法性提供书面说明和确认;
(2)在我们要求时,您能提供需授权信息的授权范围,包括使用目的,个人信息主体同意您使用本平台对其个人信息进行处理;如您超出该等需授权信息的授权范围或期限时,您应自行负责获得需授权信息授权的范围扩大或延期。
您理解并同意,除非满足上述条件及法律要求的其他义务,您不得向我们提供包含需授权信息的交互数据。
如您违反上述义务,或未按照要求向我们提供合理满意的证明,或我们收到个人信息主体举报或投诉,我们有权单方决定拒绝继续提供技术服务(根据实际情形,包括通过限制相关服务功能,冻结、注销或收回账号等方式),或拒绝按照您的指令处理相关个人信息及其相关的数据,由此产生的全部责任均由您自行承担。
**1.4.4** 您理解并同意,您应根据自身需求自行对您的交互数据进行存储,我们仅依据相关法律法规要求或特定的服务规则约定,提供数据存储服务(例如:您和我们的数据中心就存储您的业务和客户数据有专项约定)。您理解并同意,除非法律法规另有规定或依据服务规则约定,我们没有义务存储您的数据或信息,亦不对您的数据存储工作或结果承担任何责任。
## 2. 对Cookie和同类技术的使用
Cookie和同类技术是互联网中的通用常用技术。当您使用本平台时,我们可能会使用相关技术向您的设备发送一个或多个Cookie或匿名标识符,以收集和存储您的账号信息、搜索记录信息以及登录状态信息。通过Cookie和同类技术可以帮助您省去重复填写账号信息、输入搜索内容的步骤和流程,还可以帮助我们改进服务效率、提升登录和响应速度。
您可以通过浏览器设置拒绝或管理Cookie。但请注意,如果停用Cookie,您有可能无法享受最佳的服务体验,某些功能的可用性可能会受到影响。我们承诺,我们不会将通过Cookie或同类技术收集到的您的用户信息用于本隐私政策所述目的之外的任何其他用途。
## 3. 我们如何存储您的用户信息
### 3.1 信息存储的地点
出于服务专业性考虑,我们可能委托关联公司或其他法律主体向您提供本平台上一项或多项具体服务。我们依照法律法规的规定,将在境内运营本网站和相关服务过程中收集和产生的用户信息存储于中华人民共和国境内。
### 3.2 信息存储的期限
**3.2.1** 我们将仅在为提供本平台及相关服务之目的所必需的期间内保留您的用户信息,但您理解并认可基于不同的服务及其功能需求,必要存储期限可能会有所不同。我们用于确定存储期限的标准包括:
(1) 完成该业务目的需要留存用户信息的时间,包括提供服务,依据法律要求维护相应的交易及业务记录,保证系统和服务的安全,应对可能的用户查询或投诉、问题定位等;
(2) 用户同意的更长的留存期间;
(3) 法律、合同等对保留用户信息的特殊要求等。
**3.2.2** 在您未撤回授权同意、删除或注销账号期间,我们会保留相关信息。超出必要期限后,我们将对您的信息进行删除或匿名化处理,**前述情况若法律法规有强制留存要求的情况下,即使您注销您的账户或要求删除您的用户信息,我们亦无法删除或匿名化处理您的用户信息。**
## 4.我们如何共享、转让、公开披露您的信息
### 4.1 数据使用过程中涉及的合作方
**4.1.1** 原则
(1) 合法原则:与合作方合作过程中涉及数据使用活动的,必须具有合法目的、符合法定的合法性基础。如果合作方使用信息不再符合合法原则,则其不应再使用您的用户信息,或在获得相应合作性基础后再行使用。
(2) 正当与最小必要原则:数据使用必须具有正当目的,且应以达成目的必要为限。
(3) 安全审慎原则:我们将审慎评估合作方使用数据的目的,对这些合作方的安全保障能力进行综合评估,并要求其遵循合作法律协议。我们会对合作方获取信息的软件工具开发包(SDK)、应用程序接口(API)进行严格的安全监测,以保护数据安全。
**4.1.2** 委托处理
对于委托处理用户信息的场景,我们会与受托合作方根据法律规定签署相关处理协议,并对其用户信息使用活动进行监督。
**4.1.3** 共同处理
对于共同处理用户信息的场景,我们会与合作方根据法律规定签署相关协议并约定各自的权利和义务,确保在使用相关用户信息的过程中遵守法律的相关规定、保护数据安全。
**4.1.4** 合作方的范围
若具体功能和场景中涉及由我们的关联方、第三方提供服务,则合作方范围包括我们的关联方与第三方。
### 4.2 用户信息共同数据处理或数据委托处理的情形
**4.2.1** 本平台及相关服务功能中的某些具体模块或功能由合作方提供,对此您理解并同意,在我们与任何合作方合作中,我们仅会基于合法、正当、必要及安全审慎原则,在为提供服务所最小的范围内向其提供您的用户信息,并且我们将努力确保合作方在使用您的信息时遵守本隐私政策及我们要求其遵守的其他适当的保密和安全措施,承诺不得将您的信息用于其他任何用途。
**4.2.2** 为提供更好的服务,我们可能委托合作方向您提供服务,包括但不限于客户服务、支付功能、实名认证、技术服务等,因此,为向您提供服务所必需,我们会向合作方提供您的某些信息。例如:
(1) 为进行用户实名认证在您使用身份认证的功能或相关服务所需时,根据相关法律法规的规定及相关安全保障要求可能需要完成实名认证以验证您的身份。在实名认证过程中,与我们合作的认证服务机构可能需要使用您的真实姓名、身份证号码、手机号码等。
(2) 支付功能由与我们合作的第三方支付机构向您提供服务。第三方支付机构为提供功能可能使用您的姓名、银行卡类型及卡号、有效期、身份证号码及手机号码等。
(3) 为及时处理您的投诉、建议以及其他诉求,我们的客户服务提供商(若有)可能需要使用您的账号及所涉及的事件的相关信息,以及时了解、处理和相应相关问题。
**4.2.3** 为保障服务安全与分析统计的数据使用
(1) 保障使用安全:我们非常重视账号与服务安全,为保障您和其他用户的账号与财产安全,使您和我们的正当合法权益免受不法侵害,我们和我们的合作方可能需要使用必要的设备、账号及日志信息。
(2) 分析服务使用情况:为分析我们服务的使用情况,提升用户使用的体验,我们和我们的合作方可能需要使用您的服务使用情况(崩溃、闪退)的统计性数据,这些数据难以与其他信息结合识别您的身份或与您的身份相关联。
### 4.3 用户信息的转移
我们不会转移您的用户信息给任何其他第三方,但以下情形除外:
**4.3.1** 基于您的书面请求,并符合国家网信部门规定条件的,我们会向您提供转移的途径。
**4.3.2** 获得您的明确同意后,我们会向其他第三方转移您的用户信息。
**4.3.3** 在涉及本平台运营主体变更、合并、收购或破产清算时,如涉及到用户信息转移,我们会依法向您告知有关情况,并要求新的持有您的信息的公司、组织继续接受本隐私政策的约束或按照不低于本隐私政策所要求的安全标准继续保护您的信息,否则我们将要求该公司、组织重新向您征求授权同意。如发生破产且无数据承接方的,我们将对您的信息做删除处理。
### 4.4 用户信息的公开披露
**4.4.1** 原则上我们不会公开披露您的用户信息,除非获得您明确同意或遵循国家法律法规规定的披露。
(1) 获得您明确同意或基于您的主动选择,我们可能会公开披露您的用户信息;
(2) 为保护您或公众的人身财产安全免遭侵害,我们可能根据适用的法律或本平台相关协议、规则披露关于您的用户信息。
**4.4.2** 征得授权同意的例外
请您理解,在下列情形中,根据法律法规及相关国家标准,我们收集和使用您的用户信息不必事先征得您的授权同意:
(1) 与我们履行法律法规规定的义务相关的;
(2) 与国家安全、国防安全直接相关的;
(3) 与公共安全、公共卫生、重大公共利益直接相关的;
(4) 与刑事侦查、起诉、审判和判决执行等直接相关的;
(5) 出于维护您或他人的生命、财产等重大合法权益但又很难得到本人授权同意的;
(6) 您自行向社会公众公开的信息;
(7) 根据用户信息主体要求签订和履行合同所必需的;
(8) 从合法公开披露的信息中收集的您的信息的,如合法的新闻报道、政府信息公开等渠道;
(9) 用于维护软件及相关服务的安全稳定运行所必需的,例如发现、处置软件及相关服务的故障;
(10) 为开展合法的新闻报道所必需的;
(11) 为学术研究机构,基于公共利益开展统计或学术研究所必要,且对外提供学术研究或描述的结果时,对结果中所包含的个人信息进行去标识化处理的;
(12) 法律法规规定的其他情形。
特别提示您注意,如信息无法单独或结合其他信息识别到您的个人身份,其不属于法律意义上您的个人信息;当您的信息可以单独或结合其他信息识别到您的个人身份时,这些信息在结合使用期间,将作为您的用户信息按照本隐私政策处理与保护。
## 5. 我们如何保护您的信息安全
我们非常重视用户信息的安全,将努力采取合理的安全措施(包括技术方面和管理方面)来保护您的信息,防止您提供的信息被不当使用或未经授权的情况下被访问、公开披露、使用、修改、损坏、丢失或泄漏。 我们会使用不低于行业通行的加密技术、匿名化处理等合理可行的手段保护您的信息,并使用安全保护机制尽可能地降低您的信息遭到恶意攻击的可能性。
我们会有专门的人员和制度保障您的信息安全。我们采取严格的数据使用和访问制度。尽管已经采取了上述合理有效措施,并已经遵守了相关法律规定要求的标准,但请您理解,由于技术的限制以及可能存在的各种恶意手段,在互联网行业,即便竭尽所能加强安全措施,也不可能始终保证信息百分之百的安全,我们将尽力确保您提供给我们的信息的安全性。您知悉并理解,您接入我们的服务所用的系统和通讯网络,有可能因我们可控范围外的因素而出现问题。因此,我们强烈建议您采取积极措施保护用户信息的安全,包括但不限于使用复杂密码、定期修改密码、不将自己的账号密码等信息透露给他人。
我们会制定应急处理预案,并在发生用户信息安全事件时立即启动应急预案,努力阻止该等安全事件的影响和后果扩大。一旦发生用户信息安全事件(泄露、丢失等)后,我们将按照法律法规的要求,及时向您告知:安全事件的基本情况和可能的影响、我们已经采取或将要采取的处置措施、您可自主防范和降低风险的建议、对您的补救措施等。我们将及时将事件相关情况以推送通知、邮件、信函或短信等形式告知您,难以逐一告知时,我们会采取合理、有效的方式发布公告。同时,我们还将按照相关监管部门要求,上报用户信息安全事件的处置情况。
我们谨此特别提醒您,本隐私政策提供的用户信息保护措施仅适用于本平台及相关服务。一旦您离开本平台及相关服务,浏览或使用其他网站、产品、服务及内容资源,我们即没有能力及义务保护您在本平台及相关服务之外的软件、网站提交的任何信息,无论您登录、浏览或使用上述软件、网站是否基于本平台的链接或引导。
## 6. 我们如何管理您的用户信息
我们非常重视对用户信息的管理,并依法保护您对于您信息的查阅、复制、更正、补充、删除以及撤回授权同意、注销账号、投诉举报等权利,以使您有能力保障您的隐私和信息安全。
### 6.1 您在用户信息处理活动中的权利
**6.1.1** 一般情况下,您可以查阅、复制、更正、补充、访问、修改、删除您主动提供的用户信息。
**6.1.2** 在以下情形中,您可以向我们提出删除用户信息的请求:
(1) 如果处理目的已实现、无法实现或者为实现处理目的不再必要;
(2) 如果我们处理用户信息的行为违反法律法规;
(3) 如果我们收集、使用您的用户信息,却未征得您的同意;
(4) 如果我们处理用户信息的行为违反了与您的约定;
(5) 如果我们停止提供产品或者服务,或用户信息的保存期限已届满;
(6) 如果您撤回同意授权;
(7) 如果我们不再为您提供服务;
(8) 法律、行政法规规定的其他情形。
### 6.2 撤回或改变您授权同意的范围
**6.2.1** 您理解并同意,每项服务均需要一些基本用户信息方得以完成。除为实现业务功能收集的基本用户信息外,对于额外收集的用户信息的收集和使用,您可以选择撤回您的授权,或改变您的授权范围。您也可以通过注销账号的方式,撤回我们继续收集您用户信息的全部授权。
**6.2.2** 您理解并同意,当您撤回同意或授权后,将无法继续使用与撤回的同意或授权所对应的服务,且本平台也不再处理您相应的用户信息。但您撤回同意或授权的决定,不会影响此前基于您的授权而开展的用户信息处理。
### 6.3 如何获取您的用户信息副本
我们将根据您的书面请求,为您提供以下类型的用户信息副本:您的基本资料、用户身份信息。但请注意,我们为您提供的信息副本仅以我们直接收集的信息为限。
### 6.4 响应您的请求
您享有注销账号、举报或投诉的权利。为保障安全,您可能需要提供书面请求,并以其它方式证明您的身份。 对于您合理的请求,我们原则上不收取费用。但对多次重复、超出合理限度的请求,我们将视具体情形收取一定成本费用。对于那些无端重复、需要过多技术手段(例如,需要开发新系统或从根本上改变现行惯例)、给他人合法权益带来风险或者不切实际(例如,涉及备份磁带上存放的信息)的请求,我们可能会予以拒绝。
您理解并认可,在以下情形中,我们将无法响应您的请求:
(1) 与我们履行法律法规规定的义务相关的;
(2) 与国家安全、国防安全直接相关的;
(3) 与公共安全、公共卫生、重大公共利益直接相关的;
(4) 与刑事侦查、起诉、审判和执行判决等直接相关的;
(5) 我们有充分证据表明用户信息主体存在主观恶意或滥用权利的;
(6) 出于维护用户信息主体或其他个人的生命、财产等重大合法权益但又很难得到本人同意的;
(7) 响应用户信息主体的请求将导致用户信息主体或其他个人、组织的合法权益受到严重损害的;
(8) 涉及商业秘密的。
### 6.5 停止运营向您告知
如我们停止运营,我们将停止收集您的用户信息,并将停止运营的通知以逐一送达或公告等商业上可行的形式通知您,并对我们所持有的您的用户信息进行删除或匿名化处理。
## 7. 未成年人使用条款
我们的服务主要面向企业或相关组织。未成年人(不满十四周岁)不应创建任何账户或使用本平台及其服务。如果我们发现在未事先获得可证实的监护人同意的情况下提供了用户信息,经未成年人的监护人书面告知后我们会设法尽快删除相关信息。
## 8. 隐私政策的修订和通知
为了给您提供更好的服务,本平台及相关服务将不时更新与变化,我们会适时对本隐私政策进行修订,该等修订构成本隐私政策的一部分并具有等同于本隐私政策的效力。但未经您明确同意,我们不会严重减少您依据当前生效的隐私政策所应享受的权利。
本隐私政策更新后,我们会在本平台公布更新版本,并在更新后的条款生效前通过官方网站公告或其他适当的方式提醒您更新的内容,以便您及时了解本隐私政策的最新版本。如您继续使用本平台及相关服务,视为您同意接受修订后的本隐私政策的全部内容。
对于重大变更,我们还会提供更为显著的通知(包括但不限于电子邮件、短信、系统消息或在浏览页面做特别提示等方式),向您说明本隐私政策的具体变更。
本隐私政策所指的重大变更包括但不限于:
(1) 我们的服务模式发生重大变化。如处理用户信息的目的、处理用户信息的类型、用户信息的使用方式等;
(2) 我们在所有权结构、组织架构等方面发生重大变化。如业务调整、破产并购等引起的所有变更等;
(3) 用户信息传输、转移或公开披露的主要对象发生变化;
(4) 您参与用户信息处理方面的权利及其行使方式发生重大变化;
(5) 我们的联络方式及投诉渠道发生变化时。
## 9. 适用范围
本隐私政策适用于本平台提供产品、服务、解决方案以及公司后续可能不时推出的纳入服务范畴内的其他产品、服务或解决方案。
本隐私政策不适用于有单独的隐私政策且未纳入本隐私政策的第三方通过本平台向您提供的产品或服务(**“第三方服务”**)。您使用这些第三方服务(包括您向这些第三方提供的任何含用户信息在内的信息),将受这些第三方的服务条款及隐私政策约束(而非本隐私政策),并通过其建立的用户信息主体请求和投诉等机制,提出相关请求、投诉举报,具体规定请您仔细阅读第三方的条款。请您妥善保护自己的用户信息,仅在必要的情况下向第三方提供。
需要特别说明的是,作为本平台的用户,若您利用本平台的技术服务,为您的用户再行提供服务,因您与客户的业务合作所产生的数据属于您所有,您应当与您的用户自行约定相关隐私政策,本隐私政策不作为您与您的用户之间的隐私政策的替代。
***
1 ↩
| 核心对比项目 | 用户信息 | 交互数据 |
| ------- | ------------------------------- | -------------------------- |
| 平台使用/披露 | 法律许可且基于提供平台功能的目的,
平台可使用或披露 | 除法律强制要求,平台不会非授权
使用或披露 |
| 存储 | 平台按相关法律要求存储 | 用户应自行存储,平台无义务存储 |
# 用户充值协议
Source: https://docs.siliconflow.cn/cn/legals/recharge-policy
更新日期:2025年3月5日
尊敬的用户,为保障您的合法权益,请您在点击“确认支付”按钮前,完整、仔细地阅读本充值协议,当您点击“确认支付”按钮,即表示您已阅读、理解本协议内容,并同意按照本协议约定的规则进行充值和使用余额行为。如您不接受本协议的部分或全部内容,请您不要点击“确认支付”按钮。
## 1. 接受条款
欢迎您使用SiliconCloud平台。以下所述条款和条件为平台充值的用户(以下简称“用户“或“您“)和北京硅基流动科技有限公司(以下简称“硅基流动”)就充值以及余额使用所达成的协议。
当您以在线点击“确认支付”等方式确认本协议或实际进行充值时,即表示您已理解本协议内容并同意受本协议约束,包括但不限于本协议正文及所有硅基流动已经发布的或将来可能发布的关于服务的各类规则、规范、公告、说明和(或)通知等,以及其他各项网站规则、制度等。所有前述规则为本协议不可分割的组成部分,与协议正文具有同等法律效力。
硅基流动有权根据国家法律法规的变化以及实际业务运营的需要不时修改本协议相关内容,并提前公示于软件系统、网站等以通知用户。修改后的条款应于公示通知指定的日期生效。如果您选择继续充值即表示您同意并接受修改后的协议且受其约束;如果您不同意我们对本协议的修改,请立即放弃充值或者停止使用本服务。
请注意,本协议限制了硅基流动的责任,还限制了您的责任,具体条款将以加粗并加下划线的形式提示您注意,硅基流动督促您仔细阅读。如果您对本协议的条款有疑问的,请通过客服渠道(电子邮箱:[contact@siliconflow.cn](mailto:contact@siliconflow.cn))进行询问,硅基流动将向您解释条款内容。如果您不同意本协议的任意内容,或者无法准确理解硅基流动对条款的解释,请不要同意本协议或使用本协议项下的服务。
## 2. 定义
**2.1** SiliconCloud平台个人充值余额账户:简称“充值余额账户”,指由硅基流动根据用户的SiliconCloud平台账户为用户自动配置的资金账户。用户向该账户充值的行为视为用户向硅基流动预付服务费,预付服务费可用于购买SiliconCloud平台提供的产品或服务。
## 3. 充值条件
当您充值时,您应该具有经实名认证成功后的SiliconCloud平台账户。
## 4. 账户安全
**4.1** 当用户进行充值时,用户应仔细确认自己的账号及信息,若因为用户自身操作不当、不了解或未充分了解充值计费方式等因素造成充错账号、错选充值种类等情形而损害自身权益,应由用户自行承担责任。
**4.2** 用户在充值时使用第三方支付企业提供的服务的,应当遵守与该第三方的各项协议及其服务规则;在使用第三方支付服务过程中用户应当妥善保管个人信息,包括但不限于银行账号、密码、验证码等;用户同意并确认,硅基流动对因第三方支付服务产生的纠纷不承担任何责任。
## 5. 充值方式
**5.1** 用户充值可以选择硅基流动认可的第三方支付企业(目前支持微信支付)支付充值金额。
**5.2** 用户如委托第三方对其消耗账户充值,则用户承诺并保证其了解和信任第三方,且第三方亦了解和同意接受用户委托,为用户充值;否则,如硅基流动被第三方告知该等充值非经第三方同意,则硅基流动有权立即封禁用户的 SiliconCloud 账户(账户封禁期间,硅基流动将暂停用户使用本平台服务,包括不限于用户的 API 请求或任何线上功能,下同)。自用户的消耗账户被封禁之日起30日内,用户应提供充足证据证实第三方事先同意为其充值,否则用户同意并授权硅基流动配合第三方的要求,自用户被锁定的消耗账户中将相应款项退还第三方。如届时用户的消耗账户余额不足以退还,则短缺部分,用户同意最晚在30日内充值相应金额,委托硅基流动退还,或自其微信账户或支付宝账户自行退还,除非第三方同意用户可不退还这部分款项。
**5.3** 用户承诺并保证用于其充值余额账户充值的资金来源的合法性,否则硅基流动有权配合司法机关或其他政府主管机关的要求,对用户的 SiliconCloud 账户进行相应处理,包括但不限于封禁用户的 SiliconCloud 账户等。
## 6. 充值余额和赠送余额
**6.1** 充值余额,是指您进行在线充值并实际支付的金额(人民币),不包括任何形式的赠送金额,可在SiliconCloud 平台消耗使用。
**6.2** 赠送余额,是指根据 SiliconCloud 平台不时推出的充值优惠运营活动,在充值余额以外、额外赠予的金额(包括但不限于邀请奖励等)。赠送余额不可提现、不可转让,不可开具发票。赠送余额将依据对应的活动规则发放并依据平台服务规则使用,硅基流动对赠送金额的可用范围享有最终解释权。
## 7. 充值余额使用
**7.1** 您充值后,充值余额的使用不设有效期,不能转移、转赠。因此,请您根据自己的消耗情况选择充值金额,硅基流动对充值次数不做限制。
**7.2** 充值成功后,通常您可以立即开始使用相应产品(或服务),部分情况下可能存在延迟到账的情况,若较长时间仍未到账您可通过客服渠道(电子邮箱:[contact@siliconflow.cn](mailto:contact@siliconflow.cn))联系硅基流动的服务支持人员为您处理。
## 8. 发票
硅基流动将在您的充值金额消耗后,按照实际消耗金额,根据您订购的产品(或服务)协议开具相应发票。
## 9. 关于退款
**9.1** 您应充分预估实际需求并确定充值金额。
**9.2** 若您使用在线支付方式(目前为微信支付),通过第三方支付企业进行充值,充值完成后 360 日内,对于尚未消费的余额您可自行操作退款。硅基流动及其合作第三方支付企业将对用户的退款操作进行审核,若审核通过将会按照原支付路径退回,并可能产生相应手续费。
**9.3** 原则上,您的每一笔在线支付充值仅支持一次退款。如遇特殊情况,您可通过客服渠道(电子邮箱:[contact@siliconflow.cn](mailto:contact@siliconflow.cn))联系硅基流动的服务支持人员为您处理。
**9.4** 您通过对公转账或其他方式充值的金额,不支持自助退款,您可通过客服渠道(电子邮箱:[contact@siliconflow.cn](mailto:contact@siliconflow.cn))联系硅基流动的服务支持人员,配合提供相关证明材料,硅基流动将在审核完成后将应退金额返回给用户,并可能产生相应手续费。
**9.5** 赠送余额(包括但不限于邀请奖励及同类非现金折扣等)不支持申请退款。
**9.6** 您完成充值并已经消耗的或根据相关产品(或服务)协议应予扣除的,将不予退还。
## 10. 争议解决
本协议适用中华人民共和国大陆地区法律。用户如因本协议与硅基流动发生争议的,双方应首先友好协商解决,如协商不成的,该等争议将由北京市海淀区人民法院管辖。
# 用户协议
Source: https://docs.siliconflow.cn/cn/legals/terms-of-service
更新日期:2025年02月27日
这是您与北京硅基流动科技有限公司及其关联方(**“硅基流动”**或**“我们”**)之间的协议(**“本协议”**),您确认:在您开始试用或购买我们 **SiliconCloud**平台(**本平台**)的产品或服务前,您已充分阅读、理解并接受本协议的全部内容,**一旦您选择“同意”并开始使用本服务或完成购买流程,即表示您同意遵循本协议之所有约定。不具备前述条件的,您应立即终止注册或停止使用本服务**。如您与我们已就您使用本平台服务事宜另行签订其他法律文件,则本协议与该等法律文件冲突的部分对您不适用。**另本平台的详细数据使用政策请见《隐私政策》。**
## 1. 账户管理
**1.1** 您保证自身具有法律规定的完全民事权利能力和民事行为能力,是能够独立承担民事责任的自然人或法人;本协议内容不会被您所属国家或地区的法律禁止。您知悉,**无民事行为能力人、限制民事行为能力人(本平台指十四周岁以下的未成年人)不当注册为平台用户的,其与平台之间的服务协议自始无效,一经发现,平台有权立即停止为该用户服务或注销该用户账号。**
**1.2 账户**
1.2.1 在您按照本平台的要求填写相关信息并确认同意履行本协议的内容后,我们为您注册账户并开通本平台的使用权限,您的账户仅限您本人使用并使您能够访问某些服务和功能,我们可能根据我们的独立判断不时地修改和维护这些服务和功能。
1.2.2 个人可代表公司或其他实体访问和使用本平台,在这种情况下,本协议不仅在我们与该个人之间的产生效力,亦在我们与该等公司或实体之间产生效力。
1.2.3 如果您通过第三方连接/访问本服务,即表明允许我们访问和使用您的信息,并存储您的登录凭据和访问令牌。
1.2.4 账户安全。当您创建帐户时,您有权使用您设置或确认的手机号码及您设置的密码登陆本平台。**我们建议您使用强密码(由大小写字母、数字和符号组合而成的密码)来保护您的帐户。** 您的账户由您自行设置并由您保管,本平台在任何时候均不会主动要求您提供您的账户密码。因此,建议您务必保管好您的账户,**若账户因您主动泄露或因您遭受他人攻击、诈骗等行为导致的损失及后果,本平台不承担责任,您应通过司法、行政等救济途径向侵权行为人追偿。** 您向我们提供您的电子邮件地址作为您的有效联系方式,即表明您同意我们使用该电子邮件地址向您发送相关通知,请您务必及时关注。
1.2.5 账户删除。您应通过本平台指定的方式提交账号注销申请,并按照系统提示填写相关信息,包括但不限于账号ID、注册手机号、注销原因等,以便本平台核实身份。如审核通过,本平台将通过短信向您发送账号注销通知;如审核不通过,本平台将通过短信告知您原因。自账号注销通知送达您之日起,您将无法再登陆并使用该账号,账号相关的所有权益立即终止。账号注销后,本平台将按照法律法规的要求对您在平台上留存的信息进行删除,但法律法规另有规定或双方另有约定的除外。
**1.3** 变更、暂停和终止。**我们**在尽最大努力以本平台公告、站内信、邮件或短信等一种或多种方式进行事先通知的情况下,**我们可以变更、暂停或终止向您提供服务,或对服务设置使用限制,而无需承担责任。可以在任何时候停用您的帐户**。即便您的账户因任何原因而终止后,您将继续受本协议的约束。
**1.4** 在法律有明确规定要求的情况下,本平台作为平台服务提供者若必须对用户的信息进行核实的情况下,本平台将依法不时地对您的信息进行检查核实,您应当配合提供最新、真实、完整、有效的信息。**若本平台无法依据您提供的信息进行核验时,本平台可向您发出询问或要求整改的通知,并要求您进行重新认证,直至中止、终止对您提供部分或全部平台服务,本平台对此不承担任何责任。**
**1.5** 您应当为自己与其他用户之间的交互、互动、交流、沟通负责。我们保留监督您与其他用户之间争议的权利。我们不因您与其他用户之间的互动以及任何用户的作为或不作为而承担任何责任,包括与**交互数据**(定义见下文)相关的责任。
## 2. 访问服务及服务限制
**2.1** 访问服务。在您遵守本协议的前提下,您在此被授予非排他性的、不可转让的访问和使用本服务的权利,仅用于您个人使用或您代表的公司或其他实体内部业务目的。我们保留本协议中未明确授予的所有权利。
**2.2 服务限制**
2.2.1 对服务的任何部分进行反汇编、反向工程、解码或反编译;
2.2.2 将本服务上或通过本服务提供的任何内容(包括任何标题信息、关键词或其他元数据)用于任何机器学习和人工智能培训或开发目的,或用于旨在识别自然人身份的任何技术;
2.2.3 未经我们事先书面同意,购买、出售或转让API密钥;
2.2.4 复制、出租、出售、贷款、转让、许可或意图转授、转售、分发、修改本服务任何部分或我们的任何**知识产权**(定义见下文);
2.2.5 采取可能对我们的服务器、基础设施等造成不合理的巨大负荷的任何行为;
**2.2.6 以下列任何方式或目的使用本平台服务:(i)反对宪法所确定的基本原则的;(ii)危害国家安全,泄露国家秘密,颠覆国家政权,破坏国家统一的;(iii)损害国家荣誉和利益的;(iv)煽动地域歧视、地域仇恨的;(v)煽动民族仇恨、民族歧视,破坏民族团结的;(vi)破坏国家宗教政策,宣扬邪教和封建迷信的;(vii)散布谣言,扰乱社会秩序,破坏社会稳定的;(viii)散布淫秽、色情、赌博、暴力、凶杀、恐怖或者教唆犯罪的;(ix)侮辱或者诽谤他人,侵害他人合法权益的;(x)煽动非法集会、结社、游行、示威、聚众扰乱社会秩序的;(xi)以非法民间组织名义活动的(xii) 有可能涉及版权纠纷的非本人作品的;(xiii)有可能侵犯他人在先权利的;(xiv)对他人进行暴力恐吓、威胁,实施人肉搜索的;(xv)涉及他人隐私、个人信息或资料的;(xvi)侵犯他人隐私权、名誉权、肖像权、知识产权等合法权益内容的;(xvii) 侵害未成年人合法权益或者损害未成年人身心健康的(xviii)未获他人允许,偷拍、偷录他人,侵害他人合法权利的;(xix)违反法律法规底线、社会主义制度底线、国家利益底线、公民合法权益底线、社会公共秩序底线、道德风尚底线和信息真实性底线的“七条底线”要求的;(xx)相关法律、行政法规等禁止的。**
2.2.7 绕开我们可能用于阻止或限制访问服务的措施,包括但不限于阻止或限制使用或复制任何内容或限制使用服务或其任何部分的功能;
2.2.8 试图干扰、破坏运行服务的服务器的系统完整性或安全性,或破译与运行服务的服务器之间的任何传输;
2.2.9 使用本服务发送垃圾邮件、连锁信或其他未经请求的电子邮件;
2.2.10 通过本服务传输违法数据、病毒或其他软件代理;
2.2.11 冒充他人或实体,歪曲您与某人或实体的关系,隐藏或试图隐藏您的身份,或以其他方式为任何侵入性或欺诈性目的使用本服务;或从本服务收集或获取包括用户姓名在内的任何个人信息。
2.2.12 从本服务收集或获取包括但不限于其他用户姓名在内的任何个人信息。
2.2.13 其他未经我们明示授权的行为或可能损害我们利益的使用方式。
## 3. 交互数据
**3.1** 本服务可能允许用户在注册后,基于平台使用目的在使用模型过程中与开源模型、第三方网站、软件、应用程序或服务之间进行输入、反馈、修正、加工、存储、上传、下载、分发相关个人资料信息、视频、图像、音频、评论、问题和其他内容、文件、数据和信息(**“交互数据”**)。**本平台就详细数据使用政策请见本平台的《隐私政策》。**
**3.2** 如交互数据存在任何违反法律法规或本协议的情况,我们有权利删除或停止技术服务。
**3.3** 关于您的交互数据,您确认、声明并保证:
**3.3.1 在我们要求时,您能提供交互数据中包含的个人信息或需要获得授权后才能使用的信息的来源及其合法性提供书面说明或授权;如您超出授权范围或期限时,您应自行负责获得授权范围的扩大或延期。
3.3.2 您的交互数据,以及我们根据本协议对交互数据的使用,不会违反任何适用法律或侵犯任何第三方的任何权利,包括但不限于任何知识产权和隐私权;
3.3.3 您的交互数据不包括任何被政府机构视为敏感或保密的信息或材料,且您就本服务提供的交互数据不侵犯任何第三方的任何保密权利;
3.3.4 您不会上传或通过本服务直接或通过其他方式提供14岁以下儿童的任何个人信息;
3.3.5 您的交互数据不包括裸体或其他性暗示内容;不包括对个人或团体的仇恨言论、威胁或直接攻击;不包括辱骂、骚扰、侵权、诽谤、低俗、淫秽或侵犯他人隐私的内容;不包括性别歧视或种族、民族或其他歧视性内容;不包括含有自残或过度暴力的内容;不包括伪造或冒名顶替的档案;不包括非法内容或助长有害或非法活动的内容;不包括恶意程式或程式码;不包括未经本人同意的任何人的个人信息;不包括垃圾邮件、机器生成的内容或未经请求的信息及其他令人反感的内容;**
3.3.6 据您所知,您提供给我们的所有交互数据和其他信息都是真实和准确的。
**3.4 本平台作为独立的技术支持者,您利用本平台接入大模型所产生的全部交互数据及义务和责任均由您承担,本平台不对由此造成的任何损失负责。**
**3.5 本平台作为独立的技术支持者,您利用本平台向任何第三方提供服务,相应的权利义务和责任均由您承担,本平台不对由此造成的任何损失负责。**
**3.6 免责声明。我们对任何交互数据概不负责。您将对您输入、反馈、修正、加工、存储、上传、下载、分发在本平台及模型服务上的交互数据负责并承担全部责任。本平台提供的技术服务只会严格执行您的指示处理您的交互数据,除非法律法规另有规定、依据特定产品规则另行约定或基于您的要求为您提供技术协助进行故障排除或解决技术问题,我们不会访问您的交互数据,您理解并认同我们及本平台只是作为交互数据的被动技术支持者或渠道,对于交互数据我们没有义务进行存储,亦不会对您的交互数据进行任何非授权的使用或披露。同时我们仅在合法合规的基础上且基于向您提供本平台服务的前提下使用您的交互数据。**
## 4. 知识产权
**4.1** 定义。就本协议而言,“知识产权”系指所有专利权、著作权、精神权利、人格权、商标权、商誉、商业秘密权、技术、信息、资料等,以及任何可能存在或未来可能存在的知识产权和所有权,以及根据适用法律提出的所有申请中、已注册、续期的知识产权。
**4.2** 硅基流动知识产权。您理解并承认,我们拥有并将持续拥有本服务的所有权利(包括知识产权),您不得访问、出售、许可、出租、修改、分发、复制、传输、展示、发布、改编、编辑或创建任何该等知识产权的衍生作品。严禁将任何知识产权用于本协议未明确许可的任何目的。本协议中未明确授予您的权利将由硅基流动保留。
**4.3** 输出。在您遵守如下事项且在合法合规的基础上,可以将大模型产出的结果进行使用:(i)您对服务和输出的使用不会转移或侵犯任何知识产权(包括不会侵犯硅基流动知识产权和其他第三方知识产权);(ii)如果我们酌情认为您对输出的使用违反法律法规或可能侵犯任何第三方的权利,我们可以随时限制您对输出的使用并要求您停止使用输出(并删除其任何副本);(iii)您不得表示大模型的输出结果是人为生成的;(iv)您不得违反任何模型提供商的授权许可或使用限制。
您同意,我们不对您或任何第三方声称因由我们提供的技术服务而产生的任何输出内容或结果承担任何责任。
**4.4 用户使用数据。我们可能会收集或您可能向我们提供诊断、技术、使用的相关信息,包括有关您的计算机、移动设备、系统和软件的信息(“用户使用数据”)。我们可能出于平台维护运营的需要,且在法律许可的范围内使用、维护和处理用户使用数据或其中的任何部分,包括但不限于:(a)提供和维护服务;(b)改进我们的产品和服务或开发新的产品或服务1。详细数据使用政策请见本平台的《隐私政策》。**
**4.5** 反馈。 如果您向我们提供有关本服务或任何其他硅基流动产品或服务的任何建议或反馈(**“反馈”**),则您在此将所有对反馈的权益转让给我们,我们可自由使用反馈以及反馈中包含的任何想法、专有技术、概念、技术和知识产权。反馈被视为我们的**保密信息**(定义如下)。
## 5. 保密信息
本服务可能包括硅基流动和其他用户的非公开、专有或保密信息(**“保密信息”**)。保密信息包括任何根据信息的性质和披露情况应被合理理解为保密的信息,包括非公开的商业、产品、技术和营销信息。您将:(a)至少以与您保护自己高度敏感的信息相同的谨慎程度保护所有保密信息的隐私性,但在任何情况下都不得低于合理的谨慎程度;(b)除行使您在本协议下的权利或履行您的义务外,不得将任何保密信息用于任何目的;以及(c)不向任何个人或实体披露任何保密信息。
## 6. 计费政策及税费
您理解并同意,本平台提供的部分服务可能会收取使用费用、售后费用或其他费用(**“费用”**)。您通过选择使用本服务即表示您同意您注册网站上载明的适用于您的定价和付款条款(受限于我们的不时更新的定价/付款条件/充值协议等文件),您同意我们相应监控您的使用数据以便完成本服务计费。定价、付款条件和充值协议特此通过引用并入本协议。您同意,我们可能会添加新产品和/或服务的额外费用、增加或修改现有产品和/或服务的费用,我们可能会按照您的实际使用地点设定不同的价格费用,和/或停止随时提供任何服务。未经我们书面同意或本平台有其他相关政策,付款义务一旦发生不可取消,并且已支付的费用不予退还。如存在任何政府要求的税费,您将负责支付与您的所有使用/开通服务相关的税款。若您在购买服务时有任何问题,您可以通过[contact@siliconflow.cn](mailto:contact@siliconflow.cn)联系我们。
## 7. 隐私与数据安全
**7.1** 隐私。基于您注册以及开通相关服务时主动提供给本平台的相关信息(**“用户信息”**),且为了确保您正常使用本平台的相关服务,我们可能对您提供的用户信息进行收集、整理、使用,但我们将持续遵守《中华人民共和国个人信息保护法》及相关适用法律。
**7.2** 数据安全。我们关心您个人信息的完整性和安全性,然而,我们不能保证未经授权的第三方永远无法破坏我们的安全保护措施。
## 8. 使用第三方服务
本服务可能包含非我们拥有或控制的第三方网站、资料和服务(**“第三方服务”**)的链接,本服务的某些功能可能需要您使用第三方服务。我们不为任何第三方服务背书或承担任何责任。如果您通过本服务访问第三方服务或在任何第三方服务上共享您的交互数据,您将自行承担风险,并且您理解本协议不适用于您对任何第三方服务的使用。您明确免除我们因您访问和使用任何第三方服务而产生的所有责任。
## 9. 赔偿
您将为我们及我们的子公司和关联公司及各自的代理商、供应商、许可方、员工、承包商、管理人员和董事(**“硅基流动受偿方”**)进行辩护、赔偿并使其免受因以下原因而产生的任何和所有索赔、损害(无论是直接的、间接的、偶然的、后续的或其他的)、义务、损失、负债、成本、债务和费用(包括但不限于法律费用)的损害:(a)您访问和使用本服务,包括您对任何输出的使用;(b)您违反本协议的任何条款,包括但不限于您违反本协议中规定的任何陈述和保证;(c)您对任何第三方权利的侵犯,包括但不限于任何隐私权或知识产权;(d)您违反任何适用法律;(e)交互数据或通过您的用户账户提交的任何内容,包括但不限于任何误导性、虚假或不准确的信息;(f)您故意的或者存在重大过失的不当行为;或(g)任何第三方使用您的用户名、密码或其他认证凭证访问和使用本服务。
## 10. 免责声明
**您使用本服务的风险自负。我们明确否认任何明示、暗示或法定的保证、条件或其他条款,包括但不限于与适销性、适用于特定目的、设计、条件、性能、效用、所有权以及未侵权有关的保证、条件或其他条款。我们不保证服务将不中断或无错误运行,也不保证所有错误将得到纠正。此外,我们不保证服务或与使用服务相关的任何设备、系统或网络不会遭受入侵或攻击。
通过使用本服务下载或以其他方式获得的任何内容,其获取风险由您自行承担,您的计算机系统或移动设备的任何损坏和由于上述情况或由于您访问和使用本服务而导致的数据丢失,您应承担全部责任。此外,硅基流动不为任何第三方通过本服务或任何超链接网站或服务宣传或提供的任何产品或服务提供担保、背书、保证、推荐或承担责任,硅基流动不参与或以任何方式监控您与第三方产品或服务提供商之间的任何交易。**
## 11. 责任限制和免责
硅基流动在任何情况下均不对以下损害负责:(a)间接、偶发、示范性、特殊或后果性损害;或者(b)数据丢失或受损,或者业务中断或损失;或者(c)收入、利润、商誉或预期销量或收益损失,无论是在何种法律下,无论此种损害是否因使用或无法使用软件或其他产品引起,即使硅基流动已被告知此种损害的可能性。硅基流动及其关联方、管理人员、董事、员工、代理、供应商和许可方对您承担的所有责任(无论是因保证、合同或侵权(包括疏失))无论因何原因或何种行为方式产生,始终不超过您已支付给硅基流动的费用。本协议任何内容均不限制或排除适用法律规定不得限制或排除的责任。
## 12. 适用法律及争议解决条款
本协议受中华人民共和国(仅为本协议之目的,不包括香港特别行政区、澳门特别行政区及台湾地区)法律管辖。
若在执行本协议过程中如发生纠纷,双方应及时协商解决。协商不成时,我们与您任一方均有权提请北京仲裁委员会按照其届时有效仲裁规则进行仲裁,而此仲裁规则由此条款纳入本协议。仲裁语言为中文。仲裁地将为北京。仲裁结果为终局且对双方都有约束力。
## 13. 其他条款
**13.1** 可转让性。未经我们事先明确书面同意,您不得转让或转让本协议及本协议项下授予的任何权利和许可,但我们可无限制地转让。任何违反本协议的转让或让渡均属无效。
**13.2** 可分割性。如果本协议的某一条款或某一条款的一部分无效或不可执行,不影响本协议其他条款的有效性,无效或不可执行的条款将被视作已从本协议中删除。
**13.3** 不时修订。根据相关法律法规变化及硅基流动运营需要,我们将不时地对本协议进行修改,修改后的协议将替代修订前的协议。您在使用本平服务时,可及时查阅了解。如您继续使用本服务,则视为对修改内容的同意,当发生有关争议时,以最新的用户协议为准;您在不同意修改内容的情况下,有权停止使用本协议涉及的服务。
***
1 用户使用数据不同于交互数据。交互数据不保存、不披露,具体详见《隐私政策》。↩ |
# 更新公告
Source: https://docs.siliconflow.cn/cn/release-notes/overview
### 平台服务调整通知
为了进一步优化资源配置,提供更先进和优质的技术服务,平台将于 2025 年 7 月 3 日 对下列模型进行下线处理:
* Pro/deepseek-ai/DeepSeek-R1-0120
* Pro/deepseek-ai/DeepSeek-V3-1226
* Qwen/QwQ-32B-Preview
若您正在使用上述任一模型,建议您尽快切换到其他模型,以免服务受到影响。
### 平台维护预告
为提供更加丰富、先进、优质的服务,平台将于 2025 年 6 月 10 日 23 时至 11 日 8 时进行维护。
受系统维护影响:
1. cloud.siliconflow\.cn 将**暂停**注册、登录以及包括不限于下列功能的界面操作:
* 模型在线体验/微调/批量推理;
* 官网模型广场查看模型列表及详细信息;
* 在线充值、购买等级包、查询账单、开具发票等;
2. `/user/info` API 调整,`name` / `image` / `email` 字段将不再返回,固定输出空字符串;
平台 API 服务不受维护影响,可以持续调用,建议您提前关注账户余额,以免因为余额不足导致服务受限。
### 平台服务调整通知
SiliconCloud 将启动 `DeepSeek R1` 模型更新。
对于 `deepseek-ai/DeepSeek-R1` 和 `Pro/deepseek-ai/DeepSeek-R1` 模型,将“逐步“更新到最新 `0528` 版本。
更新完成后,上述两个款模型均为 `0528` 版本。如有需求,在 `2025 年 06 月 28` 日前,您仍可以通过 `Pro/deepseek-ai/DeepSeek-R1-0120` 使用旧版模型,以更平滑地完成业务切换。
### 平台服务调整通知
为了进一步优化资源配置,提供更先进和优质的技术服务,平台将于 2025 年 6 月 5 日 对下列模型进行下线处理:
* Qwen/Qwen2-1.5B-Instruct
* Pro/Qwen/Qwen2-1.5B-Instruct
* Pro/Qwen/Qwen2-VL-7B-Instruct
* THUDM/chatglm3-6b
* internlm/internlm2\_5-20b-chat
* deepseek-ai/DeepSeek-R1-Distill-Qwen-1.5B
* Pro/deepseek-ai/DeepSeek-R1-Distill-Qwen-1.5B
若您正在使用上述任一模型,建议您尽快切换到其他模型,以免服务受到影响。
### 平台服务调整通知
为了进一步优化资源配置,提供更先进和优质的技术服务,平台将于 2025 年 4 月 29 日 对 `HunyuanVideo` 模型(`非 HunyuanVideo-HD`)模型进行下线处理。
若您正在使用该模型,建议您尽快切换其他模型,以免服务受到影响。
### 平台服务调整通知
截止目前,`Pro/deepseek-ai/DeepSeek-V3` 和 `deepseek-ai/DeepSeek-V3` 模型已经更新至最新的 0324 版本。您仍可以通过 `Pro/deepseek-ai/DeepSeek-V3-1226` 使用旧版模型,以更平滑地完成业务切换。
### 平台服务调整通知
SiliconCloud 将启动 DeepSeek V3 模型更新。
对于 `deepseek-ai/DeepSeek-V3` 和 `Pro/deepseek-ai/DeepSeek-V3` 模型,将“逐步“更新到最新 `0324` 版本。
更新完成后,上述两个款模型均为 0324 版本。如有需求,在 2025 年 4 月 30 日前,您仍可以通过 `deepseek-ai/DeepSeek-V3-1226` 使用旧版模型,以更平滑地完成业务切换。
### 平台服务调整通知
为了更好的服务全球开发者用户,SiliconCloud 即将上线国际站,并逐步开设多个服务区域。
受此调整影响,现有`api.siliconflow.com API`端点将适时回收,请您尽快切换为`api.siliconflow.cn`继续使用。
我们已经为`.cn`端点配置了全球访问加速(GTM),使其与当前的`.com`端点具有相同的全球接入体验,您只需要将 API 请求的`base URL`修改为`api.siliconflow.cn`即可。
我们建议您在`本月底(3 月 31 日)`前完成迁移,如有任何疑问,请随时联系我们。
### 平台服务调整通知
为持续提升用户体验,现调整 Rate Limits 策略如下:
去掉 deepseek-ai/DeepSeek-R1、deepseek-ai/DeepSeek-V3 的 RPH 和 RPD 限流
随着流量和负载变化,策略可能会不定时调整,硅基流动保留解释权。
### 平台服务调整通知
#### 1. 模型下线通知
为了进一步优化资源配置,提供更先进、优质、合规的技术服务,平台将于 2025 年 3 月 6 日 对部分模型进行下线处理。
具体涉及的模型列表如下:
* 对话模型
* AIDC-AI/Marco-o1
* meta-llama/Meta-Llama-3.1-8B-Instruct
* Pro/meta-llama/Meta-Llama-3.1-8B-Instruct
* meta-llama/Meta-Llama-3.1-70B-Instruct
* meta-llama/Meta-Llama-3.1-405B-Instruct
* meta-llama/Llama-3.3-70B-Instruct
* 生图模型
* black-forest-labs/FLUX.1-schnell
* Pro/black-forest-labs/FLUX.1-schnell
* black-forest-labs/FLUX.1-dev
* black-forest-labs/FLUX.1-pro
* stabilityai/stable-diffusion-xl-base-1.0
* stabilityai/stable-diffusion-3-5-large
* stabilityai/stable-diffusion-3-5-large-turbo
* stabilityai/stable-diffusion-2-1
* deepseek-ai/Janus-Pro-7B
* 语音模型
* fishaudio/fish-speech-1.5
* FunAudioLLM/SenseVoiceSmall
* fishaudio/fish-speech-1.4
* RVC-Boss/GPT-SoVITS
* 视频模型
* Lightricks/LTX-Video
* genmo/mochi-1-preview
### 平台服务调整通知
为保障平台服务质量与资源合理分配,现调整Rate Limits策略如下:
一、调整内容
1. 新增 RPH 限制(Requests Per Hour,每小时请求数)
* 模型范围:deepseek-ai/DeepSeek-R1、deepseek-ai/DeepSeek-V3
* 适用对象:所有用户
* 限制标准:30次/小时
2. 新增 RPD 限制(Requests Per Day,每日请求数)
* 模型范围:deepseek-ai/DeepSeek-R1、deepseek-ai/DeepSeek-V3
* 适用对象:未完成实名认证用户
* 限制标准:100次/天
随着流量和负载变化,策略可能会不定时调整,硅基流动保留解释权。
### 平台服务调整通知
#### 1. 模型下线通知
为了提供更稳定、高质量、可持续的服务,以下模型将于 **2025 年 02 月 27 日**下线:
* [01-ai/Yi-1.5-34B-Chat-16K](https://cloud.siliconflow.cn/models?target=01-ai/Yi-1.5-34B-Chat-16K)
* [01-ai/Yi-1.5-6B-Chat](https://cloud.siliconflow.cn/models?target=01-ai/Yi-1.5-6B-Chat)
* [01-ai/Yi-1.5-9B-Chat-16K](https://cloud.siliconflow.cn/models?target=01-ai/Yi-1.5-9B-Chat-16K)
* [stabilityai/stable-diffusion-3-medium](https://cloud.siliconflow.cn/models?target=stabilityai/stable-diffusion-3-medium)
* google/gemma-2-27b-it
* google/gemma-2-9b-it
* Pro/google/gemma-2-9b-it
如果您有使用上述模型,建议尽快迁移至平台上的其他模型。
### 平台服务调整通知
#### deepseek-ai/DeepSeek-V3 模型的价格于北京时间 2025年2月9日00:00 起恢复至原价
具体价格:
* 输入:¥2/ M Tokens
* 输出:¥8/ M Tokens
### 推理模型输出调整通知
推理模型思维链的展示方式,从之前的 `content` 中的 `` 独立成单独的单独的 `reasoning_content` 字段,兼容 `OpenAI` 和 `deepseek` api 规范,便于各个框架和上层应用在进行多轮会话时进行裁剪。使用方式详见[推理模型(DeepSeek-R1)使用](/capabilities/reasoning)。
### 平台服务调整通知
#### 支持deepseek-ai/DeepSeek-R1和deepseek-ai/DeepSeek-V3模型
具体价格如下:
* `deepseek-ai/DeepSeek-R1` 输入:¥4/ M Tokens 输出:¥16/ M Tokens
* `deepseek-ai/DeepSeek-V3`
* **即日起至北京时间 2025-02-08 24:00 享受限时折扣价**:输入:¥2¥1/ M Tokens 输出:¥8¥2/ M Tokens,2025-02-09 00:00恢复原价。
### 平台服务调整通知
#### 生成图片及视频 URL 有效期调整为 1 小时
为了持续为您提供更先进、优质的技术服务,从 2025 年 1 月 20 日起,大模型生成的图片、视频 URL 有效期将调整为 1 小时。
若您正在使用图片、视频生成服务,请及时做好转存工作,避免因 URL 过期而影响业务。
### 平台服务调整通知
#### LTX-Video 模型即将开始计费通知
为了持续为您提供更先进、优质的技术服务,平台将于 2025 年 1 月 6 日起对 Lightricks/LTX-Video 模型的视频生成请求进行计费,价格为 0.14 元 / 视频。
### 平台服务调整通知
#### 1. 模型下线通知
为了提供更稳定、高质量、可持续的服务,以下模型将于 **2024 年 12 月 19 日**下线:
* [deepseek-ai/DeepSeek-V2-Chat](https://cloud.siliconflow.cn/models?target=deepseek-ai/DeepSeek-V2-Chat)
* [Qwen/Qwen2-72B-Instruct](https://cloud.siliconflow.cn/models?target=Qwen/Qwen2-72B-Instruct)
* [Vendor-A/Qwen/Qwen2-72B-Instruct](https://cloud.siliconflow.cn/models?target=Vendor-A/Qwen/Qwen2-72B-Instruct)
* [OpenGVLab/InternVL2-Llama3-76B](https://cloud.siliconflow.cn/models?target=OpenGVLab/InternVL2-Llama3-76B)
如果您有使用上述模型,建议尽快迁移至平台上的其他模型。
### 平台服务调整通知
#### 1. 模型下线通知
为了提供更稳定、高质量、可持续的服务,以下模型将于 **2024 年 12 月 13 日**下线:
* [Qwen/Qwen2.5-Math-72B-Instruct](https://cloud.siliconflow.cn/models?target=Qwen/Qwen2.5-Math-72B-Instruct)
* [Tencent/Hunyuan-A52B-Instruct](https://cloud.siliconflow.cn/models?target=Tencent/Hunyuan-A52B-Instruct)
如果您有使用上述模型,建议尽快迁移至平台上的其他模型。
如果您有使用上述模型,建议尽快迁移至平台上的其他模型。
### 平台服务调整通知
#### 1. 模型下线通知
为了提供更稳定、高质量、可持续的服务,以下模型将于 **2024 年 11 月 22 日**下线:
* [deepseek-ai/DeepSeek-Coder-V2-Instruct](https://cloud.siliconflow.cn/models?target=deepseek-ai/DeepSeek-Coder-V2-Instruct)
* [Qwen/Qwen2-57B-A14B-Instruct](https://cloud.siliconflow.cn/models?target=Qwen/Qwen2-57B-A14B-Instruct)
* [Pro/internlm/internlm2\_5-7b-chat](https://cloud.siliconflow.cn/models?target=Pro/internlm/internlm2_5-7b-chat)
* [Pro/THUDM/chatglm3-6b](https://cloud.siliconflow.cn/models?target=Pro/THUDM/chatglm3-6b)
* [Pro/01-ai/Yi-1.5-9B-Chat-16K](https://cloud.siliconflow.cn/models?target=Pro/01-ai/Yi-1.5-9B-Chat-16K)
* [Pro/01-ai/Yi-1.5-6B-Chat](https://cloud.siliconflow.cn/models?target=Pro/01-ai/Yi-1.5-6B-Chat)
如果您有使用上述模型,建议尽快迁移至平台上的其他模型。
#### 2.邮箱登录方式更新
为进一步提升服务体验,平台将于 **2024 年 11 月 22 日起**调整登录方式:由原先的“邮箱账户 + 密码”方式更新为“**邮箱账户 + 验证码**”方式。
#### 3. 新增海外 API 端点
新增支持海外用户的平台端点:[https://api-st.siliconflow.cn](https://api-st.siliconflow.cn)。如果您在使用源端点 [https://api.siliconflow.cn](https://api.siliconflow.cn) 时遇到网络连接问题,建议切换至新端点尝试。
### 部分模型计价调整公告
为了提供更加稳定、优质、可持续的服务,[Vendor-A/Qwen/Qwen2-72B-Instruct](https://cloud.siliconflow.cn/models?target=17885302571) 限时免费模型将于 2024 年 10 月 17 日开始计费。计费详情如下:
* 限时折扣价:¥ 1.00 / M tokens
* 原价:¥ 4.13 / M tokens(恢复原价时间另行通知)
# 社区场景与应用
Source: https://docs.siliconflow.cn/cn/usercases/awesome-user-cases
# SiliconCloud 场景与应用案例
将 SiliconCloud 平台大模型能力轻松接入各类场景与应用案例
{/* ### 1. 应用程序集成 */}
{/* */}
{/*
SiliconCloud 团队
SiliconCloud 团队
SiliconCloud 团队
SiliconCloud 团队
*/}
{/*
Cherry Studio 团队
Chatbox 团队
*/}
{/* */}
### 1. 翻译场景使用
SiliconCloud 团队
沧海九粟
ohnny\_Van
mingupup
行歌类楚狂
### 2. 搜索与 RAG 场景使用
MindSearch 团队
LogicAI
白牛
沧海九粟
### 3. 编码场景使用
xDiexsel
野原广志2\_0
### 4. 分析场景使用
行歌类楚狂
### 5. 通讯场景使用
大大大维维
### 6. 生图场景使用
mingupup
baiack
糯.米.鸡
### 7. 使用评测
湖光橘鸦
自牧生
### 8. 开源项目
郭垒
laughing
### 9. 其它
mingupup
郭垒
free-coder
三千酱
# 302.AI
Source: https://docs.siliconflow.cn/cn/usercases/use-siliconcloud-in-302ai
## 1. 关于302.AI
302.AI是一个按需付费的AI应用平台,提供丰富的AI在线应用和全面的AI API接入。
302.AI和硅基流动进行合作,让302.AI的用户可以在302的平台内直接使用硅基流动的所有模型以及开箱即用的AI应用;也能让硅基流动的用户可以在302的平台内自定义接入硅基流动模型API,无需自己开发或部署。
## 2. 硅基流动用户如何在302.AI使用 SiliconCloud 模型
### 2.1 接入聊天机器人进行对话
#### 2.1.1 获取 SiliconCloud 的API Key 和模型 ID
(1)打开 SiliconCloud 官网 并注册账号(如果注册过,直接登录即可)。
(2)完成注册后,打开API密钥,创建新的 API Key,点击密钥进行复制,以备后续使用。
(3)在模型广场找到需接入的模型ID备用。
#### 2.1.2 设置自定义模型
(1)依次点击: **使用机器人 → 聊天机器人 → 模型**。
 (2)点击左下角的自定义模型,填写相关配置信息。
(2)点击左下角的自定义模型,填写相关配置信息。
 (3)示例模型:硅基流动部署的Qwen/Qwen2.5-7B-Instruct:
* API base选择硅基流动。
* 填写API Key、模型ID等,并根据模型特性进行相应配置;
* 点击【检查】按钮,一键检测信息是否填写正确(示例绿标即为通过);
* 按需选择中转地区(中转地区选择功能可以解决部分模型提供商因为IP地区限制访问的问题);
* 可设置备用模型,当自定义模型失效时可以自动切换到备用模型;
* 所有配置完成后,点击【确认】按钮;
(3)示例模型:硅基流动部署的Qwen/Qwen2.5-7B-Instruct:
* API base选择硅基流动。
* 填写API Key、模型ID等,并根据模型特性进行相应配置;
* 点击【检查】按钮,一键检测信息是否填写正确(示例绿标即为通过);
* 按需选择中转地区(中转地区选择功能可以解决部分模型提供商因为IP地区限制访问的问题);
* 可设置备用模型,当自定义模型失效时可以自动切换到备用模型;
* 所有配置完成后,点击【确认】按钮;
 #### 2.1.3 创建聊天机器人
(1)接入成功后的模型会在自定义模型分类中显示,选中模型并点击【确认】;
(2)点击【创建聊天机器人】按钮:
#### 2.1.3 创建聊天机器人
(1)接入成功后的模型会在自定义模型分类中显示,选中模型并点击【确认】;
(2)点击【创建聊天机器人】按钮:
 (3)进入聊天机器人后发送消息即可开启对话;
(3)进入聊天机器人后发送消息即可开启对话;
 (所有模型均支持联网搜索、图片分析、深度思考等能力)
#### 2.1.4 自定义模型价格
开启自定义模型的聊天机器人,每创建一个机器人每天收费0.05 美金 ,按天扣费。
模型使用费用,将在SiliconCloud的账号余额扣取。
### 2.2. 接入API实现功能扩展
#### 2.2.1 创建API Key
(1)首先我们需要创建一个支持中转自定义模型的API key。
详细步骤:**使用 API → API Keys → 输入 API 名称 → 开启自定义模型中转 → 【添加 API KEY】**
(所有模型均支持联网搜索、图片分析、深度思考等能力)
#### 2.1.4 自定义模型价格
开启自定义模型的聊天机器人,每创建一个机器人每天收费0.05 美金 ,按天扣费。
模型使用费用,将在SiliconCloud的账号余额扣取。
### 2.2. 接入API实现功能扩展
#### 2.2.1 创建API Key
(1)首先我们需要创建一个支持中转自定义模型的API key。
详细步骤:**使用 API → API Keys → 输入 API 名称 → 开启自定义模型中转 → 【添加 API KEY】**
 (2)复制生成的API Key备用;
(2)复制生成的API Key备用;
 (3)查看中转后自定义模型的名称以方便调用:
(3)查看中转后自定义模型的名称以方便调用:
 #### 2.2.2 为模型增加新的功能
通过302中转的模型,可以新增一些模型本身不具备的功能
目前支持的有:
联网搜索、深度搜索、图片分析、推理模式、链接解析、工具调用、长期记忆
(点击文字可直达相关文档,根据文档说明使用即可,持续更新中)
以增加自定义模型联网搜索能力为例:
(1)进入相关文档后,点击【调试】按钮:
#### 2.2.2 为模型增加新的功能
通过302中转的模型,可以新增一些模型本身不具备的功能
目前支持的有:
联网搜索、深度搜索、图片分析、推理模式、链接解析、工具调用、长期记忆
(点击文字可直达相关文档,根据文档说明使用即可,持续更新中)
以增加自定义模型联网搜索能力为例:
(1)进入相关文档后,点击【调试】按钮:
 (2)点击“去设置变量值”,粘贴生成的API Key填并点击【保存】:
(注意:模型中转功能必须手动开启,因此需要手动粘贴对应的API Key)
(2)点击“去设置变量值”,粘贴生成的API Key填并点击【保存】:
(注意:模型中转功能必须手动开启,因此需要手动粘贴对应的API Key)
 (3)根据文档说明,自定义模型后缀加上“-web-search”(如示例Qwen/Qwen2.5-7B-Instruct-2-web-search)并输入提示词点击【发送】即可增加联网搜索能力:
(3)根据文档说明,自定义模型后缀加上“-web-search”(如示例Qwen/Qwen2.5-7B-Instruct-2-web-search)并输入提示词点击【发送】即可增加联网搜索能力:
 #### 2.2.3 接入API价格
新增支持中转自定义模型的API-Key后,每个key每天收费 0.05 美金,按天扣费。
其他功能扩展费用可查看对应文档说明。
附上302.AI价格表:[https://302.ai/pricing/](https://302.ai/pricing/)
## 3. 302.AI用户如何直接使用 SiliconCloud 模型
### 3.1 使用 SiliconCloud 语言模型进行AI对话
#### 3.1.1 进入302.AI官网或者客户端
* 302.AI官网:[https://302.ai/](https://302.ai/)
* 302.AI客户端下载网址:[https://302.ai/download/](https://302.ai/download/)
(进入后注册账号,如已注册,直接登录即可)
#### 3.1.2 聊天机器人
##### 创建聊天机器人
(1)登录进入302.AI官网或者客户端的管理后台。点击:
**使用机器人 → 聊天机器人 → 模型**;
#### 2.2.3 接入API价格
新增支持中转自定义模型的API-Key后,每个key每天收费 0.05 美金,按天扣费。
其他功能扩展费用可查看对应文档说明。
附上302.AI价格表:[https://302.ai/pricing/](https://302.ai/pricing/)
## 3. 302.AI用户如何直接使用 SiliconCloud 模型
### 3.1 使用 SiliconCloud 语言模型进行AI对话
#### 3.1.1 进入302.AI官网或者客户端
* 302.AI官网:[https://302.ai/](https://302.ai/)
* 302.AI客户端下载网址:[https://302.ai/download/](https://302.ai/download/)
(进入后注册账号,如已注册,直接登录即可)
#### 3.1.2 聊天机器人
##### 创建聊天机器人
(1)登录进入302.AI官网或者客户端的管理后台。点击:
**使用机器人 → 聊天机器人 → 模型**;
 (2)找到【硅基流动】→选择模型(如deepseek-ai/deepseek-vl2)→ 确定→创建聊天机器人;
(2)找到【硅基流动】→选择模型(如deepseek-ai/deepseek-vl2)→ 确定→创建聊天机器人;
 (3)聊天机器人创建成功后会在页面下方展示,可进一步选择聊天、分享、编辑等操作。
(3)聊天机器人创建成功后会在页面下方展示,可进一步选择聊天、分享、编辑等操作。
 ##### 使用聊天机器人
(1)进入聊天机器人后在输入框键入文字即可聊天,输入框下方的按钮可上传图片或文件。
##### 使用聊天机器人
(1)进入聊天机器人后在输入框键入文字即可聊天,输入框下方的按钮可上传图片或文件。
 (2)点击对话框界面下方的按钮可开启聊天机器人的实时预览功能,这一功能可以实时查看模型生成代码的运行效果。 1.2.3 在全能工具箱中使用
(2)点击对话框界面下方的按钮可开启聊天机器人的实时预览功能,这一功能可以实时查看模型生成代码的运行效果。 1.2.3 在全能工具箱中使用
 我们还可以通过全能工具箱选择 SiliconCloud 模型进行对话:
**依次点击: 全能工具箱 → 快捷使用**
我们还可以通过全能工具箱选择 SiliconCloud 模型进行对话:
**依次点击: 全能工具箱 → 快捷使用**
 进入全能工具箱后点击:
**聊天机器人 → 找到对话框下方的 “@” → 切换 SiliconCloud 模型**
进入全能工具箱后点击:
**聊天机器人 → 找到对话框下方的 “@” → 切换 SiliconCloud 模型**
 ### 3.2 在模型竞技场使用 SiliconCloud 模型
#### 3.2.1 创建模型竞技场
在管理后台菜单栏选择:
**使用工具 → 工具超市 → 工具效率 → 【模型竞技场】 → 创建**。
### 3.2 在模型竞技场使用 SiliconCloud 模型
#### 3.2.1 创建模型竞技场
在管理后台菜单栏选择:
**使用工具 → 工具超市 → 工具效率 → 【模型竞技场】 → 创建**。
 #### 3.2.2 选择模型开始竞技
进入模型竞技场后,下滑找到【硅基流动】并按需勾选模型,输入提示词即可在页面右侧直观对比不同模型输出的答案。
#### 3.2.2 选择模型开始竞技
进入模型竞技场后,下滑找到【硅基流动】并按需勾选模型,输入提示词即可在页面右侧直观对比不同模型输出的答案。
 ### 3.3. 接入 SiliconCloud 模型API
#### 3.3.1 查看文档
直达链接:[https://doc.302.ai/api-252560001?environment\[YOUR\_API\_KEY\]=sk-ykJk7PY80O3ulWYTGplndVApzj4oeTeMvH4Jrxh6CkaegWiz](https://doc.302.ai/api-252560001?environment\[YOUR_API_KEY]=sk-ykJk7PY80O3ulWYTGplndVApzj4oeTeMvH4Jrxh6CkaegWiz)
### 3.3. 接入 SiliconCloud 模型API
#### 3.3.1 查看文档
直达链接:[https://doc.302.ai/api-252560001?environment\[YOUR\_API\_KEY\]=sk-ykJk7PY80O3ulWYTGplndVApzj4oeTeMvH4Jrxh6CkaegWiz](https://doc.302.ai/api-252560001?environment\[YOUR_API_KEY]=sk-ykJk7PY80O3ulWYTGplndVApzj4oeTeMvH4Jrxh6CkaegWiz)
 #### 3.3.2 在线调试
(1)点击查看文档即可进入API文档:
#### 3.3.2 在线调试
(1)点击查看文档即可进入API文档:
 (2)**进入API文档后点击在线调试 → “去设置变量值”,查看API KEY是否自动赋值**。
(2)**进入API文档后点击在线调试 → “去设置变量值”,查看API KEY是否自动赋值**。
 (3)根据参数模板填写要使用的模型ID和文本内容,点击发送,等待输出结果即可。
(3)根据参数模板填写要使用的模型ID和文本内容,点击发送,等待输出结果即可。
 # DB-GPT
Source: https://docs.siliconflow.cn/cn/usercases/use-siliconcloud-in-DB-GPT
## 1.关于 DB-GPT
[DB-GPT](https://github.com/eosphoros-ai/DB-GPT) **是一个开源的AI原生数据应用开发框架(AI Native Data App Development framework with AWEL(Agentic Workflow Expression Language) and Agents)。**
目的是构建大模型领域的基础设施,通过开发多模型管理(SMMF)、Text2SQL效果优化、RAG框架以及优化、Multi-Agents框架协作、AWEL(智能体工作流编排)等多种技术能力,让围绕数据库构建大模型应用更简单,更方便。
## 2.获取 API Key
2.1 打开 [SiliconCloud 官网](https://cloud.siliconflow.cn/) 并注册账号(如果注册过,直接登录即可)。
2.2 完成注册后,打开[API密钥](https://cloud.siliconflow.cn/account/ak) ,创建新的 API Key,点击密钥进行复制,以备后续使用。
## 3.部署 DB-GPT
### 3.1 克隆 DB-GPT 源码
```bash
git clone https://github.com/eosphoros-ai/DB-GPT.git
```
### 3.2 创建虚拟环境并安装依赖
```bash
# cd 到 DB-GPT 源码根目录
cd DB-GPT
# DB-GPT 要求python >= 3.10
conda create -n dbgpt_env python=3.10
conda activate dbgpt_env
# 这里选择代理模型类依赖安装
pip install -e ".[proxy]"
```
### 3.3 配置基础的环境变量
```bash
# 复制模板 env 文件为 .env
cp .env.template .env
```
### 3.4 修改环境变量文件`.env`,配置 SiliconCloud 模型
```bash
# 使用 SiliconCloud 的代理模型
LLM_MODEL=siliconflow_proxyllm
# 配置具体使用的模型名称
SILICONFLOW_MODEL_VERSION=Qwen/Qwen2.5-Coder-32B-Instruct
SILICONFLOW_API_BASE=https://api.siliconflow.cn/v1
# 记得填写您在步骤2中获取的 API Key
SILICONFLOW_API_KEY={your-siliconflow-api-key}
# 配置使用 SiliconCloud 的 Embedding 模型
EMBEDDING_MODEL=proxy_http_openapi
PROXY_HTTP_OPENAPI_PROXY_SERVER_URL=https://api.siliconflow.cn/v1/embeddings
# 记得填写您在步骤2中获取的 API Key
PROXY_HTTP_OPENAPI_PROXY_API_KEY={your-siliconflow-api-key}
# 配置具体的 Embedding 模型名称
PROXY_HTTP_OPENAPI_PROXY_BACKEND=BAAI/bge-large-zh-v1.5
# 配置使用 SiliconCloud 的 rerank 模型
RERANK_MODEL=rerank_proxy_siliconflow
RERANK_PROXY_SILICONFLOW_PROXY_SERVER_URL=https://api.siliconflow.cn/v1/rerank
# 记得填写您在步骤2中获取的 API Key
RERANK_PROXY_SILICONFLOW_PROXY_API_KEY={your-siliconflow-api-key}
# 配置具体的 rerank 模型名称
RERANK_PROXY_SILICONFLOW_PROXY_BACKEND=BAAI/bge-reranker-v2-m3
```
注意,上述的 `SILICONFLOW_API_KEY`、 `PROXY_HTTP_OPENAPI_PROXY_SERVER_URL` 和`RERANK_PROXY_SILICONFLOW_PROXY_API_KEY`环境变量是您在步骤 2 中获取的 SiliconCloud 的 Api Key。语言模型(`SILICONFLOW_MODEL_VERSION`)、 Embedding 模型(`PROXY_HTTP_OPENAPI_PROXY_BACKEND`)和 rerank 模型(`RERANK_PROXY_SILICONFLOW_PROXY_BACKEND`) 可以从 [获取用户模型列表 - SiliconFlow](https://docs.siliconflow.cn/api-reference/models/get-model-list) 中获取。
### 3.5 启动 DB-GPT 服务
```bash
dbgpt start webserver --port 5670
```
在浏览器打开地址 [http://127.0.0.1:5670/](http://127.0.0.1:5670/) 即可访问部署好的 DB-GPT
## 4.通过 DB-GPT Python SDK 使用 SiliconCloud 的模型
### 4.1 安装 DB-GPT Python 包
```bash
pip install "dbgpt>=0.6.3rc2" openai requests numpy
```
为了后续验证,额外安装相关依赖包。
### 4.2. 使用 SiliconCloud 的大语言模型
```python
import asyncio
import os
from dbgpt.core import ModelRequest
from dbgpt.model.proxy import SiliconFlowLLMClient
model = "Qwen/Qwen2.5-Coder-32B-Instruct"
client = SiliconFlowLLMClient(
api_key=os.getenv("SILICONFLOW_API_KEY"),
model_alias=model
)
res = asyncio.run(
client.generate(
ModelRequest(
model=model,
messages=[
{"role": "system", "content": "你是一个乐于助人的 AI 助手。"},
{"role": "human", "content": "你好"},
]
)
)
)
print(res)
```
### 4.3 使用 SiliconCloud 的 Embedding 模型
```python
import os
from dbgpt.rag.embedding import OpenAPIEmbeddings
openai_embeddings = OpenAPIEmbeddings(
api_url="https://api.siliconflow.cn/v1/embeddings",
api_key=os.getenv("SILICONFLOW_API_KEY"),
model_name="BAAI/bge-large-zh-v1.5",
)
texts = ["Hello, world!", "How are you?"]
res = openai_embeddings.embed_documents(texts)
print(res)
```
### 4.4 使用 SiliconCloud 的 rerank 模型
```python
import os
from dbgpt.rag.embedding import SiliconFlowRerankEmbeddings
embedding = SiliconFlowRerankEmbeddings(
api_key=os.getenv("SILICONFLOW_API_KEY"),
model_name="BAAI/bge-reranker-v2-m3",
)
res = embedding.predict("Apple", candidates=["苹果", "香蕉", "水果", "蔬菜"])
print(res)
```
## 5. 上手指南
以数据对话案例为例,数据对话能力是通过自然语言与数据进行对话,目前主要是结构化与半结构化数据的对话,可以辅助做数据分析与洞察。以下为具体操作流程:
### 1. 添加数据源
首先选择左侧数据源添加,添加数据库,目前DB-GPT支持多种数据库类型。选择对应的数据库类型添加即可。这里我们选择的是MySQL作为演示,演示的测试数据参见测试样例([https://github.com/eosphoros-ai/DB-GPT/tree/main/docker/examples/sqls)。](https://github.com/eosphoros-ai/DB-GPT/tree/main/docker/examples/sqls)。)
# DB-GPT
Source: https://docs.siliconflow.cn/cn/usercases/use-siliconcloud-in-DB-GPT
## 1.关于 DB-GPT
[DB-GPT](https://github.com/eosphoros-ai/DB-GPT) **是一个开源的AI原生数据应用开发框架(AI Native Data App Development framework with AWEL(Agentic Workflow Expression Language) and Agents)。**
目的是构建大模型领域的基础设施,通过开发多模型管理(SMMF)、Text2SQL效果优化、RAG框架以及优化、Multi-Agents框架协作、AWEL(智能体工作流编排)等多种技术能力,让围绕数据库构建大模型应用更简单,更方便。
## 2.获取 API Key
2.1 打开 [SiliconCloud 官网](https://cloud.siliconflow.cn/) 并注册账号(如果注册过,直接登录即可)。
2.2 完成注册后,打开[API密钥](https://cloud.siliconflow.cn/account/ak) ,创建新的 API Key,点击密钥进行复制,以备后续使用。
## 3.部署 DB-GPT
### 3.1 克隆 DB-GPT 源码
```bash
git clone https://github.com/eosphoros-ai/DB-GPT.git
```
### 3.2 创建虚拟环境并安装依赖
```bash
# cd 到 DB-GPT 源码根目录
cd DB-GPT
# DB-GPT 要求python >= 3.10
conda create -n dbgpt_env python=3.10
conda activate dbgpt_env
# 这里选择代理模型类依赖安装
pip install -e ".[proxy]"
```
### 3.3 配置基础的环境变量
```bash
# 复制模板 env 文件为 .env
cp .env.template .env
```
### 3.4 修改环境变量文件`.env`,配置 SiliconCloud 模型
```bash
# 使用 SiliconCloud 的代理模型
LLM_MODEL=siliconflow_proxyllm
# 配置具体使用的模型名称
SILICONFLOW_MODEL_VERSION=Qwen/Qwen2.5-Coder-32B-Instruct
SILICONFLOW_API_BASE=https://api.siliconflow.cn/v1
# 记得填写您在步骤2中获取的 API Key
SILICONFLOW_API_KEY={your-siliconflow-api-key}
# 配置使用 SiliconCloud 的 Embedding 模型
EMBEDDING_MODEL=proxy_http_openapi
PROXY_HTTP_OPENAPI_PROXY_SERVER_URL=https://api.siliconflow.cn/v1/embeddings
# 记得填写您在步骤2中获取的 API Key
PROXY_HTTP_OPENAPI_PROXY_API_KEY={your-siliconflow-api-key}
# 配置具体的 Embedding 模型名称
PROXY_HTTP_OPENAPI_PROXY_BACKEND=BAAI/bge-large-zh-v1.5
# 配置使用 SiliconCloud 的 rerank 模型
RERANK_MODEL=rerank_proxy_siliconflow
RERANK_PROXY_SILICONFLOW_PROXY_SERVER_URL=https://api.siliconflow.cn/v1/rerank
# 记得填写您在步骤2中获取的 API Key
RERANK_PROXY_SILICONFLOW_PROXY_API_KEY={your-siliconflow-api-key}
# 配置具体的 rerank 模型名称
RERANK_PROXY_SILICONFLOW_PROXY_BACKEND=BAAI/bge-reranker-v2-m3
```
注意,上述的 `SILICONFLOW_API_KEY`、 `PROXY_HTTP_OPENAPI_PROXY_SERVER_URL` 和`RERANK_PROXY_SILICONFLOW_PROXY_API_KEY`环境变量是您在步骤 2 中获取的 SiliconCloud 的 Api Key。语言模型(`SILICONFLOW_MODEL_VERSION`)、 Embedding 模型(`PROXY_HTTP_OPENAPI_PROXY_BACKEND`)和 rerank 模型(`RERANK_PROXY_SILICONFLOW_PROXY_BACKEND`) 可以从 [获取用户模型列表 - SiliconFlow](https://docs.siliconflow.cn/api-reference/models/get-model-list) 中获取。
### 3.5 启动 DB-GPT 服务
```bash
dbgpt start webserver --port 5670
```
在浏览器打开地址 [http://127.0.0.1:5670/](http://127.0.0.1:5670/) 即可访问部署好的 DB-GPT
## 4.通过 DB-GPT Python SDK 使用 SiliconCloud 的模型
### 4.1 安装 DB-GPT Python 包
```bash
pip install "dbgpt>=0.6.3rc2" openai requests numpy
```
为了后续验证,额外安装相关依赖包。
### 4.2. 使用 SiliconCloud 的大语言模型
```python
import asyncio
import os
from dbgpt.core import ModelRequest
from dbgpt.model.proxy import SiliconFlowLLMClient
model = "Qwen/Qwen2.5-Coder-32B-Instruct"
client = SiliconFlowLLMClient(
api_key=os.getenv("SILICONFLOW_API_KEY"),
model_alias=model
)
res = asyncio.run(
client.generate(
ModelRequest(
model=model,
messages=[
{"role": "system", "content": "你是一个乐于助人的 AI 助手。"},
{"role": "human", "content": "你好"},
]
)
)
)
print(res)
```
### 4.3 使用 SiliconCloud 的 Embedding 模型
```python
import os
from dbgpt.rag.embedding import OpenAPIEmbeddings
openai_embeddings = OpenAPIEmbeddings(
api_url="https://api.siliconflow.cn/v1/embeddings",
api_key=os.getenv("SILICONFLOW_API_KEY"),
model_name="BAAI/bge-large-zh-v1.5",
)
texts = ["Hello, world!", "How are you?"]
res = openai_embeddings.embed_documents(texts)
print(res)
```
### 4.4 使用 SiliconCloud 的 rerank 模型
```python
import os
from dbgpt.rag.embedding import SiliconFlowRerankEmbeddings
embedding = SiliconFlowRerankEmbeddings(
api_key=os.getenv("SILICONFLOW_API_KEY"),
model_name="BAAI/bge-reranker-v2-m3",
)
res = embedding.predict("Apple", candidates=["苹果", "香蕉", "水果", "蔬菜"])
print(res)
```
## 5. 上手指南
以数据对话案例为例,数据对话能力是通过自然语言与数据进行对话,目前主要是结构化与半结构化数据的对话,可以辅助做数据分析与洞察。以下为具体操作流程:
### 1. 添加数据源
首先选择左侧数据源添加,添加数据库,目前DB-GPT支持多种数据库类型。选择对应的数据库类型添加即可。这里我们选择的是MySQL作为演示,演示的测试数据参见测试样例([https://github.com/eosphoros-ai/DB-GPT/tree/main/docker/examples/sqls)。](https://github.com/eosphoros-ai/DB-GPT/tree/main/docker/examples/sqls)。)
 ### 2. 选择对话类型
选择ChatData对话类型。
### 2. 选择对话类型
选择ChatData对话类型。
 ### 3. 开始数据对话
注意:在对话时,选择对应的模型与数据库。同时DB-GPT也提供了预览模式与编辑模式。
### 3. 开始数据对话
注意:在对话时,选择对应的模型与数据库。同时DB-GPT也提供了预览模式与编辑模式。
 编辑模式:
编辑模式:
 # NoteGen
Source: https://docs.siliconflow.cn/cn/usercases/use-siliconcloud-in-NoteGen
## 关于 NoteGen
[NoteGen](https://github.com/codexu/note-gen) 是一款的跨端的 `Markdown` 笔记应用,致力于使用 AI 建立记录和写作的桥梁,将碎片化知识整理成一篇可读的笔记。
本文将介绍如何借助 SiliconCloud 提供的 API 服务在 NoteGen 进行笔记的记录与写作。
## 安装 NoteGen
浏览器打开 [NoteGen Releases](https://github.com/codexu/note-gen/releases) 下载对应系统的安装包。
# NoteGen
Source: https://docs.siliconflow.cn/cn/usercases/use-siliconcloud-in-NoteGen
## 关于 NoteGen
[NoteGen](https://github.com/codexu/note-gen) 是一款的跨端的 `Markdown` 笔记应用,致力于使用 AI 建立记录和写作的桥梁,将碎片化知识整理成一篇可读的笔记。
本文将介绍如何借助 SiliconCloud 提供的 API 服务在 NoteGen 进行笔记的记录与写作。
## 安装 NoteGen
浏览器打开 [NoteGen Releases](https://github.com/codexu/note-gen/releases) 下载对应系统的安装包。
 NoteGen 支持所有的主流操作系统,包括 Windows、MacOS 和 Linux,未来将支持 iOS 和 Android。
## 在 NoteGen 中使用 SiliconCloud
安装 NoteGen 之后,按照下面的步骤依次操作:
1. 点击左下角的设置按钮进入系统设置界面。
2. 在 Model Provider 中选择 SiliconFlow。
3. 填写在 SiliconCloud 后台新建的 API 密钥。
4. 点击 Model 下拉菜单选择你需要的模型。
NoteGen 支持所有的主流操作系统,包括 Windows、MacOS 和 Linux,未来将支持 iOS 和 Android。
## 在 NoteGen 中使用 SiliconCloud
安装 NoteGen 之后,按照下面的步骤依次操作:
1. 点击左下角的设置按钮进入系统设置界面。
2. 在 Model Provider 中选择 SiliconFlow。
3. 填写在 SiliconCloud 后台新建的 API 密钥。
4. 点击 Model 下拉菜单选择你需要的模型。
 完成上述操作后,如果 Model Provider 展示绿色对勾表示可以正常使用了。
## 在 NoteGen 测试使用 SiliconCloud DeepSeek-V3 模型
完成上述操作后,如果 Model Provider 展示绿色对勾表示可以正常使用了。
## 在 NoteGen 测试使用 SiliconCloud DeepSeek-V3 模型
 # Bob 翻译
Source: https://docs.siliconflow.cn/cn/usercases/use-siliconcloud-in-bob
## 1. 关于 Bob
[Bob](https://bobtranslate.com) 是一款 macOS 平台的翻译和 OCR 软件,您可以在任何应用程序中使用 Bob 进行翻译和 OCR,即用即走,简单、快捷、高效!
本文将介绍如何借助 SiliconCloud 提供的 API 服务在 Bob 中进行翻译。
## 2. 安装 Bob
前往 Mac App Store 安装 Bob。[Mac App Store 安装](https://apps.apple.com/cn/app/id1630034110)
## 3. 在 Bob 中使用 SiliconCloud
### 3.1 默认配置
安装完 Bob 之后,在任意软件选中一段文本,然后按下 `⌥` `D` 快捷键即可翻译,SiliconCloud 的免费模型会作为默认翻译服务进行翻译,如下图所示。
# Bob 翻译
Source: https://docs.siliconflow.cn/cn/usercases/use-siliconcloud-in-bob
## 1. 关于 Bob
[Bob](https://bobtranslate.com) 是一款 macOS 平台的翻译和 OCR 软件,您可以在任何应用程序中使用 Bob 进行翻译和 OCR,即用即走,简单、快捷、高效!
本文将介绍如何借助 SiliconCloud 提供的 API 服务在 Bob 中进行翻译。
## 2. 安装 Bob
前往 Mac App Store 安装 Bob。[Mac App Store 安装](https://apps.apple.com/cn/app/id1630034110)
## 3. 在 Bob 中使用 SiliconCloud
### 3.1 默认配置
安装完 Bob 之后,在任意软件选中一段文本,然后按下 `⌥` `D` 快捷键即可翻译,SiliconCloud 的免费模型会作为默认翻译服务进行翻译,如下图所示。
 ### 3.2 使用 SiliconCloud 的其他免费模型
默认使用的模型是 `Qwen/Qwen2.5-7B-Instruct`,可以使用**鼠标右键**点击翻译窗口右上角的服务图标前往「翻译-服务」页面切换其他免费模型。
### 3.2 使用 SiliconCloud 的其他免费模型
默认使用的模型是 `Qwen/Qwen2.5-7B-Instruct`,可以使用**鼠标右键**点击翻译窗口右上角的服务图标前往「翻译-服务」页面切换其他免费模型。
 如下图所示,标注为**免费**的模型均可直接使用。
如下图所示,标注为**免费**的模型均可直接使用。
 ### 3.3 使用 SiliconCloud 的其他文本生成模型
如需使用没有标注为免费的模型,需要自行获取 SiliconCloud API Key。
1. 打开 SiliconCloud [官网](https://cloud.siliconflow.cn/) 并注册账号(如果注册过,直接登录即可)。
2. 完成注册后,打开 [API 密钥](https://cloud.siliconflow.cn/account/ak) ,创建新的 API Key,点击密钥进行复制,以备后续使用。
3. 进入之前提到的 Bob「翻译-服务」页面,将 API Key 填入**硅基流动翻译**服务的 API Key 设置项中,然后切换到需要使用的其他模型,点击保存即可使用。
### 3.3 使用 SiliconCloud 的其他文本生成模型
如需使用没有标注为免费的模型,需要自行获取 SiliconCloud API Key。
1. 打开 SiliconCloud [官网](https://cloud.siliconflow.cn/) 并注册账号(如果注册过,直接登录即可)。
2. 完成注册后,打开 [API 密钥](https://cloud.siliconflow.cn/account/ak) ,创建新的 API Key,点击密钥进行复制,以备后续使用。
3. 进入之前提到的 Bob「翻译-服务」页面,将 API Key 填入**硅基流动翻译**服务的 API Key 设置项中,然后切换到需要使用的其他模型,点击保存即可使用。
 # Chat2Graph
Source: https://docs.siliconflow.cn/cn/usercases/use-siliconcloud-in-chat2graph
## 关于 Chat2Graph
[Chat2Graph](https://github.com/TuGraph-family/chat2graph) 是一个图原生的智能体系统(Graph Native Agentic System),通过利用图数据结构在关系建模、可解释性等符号主义的天然优势,对智能体的推理、规划、记忆、知识、工具协作等关键能力进行增强,同时借助智能体技术推进图数据库智能化,降低用图门槛,加速内容生成,实现与图对话。做到图计算技术与人工智能技术的深度融合。
# Chat2Graph
Source: https://docs.siliconflow.cn/cn/usercases/use-siliconcloud-in-chat2graph
## 关于 Chat2Graph
[Chat2Graph](https://github.com/TuGraph-family/chat2graph) 是一个图原生的智能体系统(Graph Native Agentic System),通过利用图数据结构在关系建模、可解释性等符号主义的天然优势,对智能体的推理、规划、记忆、知识、工具协作等关键能力进行增强,同时借助智能体技术推进图数据库智能化,降低用图门槛,加速内容生成,实现与图对话。做到图计算技术与人工智能技术的深度融合。
 ## 获取 API Key
1. 打开 [SiliconFlow](https://cloud.siliconflow.cn/) 官网 并注册账号(如果注册过,直接登录即可)。
2. 完成注册后,打开 [API密钥](https://cloud.siliconflow.cn/account/ak) ,创建新的 API Key,点击密钥进行复制,以备后续使用。
## 部署 Chat2Graph
### 下载 Chat2Graph
```yaml
git clone https://github.com/TuGraph-family/chat2graph.git
```
### 准备执行环境
准备符合要求的 Python 和 NodeJS 版本。
* **Python**: 推荐[Python == 3.10](https://www.python.org/downloads)。
* **NodeJS**: 推荐[NodeJS >= v16](https://nodejs.org/en/download)。
您可以使用 `conda` 等工具来管理您的 Python 环境:
```yaml
conda create -n chat2graph_env python=3.10
conda activate chat2graph_env
```
### 构建 Chat2Graph
一键构建 Chat2Graph:
```yaml
cd chat2graph
./bin/build.sh
```
### 配置 SiliconFlow 模型
准备 `.env` 配置文件:
```yaml
cp .env.template .env && vim .env
```
填写 SiliconFlow 模型配置:
```yaml
LLM_NAME=deepseek-ai/DeepSeek-V3
LLM_ENDPOINT=https://api.siliconflow.cn/v1
LLM_APIKEY={your-siliconflow-api-key}
EMBEDDING_MODEL_NAME=BAAI/bge-large-zh-v1.5
EMBEDDING_MODEL_ENDPOINT=https://api.siliconflow.cn/v1/embeddings
EMBEDDING_MODEL_APIKEY={your-siliconflow-api-key}
```
### 启动 Chat2Graph
一键启动 Chat2Graph:
```yaml
./bin/start.sh
```
当看到如下日志时,表示 Chat2Graph 已成功启动:
```latex
Starting server...
Web resources location: /Users/florian/code/chat2graph/app/server/web
System database url: sqlite:////Users/florian/.chat2graph/system/chat2graph.db
Loading AgenticService from app/core/sdk/chat2graph.yml with encoding utf-8
Init application: Chat2Graph
Init the Leader agent
Init the Expert agents
____ _ _ ____ ____ _
/ ___| |__ __ _| |_|___ \ / ___|_ __ __ _ _ __ | |__
| | | '_ \ / _` | __| __) | | _| '__/ _` | '_ \| '_ \
| |___| | | | (_| | |_ / __/| |_| | | | (_| | |_) | | | |
\____|_| |_|\__,_|\__|_____|\____|_| \__,_| .__/|_| |_|
|_|
* Serving Flask app 'bootstrap'
* Debug mode: off
WARNING: This is a development server. Do not use it in a production deployment. Use a production WSGI server instead.
* Running on all addresses (0.0.0.0)
* Running on http://127.0.0.1:5010
* Running on http://192.168.1.1:5010
Chat2Graph server started success !
```
## 使用 Chat2Graph
你可以在浏览器访问 [http://localhost:5010/](http://localhost:5010/) 使用 Chat2Graph。
## 获取 API Key
1. 打开 [SiliconFlow](https://cloud.siliconflow.cn/) 官网 并注册账号(如果注册过,直接登录即可)。
2. 完成注册后,打开 [API密钥](https://cloud.siliconflow.cn/account/ak) ,创建新的 API Key,点击密钥进行复制,以备后续使用。
## 部署 Chat2Graph
### 下载 Chat2Graph
```yaml
git clone https://github.com/TuGraph-family/chat2graph.git
```
### 准备执行环境
准备符合要求的 Python 和 NodeJS 版本。
* **Python**: 推荐[Python == 3.10](https://www.python.org/downloads)。
* **NodeJS**: 推荐[NodeJS >= v16](https://nodejs.org/en/download)。
您可以使用 `conda` 等工具来管理您的 Python 环境:
```yaml
conda create -n chat2graph_env python=3.10
conda activate chat2graph_env
```
### 构建 Chat2Graph
一键构建 Chat2Graph:
```yaml
cd chat2graph
./bin/build.sh
```
### 配置 SiliconFlow 模型
准备 `.env` 配置文件:
```yaml
cp .env.template .env && vim .env
```
填写 SiliconFlow 模型配置:
```yaml
LLM_NAME=deepseek-ai/DeepSeek-V3
LLM_ENDPOINT=https://api.siliconflow.cn/v1
LLM_APIKEY={your-siliconflow-api-key}
EMBEDDING_MODEL_NAME=BAAI/bge-large-zh-v1.5
EMBEDDING_MODEL_ENDPOINT=https://api.siliconflow.cn/v1/embeddings
EMBEDDING_MODEL_APIKEY={your-siliconflow-api-key}
```
### 启动 Chat2Graph
一键启动 Chat2Graph:
```yaml
./bin/start.sh
```
当看到如下日志时,表示 Chat2Graph 已成功启动:
```latex
Starting server...
Web resources location: /Users/florian/code/chat2graph/app/server/web
System database url: sqlite:////Users/florian/.chat2graph/system/chat2graph.db
Loading AgenticService from app/core/sdk/chat2graph.yml with encoding utf-8
Init application: Chat2Graph
Init the Leader agent
Init the Expert agents
____ _ _ ____ ____ _
/ ___| |__ __ _| |_|___ \ / ___|_ __ __ _ _ __ | |__
| | | '_ \ / _` | __| __) | | _| '__/ _` | '_ \| '_ \
| |___| | | | (_| | |_ / __/| |_| | | | (_| | |_) | | | |
\____|_| |_|\__,_|\__|_____|\____|_| \__,_| .__/|_| |_|
|_|
* Serving Flask app 'bootstrap'
* Debug mode: off
WARNING: This is a development server. Do not use it in a production deployment. Use a production WSGI server instead.
* Running on all addresses (0.0.0.0)
* Running on http://127.0.0.1:5010
* Running on http://192.168.1.1:5010
Chat2Graph server started success !
```
## 使用 Chat2Graph
你可以在浏览器访问 [http://localhost:5010/](http://localhost:5010/) 使用 Chat2Graph。
 ### 注册图数据库
提前注册图数据库实例,可以体验完整的 Chat2Graph 的「与图对话」功能。当前支持 [Neo4j](https://neo4j.com/) 和 [TuGraph](https://tugraph.tech/) 图数据库。
### 注册图数据库
提前注册图数据库实例,可以体验完整的 Chat2Graph 的「与图对话」功能。当前支持 [Neo4j](https://neo4j.com/) 和 [TuGraph](https://tugraph.tech/) 图数据库。
 启动 Neo4j 实例:
```plain
docker pull neo4j:latest
docker run -d -p 7474:7474 -p 7687:7687 --name neo4j-server --env NEO4J_AUTH=none \
--env NEO4J_PLUGINS='["apoc", "graph-data-science"]' neo4j:latest
```
启动 TuGraph 实例:
```latex
docker pull tugraph/tugraph-runtime-centos7:4.5.1
docker run -d -p 7070:7070 -p 7687:7687 -p 9090:9090 --name tugraph-server \
tugraph/tugraph-runtime-centos7:latest lgraph_server -d run --enable_plugin true
```
### 与图轻松对话
自动完成知识图谱的构建与分析任务:
启动 Neo4j 实例:
```plain
docker pull neo4j:latest
docker run -d -p 7474:7474 -p 7687:7687 --name neo4j-server --env NEO4J_AUTH=none \
--env NEO4J_PLUGINS='["apoc", "graph-data-science"]' neo4j:latest
```
启动 TuGraph 实例:
```latex
docker pull tugraph/tugraph-runtime-centos7:4.5.1
docker run -d -p 7070:7070 -p 7687:7687 -p 9090:9090 --name tugraph-server \
tugraph/tugraph-runtime-centos7:latest lgraph_server -d run --enable_plugin true
```
### 与图轻松对话
自动完成知识图谱的构建与分析任务:
 支持图模型与图数据的实时渲染。
支持图模型与图数据的实时渲染。
 ## 集成 Chat2Graph
Chat2Graph 提供了清晰简洁的 SDK API,让你轻松定制智能体系统。
配置 SiliconFlow 模型:
```latex
SystemEnv.LLM_NAME="deepseek-ai/DeepSeek-V3"
SystemEnv.LLM_ENDPOINT="https://api.siliconflow.cn/v1"
SystemEnv.LLM_APIKEY="{your-siliconflow-api-key}"
SystemEnv.EMBEDDING_MODEL_NAME="BAAI/bge-large-zh-v1.5"
SystemEnv.EMBEDDING_MODEL_ENDPOINT="https://api.siliconflow.cn/v1/embeddings"
SystemEnv.EMBEDDING_MODEL_APIKEY="{your-siliconflow-api-key}"
```
仿写 `chat2graph.yml` 文件,一键初始化智能体:
```latex
chat2graph = AgenticService.load("app/core/sdk/chat2graph.yml")
```
同步调用智能体:
```latex
answer = chat2graph.execute("What is TuGraph ?").get_payload()
```
异步调用智能体:
```latex
job = chat2graph.session().submit("What is TuGraph ?")
answer = job.wait().get_payload()
```
# Chatbox
Source: https://docs.siliconflow.cn/cn/usercases/use-siliconcloud-in-chatbox
## 1 关于 Chatbox
Chatbox 是一个流行的大语言模型的全平台聊天客户端,特点是功能强大、安装简单。你可以用它接入各种大语言模型,然后在任何设备(电脑、手机、网页)上和 AI 聊天。
Chatbox 不仅提供简单好用的 AI 聊天功能,还提供了一系列强大功能:
* Artifact 预览:在 Chatbox 中你可以预览 AI 生成代码的实际效果,比如让 AI 帮你做一个网页、贪吃蛇游戏,然后在 Chatbox 中直接运行。
* 图表制作:让 AI 绘制思维导图、流程图、统计图表。
* 文档理解和图形视觉:可以向 AI 发送文档或者图片。
* 网页解析与识别:可以向 AI 发送链接,讨论网页内容等。
## 2 安装使用 Chatbox
浏览器访问 [Chatbox 官网](https://chatboxai.app/)下载安装包。
## 集成 Chat2Graph
Chat2Graph 提供了清晰简洁的 SDK API,让你轻松定制智能体系统。
配置 SiliconFlow 模型:
```latex
SystemEnv.LLM_NAME="deepseek-ai/DeepSeek-V3"
SystemEnv.LLM_ENDPOINT="https://api.siliconflow.cn/v1"
SystemEnv.LLM_APIKEY="{your-siliconflow-api-key}"
SystemEnv.EMBEDDING_MODEL_NAME="BAAI/bge-large-zh-v1.5"
SystemEnv.EMBEDDING_MODEL_ENDPOINT="https://api.siliconflow.cn/v1/embeddings"
SystemEnv.EMBEDDING_MODEL_APIKEY="{your-siliconflow-api-key}"
```
仿写 `chat2graph.yml` 文件,一键初始化智能体:
```latex
chat2graph = AgenticService.load("app/core/sdk/chat2graph.yml")
```
同步调用智能体:
```latex
answer = chat2graph.execute("What is TuGraph ?").get_payload()
```
异步调用智能体:
```latex
job = chat2graph.session().submit("What is TuGraph ?")
answer = job.wait().get_payload()
```
# Chatbox
Source: https://docs.siliconflow.cn/cn/usercases/use-siliconcloud-in-chatbox
## 1 关于 Chatbox
Chatbox 是一个流行的大语言模型的全平台聊天客户端,特点是功能强大、安装简单。你可以用它接入各种大语言模型,然后在任何设备(电脑、手机、网页)上和 AI 聊天。
Chatbox 不仅提供简单好用的 AI 聊天功能,还提供了一系列强大功能:
* Artifact 预览:在 Chatbox 中你可以预览 AI 生成代码的实际效果,比如让 AI 帮你做一个网页、贪吃蛇游戏,然后在 Chatbox 中直接运行。
* 图表制作:让 AI 绘制思维导图、流程图、统计图表。
* 文档理解和图形视觉:可以向 AI 发送文档或者图片。
* 网页解析与识别:可以向 AI 发送链接,讨论网页内容等。
## 2 安装使用 Chatbox
浏览器访问 [Chatbox 官网](https://chatboxai.app/)下载安装包。
 Chatbox 支持所有的主流操作系统,包括 Windows、MacOS 和 Linux,手机系统支持 iOS 和 Android。下载安装包后,在系统中直接安装即可。或者也可以访问和使用 Chatbox 的网页版本。
## 3 在 Chatbox 中使用硅基流动模型
### 3.1 配置硅基流动 API 密钥
访问 [API 密钥](https://cloud.siliconflow.cn/account/ak)新建或复制已有密钥。
Chatbox 支持所有的主流操作系统,包括 Windows、MacOS 和 Linux,手机系统支持 iOS 和 Android。下载安装包后,在系统中直接安装即可。或者也可以访问和使用 Chatbox 的网页版本。
## 3 在 Chatbox 中使用硅基流动模型
### 3.1 配置硅基流动 API 密钥
访问 [API 密钥](https://cloud.siliconflow.cn/account/ak)新建或复制已有密钥。
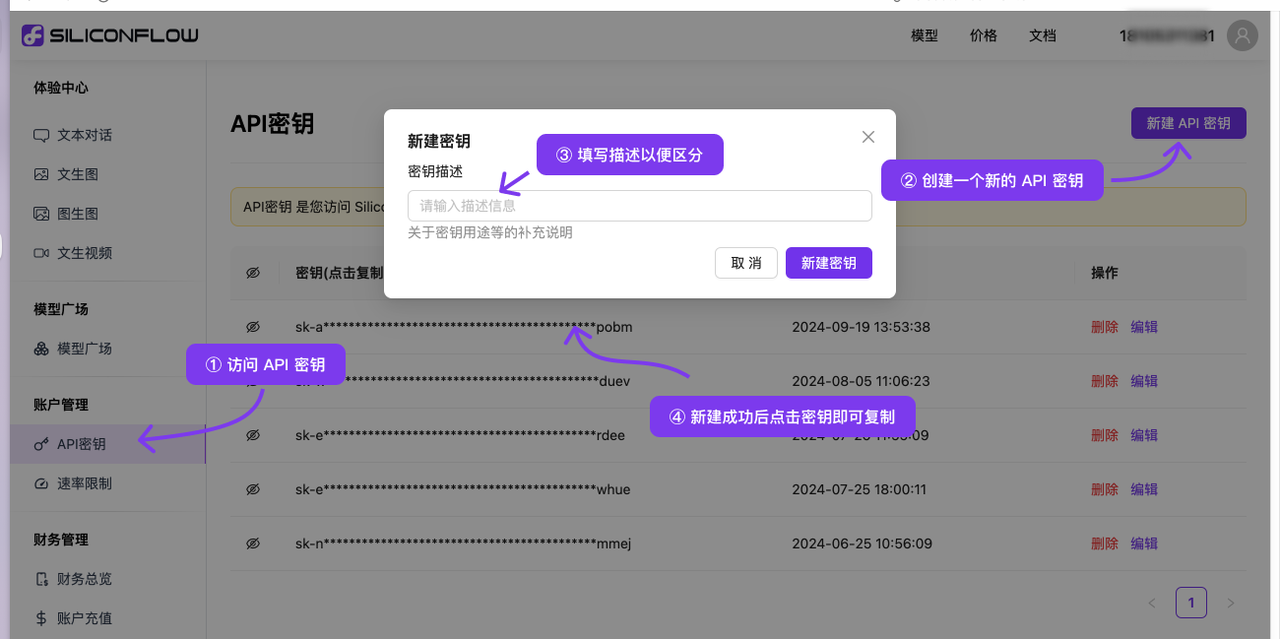 ### 3.2 在 Chatbox 中配置
1. 打开 Chatbox,进入设置。
2. 在模型提供方界面选择 SiliconFlow。
3. 输入个人的 SiliconFlow API 密钥。
### 3.2 在 Chatbox 中配置
1. 打开 Chatbox,进入设置。
2. 在模型提供方界面选择 SiliconFlow。
3. 输入个人的 SiliconFlow API 密钥。
 点击检查,完成后即可开始聊天。
### 3.3 开始聊天
按照上面步骤,基本上已经配置成功了,简单聊天测试一下。
点击检查,完成后即可开始聊天。
### 3.3 开始聊天
按照上面步骤,基本上已经配置成功了,简单聊天测试一下。
 ### 3.4 使用技巧
在结尾这里在顺带介绍一些 Chatbox 的使用技巧。
#### 3.4.1 利用 Chatbox 的图表能力,在聊天中生成可视化图表
Chatbox 的“做图表”助手会生成各种图表,在聊天中可以更方便地让你理解一些数据。
注意:为了更好的效果,需要选择更聪明更强大的模型。模型能力将直接决定图表的效果。
### 3.4 使用技巧
在结尾这里在顺带介绍一些 Chatbox 的使用技巧。
#### 3.4.1 利用 Chatbox 的图表能力,在聊天中生成可视化图表
Chatbox 的“做图表”助手会生成各种图表,在聊天中可以更方便地让你理解一些数据。
注意:为了更好的效果,需要选择更聪明更强大的模型。模型能力将直接决定图表的效果。
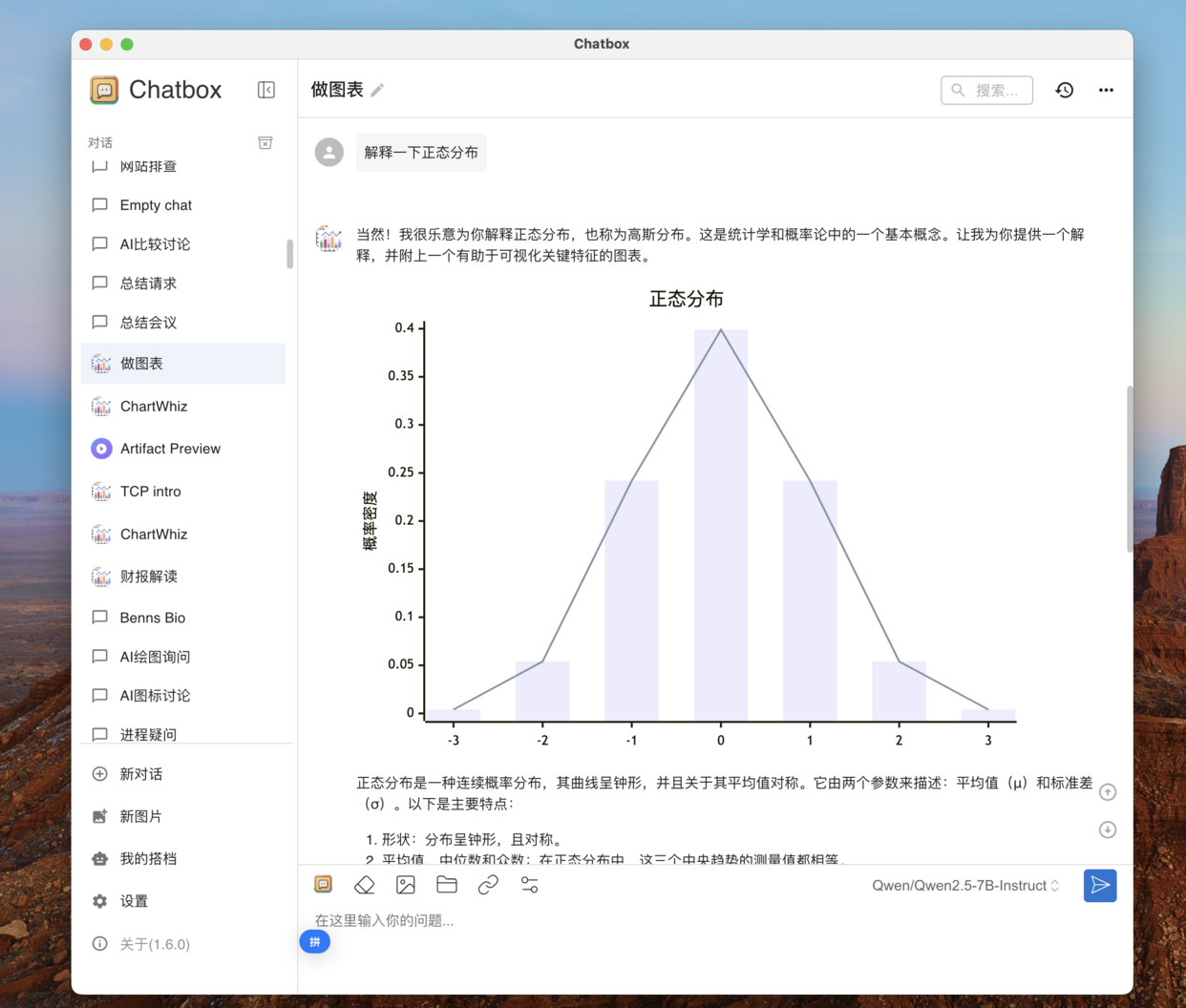 #### 3.4.2 利用 Chatbox 的 Artifact 预览功能,查看 AI 生成代码的运行效果
Chatbox 的 Artifact 预览功能,则可以让你直接预览 AI 生成前端代码的实际运行效果。
注意:为了更好的效果,需要选择更聪明更强大的模型。模型能力将直接决定生成代码的效果。
#### 3.4.2 利用 Chatbox 的 Artifact 预览功能,查看 AI 生成代码的运行效果
Chatbox 的 Artifact 预览功能,则可以让你直接预览 AI 生成前端代码的实际运行效果。
注意:为了更好的效果,需要选择更聪明更强大的模型。模型能力将直接决定生成代码的效果。
 除了这些技巧外,在 Chatbox 简单易用的外表下,还隐藏着非常多强大的功能,有很多值得探索的地方。
## 4 参考资料
* [Chatbox 官网](https://chatboxai.app/)
* [如何在 Chatbox 中接入 SiliconCloud - 超简单完整教程](https://bennhuang.com/posts/chatbox-siliconcloud-integration-guide/)
# ChatHub
Source: https://docs.siliconflow.cn/cn/usercases/use-siliconcloud-in-chathub
## 关于 ChatHub
[ChatHub](https://chathub.gg/zh) 是一个流行的大语言模型聚合插件,特点是可以同时和多个模型聊天,方便对比回答。ChatHub 在全球拥有数十万活跃用户。
## 安装 ChatHub
浏览器打开 [ChatHub 官网](https://chathub.gg/zh),点击“新增至Chrome”按钮安装 ChatHub 浏览器插件:
除了这些技巧外,在 Chatbox 简单易用的外表下,还隐藏着非常多强大的功能,有很多值得探索的地方。
## 4 参考资料
* [Chatbox 官网](https://chatboxai.app/)
* [如何在 Chatbox 中接入 SiliconCloud - 超简单完整教程](https://bennhuang.com/posts/chatbox-siliconcloud-integration-guide/)
# ChatHub
Source: https://docs.siliconflow.cn/cn/usercases/use-siliconcloud-in-chathub
## 关于 ChatHub
[ChatHub](https://chathub.gg/zh) 是一个流行的大语言模型聚合插件,特点是可以同时和多个模型聊天,方便对比回答。ChatHub 在全球拥有数十万活跃用户。
## 安装 ChatHub
浏览器打开 [ChatHub 官网](https://chathub.gg/zh),点击“新增至Chrome”按钮安装 ChatHub 浏览器插件:
 安装后,将自动打开 ChatHub 设置页面.
## 在ChatHub中使用SiliconCloud模型
1、在 ChatHub 设置中找到“自定义机器人”模块,点击“添加”按钮
安装后,将自动打开 ChatHub 设置页面.
## 在ChatHub中使用SiliconCloud模型
1、在 ChatHub 设置中找到“自定义机器人”模块,点击“添加”按钮
 2、在弹窗中,依次:
1. 输入机器人名称
2. 选择 SiliconFlow 作为提供方
3. 输入 SiliconFlow 密钥
4. 填写 SiliconFlow 支持的任何模型
2、在弹窗中,依次:
1. 输入机器人名称
2. 选择 SiliconFlow 作为提供方
3. 输入 SiliconFlow 密钥
4. 填写 SiliconFlow 支持的任何模型
 3、点击“确认”后模型即配置成功
3、点击“确认”后模型即配置成功
 4、开始聊天
4、开始聊天
 ## 在 ChatHub 中进行多模型对比
你可以重复上面的步骤在 ChatHub 添加其他模型,然后你就可以使用 ChatHub 的 All-in-One 功能同时和多个模型聊天(最多可以同时和 6 个模型对话):
## 在 ChatHub 中进行多模型对比
你可以重复上面的步骤在 ChatHub 添加其他模型,然后你就可以使用 ChatHub 的 All-in-One 功能同时和多个模型聊天(最多可以同时和 6 个模型对话):
 除了核心的对比功能外,ChatHub 还有提示词库、代码预览等强大的功能,可以在 [ChatHub 官方文档](https://doc.chathub.gg/introduction)了解更多。
# Chatika
Source: https://docs.siliconflow.cn/cn/usercases/use-siliconcloud-in-chatika
## 1. 关于 Chatika
**Chatika** 是一款 iOS 平台的免费 AI 对话客户端,让用户可以自己输入 API 密钥自由调用各供应商,或使用本地部署的 Ollama 的各种 AI 大语言模型进行对话。具备:**高隐私性** 、**高自由度**、**丰富的聊天功能**、**原生开发**等特性。
最新版 Chatika 合作硅基流动,特别为新用户预设了免 API Key 的全模型试用模式。
## 2. 安装与配置
在苹果 AppStore 搜索 **Chatika** 或下方直接扫码即可,**最低系统要求 iOS 17.1** 。
除了核心的对比功能外,ChatHub 还有提示词库、代码预览等强大的功能,可以在 [ChatHub 官方文档](https://doc.chathub.gg/introduction)了解更多。
# Chatika
Source: https://docs.siliconflow.cn/cn/usercases/use-siliconcloud-in-chatika
## 1. 关于 Chatika
**Chatika** 是一款 iOS 平台的免费 AI 对话客户端,让用户可以自己输入 API 密钥自由调用各供应商,或使用本地部署的 Ollama 的各种 AI 大语言模型进行对话。具备:**高隐私性** 、**高自由度**、**丰富的聊天功能**、**原生开发**等特性。
最新版 Chatika 合作硅基流动,特别为新用户预设了免 API Key 的全模型试用模式。
## 2. 安装与配置
在苹果 AppStore 搜索 **Chatika** 或下方直接扫码即可,**最低系统要求 iOS 17.1** 。
 初次运行会进入欢迎页面(根据系统语言自动设置 app 语言,目前支持中英)。
随后被引导到下图的 Provider 设置界面,可以自己输入对应的 API 密钥,也可以配置 Ollama Host 在本地局域网调用。
还可以**点击 SiliconFlow(硅基流动)进行试用,激活试用就有 1w tokens 的试用额度**。模型方面只要硅基流动有的模型,全开放使用,激活试用或直接输入 Api keys 就可以开始对话了。
初次运行会进入欢迎页面(根据系统语言自动设置 app 语言,目前支持中英)。
随后被引导到下图的 Provider 设置界面,可以自己输入对应的 API 密钥,也可以配置 Ollama Host 在本地局域网调用。
还可以**点击 SiliconFlow(硅基流动)进行试用,激活试用就有 1w tokens 的试用额度**。模型方面只要硅基流动有的模型,全开放使用,激活试用或直接输入 Api keys 就可以开始对话了。
 ## 3. 对话界面
**对话界面是本 App 的主界面**。
* **窗口顶部**:供应商名称旁显示 “State” 徽章,标识模型能力。若为多模态模型,将显示“图片”徽章,支持发送图片。
* **中间区域**:为消息交流主体内容。可以在消息下方进行额外的 **“引用”,“创建分支”,“回到某个点重发”,“重新生成回答”** 等额外操作。
* **底部操作栏**:“Persona”(人设)快捷选择栏,已预设了常用 AI 人设,并支持 AI 人设设置
## 3. 对话界面
**对话界面是本 App 的主界面**。
* **窗口顶部**:供应商名称旁显示 “State” 徽章,标识模型能力。若为多模态模型,将显示“图片”徽章,支持发送图片。
* **中间区域**:为消息交流主体内容。可以在消息下方进行额外的 **“引用”,“创建分支”,“回到某个点重发”,“重新生成回答”** 等额外操作。
* **底部操作栏**:“Persona”(人设)快捷选择栏,已预设了常用 AI 人设,并支持 AI 人设设置
 ### 对话设置和模板
点击聊天标题或者右上角的配置按钮,会进入 **当前对话** 的设置界面。可以直接更改对话的模型/人设,需要注意的是 **额外自定义提示词**。这个**额外**的提示词,仅仅作用于当前的对话,不影响其他对话的人设。另外如果对当前这个聊天的设置满意,可以直接保存对话设置为模板供将来复用。
### 对话设置和模板
点击聊天标题或者右上角的配置按钮,会进入 **当前对话** 的设置界面。可以直接更改对话的模型/人设,需要注意的是 **额外自定义提示词**。这个**额外**的提示词,仅仅作用于当前的对话,不影响其他对话的人设。另外如果对当前这个聊天的设置满意,可以直接保存对话设置为模板供将来复用。
 ### 对话管理
点击对话界面左上角的**边栏**按钮,则会打开边栏弹窗。
在这里可以对对话进行**搜索**,**星标**和**批量删除**。长按单个对话,还可以对单个对话进行直接重命名/删除/或用整个对话创建副本分支。
### 对话管理
点击对话界面左上角的**边栏**按钮,则会打开边栏弹窗。
在这里可以对对话进行**搜索**,**星标**和**批量删除**。长按单个对话,还可以对单个对话进行直接重命名/删除/或用整个对话创建副本分支。
 ## 4. 在线搜索
Chatika 支持在线信息搜索,只需填入搜索服务商的 API Key, 即可在聊天调取打开实时在线检索结果。
## 4. 在线搜索
Chatika 支持在线信息搜索,只需填入搜索服务商的 API Key, 即可在聊天调取打开实时在线检索结果。
 ## 5. 未来展望
Chatika 是一款独立软件和兴趣项目,计划在不久的将来会开源本 App。
Chatika 当前主要满足的是在手机端尽可能自由的 AI 对话,待时机更成熟的时候,可能会考虑增加有限的 MCP 支持,实现一定程度的 Agent 化操作。
如果有 Bug 和其他反馈,联系 Email: [dev@chatika.app](mailto:dev@chatika.app)
# Cherry Studio
Source: https://docs.siliconflow.cn/cn/usercases/use-siliconcloud-in-cherry-studio
## 1 关于 Cherry Studio
开发者可以打开 [Github](https://github.com/kangfenmao/cherry-studio) 项目链接点亮 ⭐️ 来支持开源项目
🍒 Cherry Studio 是一款支持多模型服务的桌面客户端,内置了超过 30 个行业的智能助手,旨在帮助用户在多种场景下提升工作效率。它适用于 Windows、Mac 和 Linux 系统,无需复杂设置即可使用。
## 5. 未来展望
Chatika 是一款独立软件和兴趣项目,计划在不久的将来会开源本 App。
Chatika 当前主要满足的是在手机端尽可能自由的 AI 对话,待时机更成熟的时候,可能会考虑增加有限的 MCP 支持,实现一定程度的 Agent 化操作。
如果有 Bug 和其他反馈,联系 Email: [dev@chatika.app](mailto:dev@chatika.app)
# Cherry Studio
Source: https://docs.siliconflow.cn/cn/usercases/use-siliconcloud-in-cherry-studio
## 1 关于 Cherry Studio
开发者可以打开 [Github](https://github.com/kangfenmao/cherry-studio) 项目链接点亮 ⭐️ 来支持开源项目
🍒 Cherry Studio 是一款支持多模型服务的桌面客户端,内置了超过 30 个行业的智能助手,旨在帮助用户在多种场景下提升工作效率。它适用于 Windows、Mac 和 Linux 系统,无需复杂设置即可使用。
🚀 Cherry Studio 集成了主流的 LLM 云服务和 AI Web 服务,同时支持本地模型运行。
🌟 Cherry Studio 提供了诸如完整的 Markdown 渲染、智能体创建、翻译功能、文件上传和多模态对话等个性化功能,并具有友好的界面设计和灵活的主题选项,旨在为用户提供全面而高效的 AI 交互体验。
### 1.1 下载 Cherry Studio
* [官网下载](https://cherry-ai.com/)
* [开源下载](https://github.com/kangfenmao/cherry-studio/releases/latest)
### 1.2 安装教程
* [Windows 安装](https://cherry-ai.com/docs/windows-install)
* [macOS 安装](https://cherry-ai.com/docs/mac-install)
## 2. 配置 SiliconCloud 的模型服务
### 2.1 点击左下角的设置,在模型服务中选择【硅基流动】
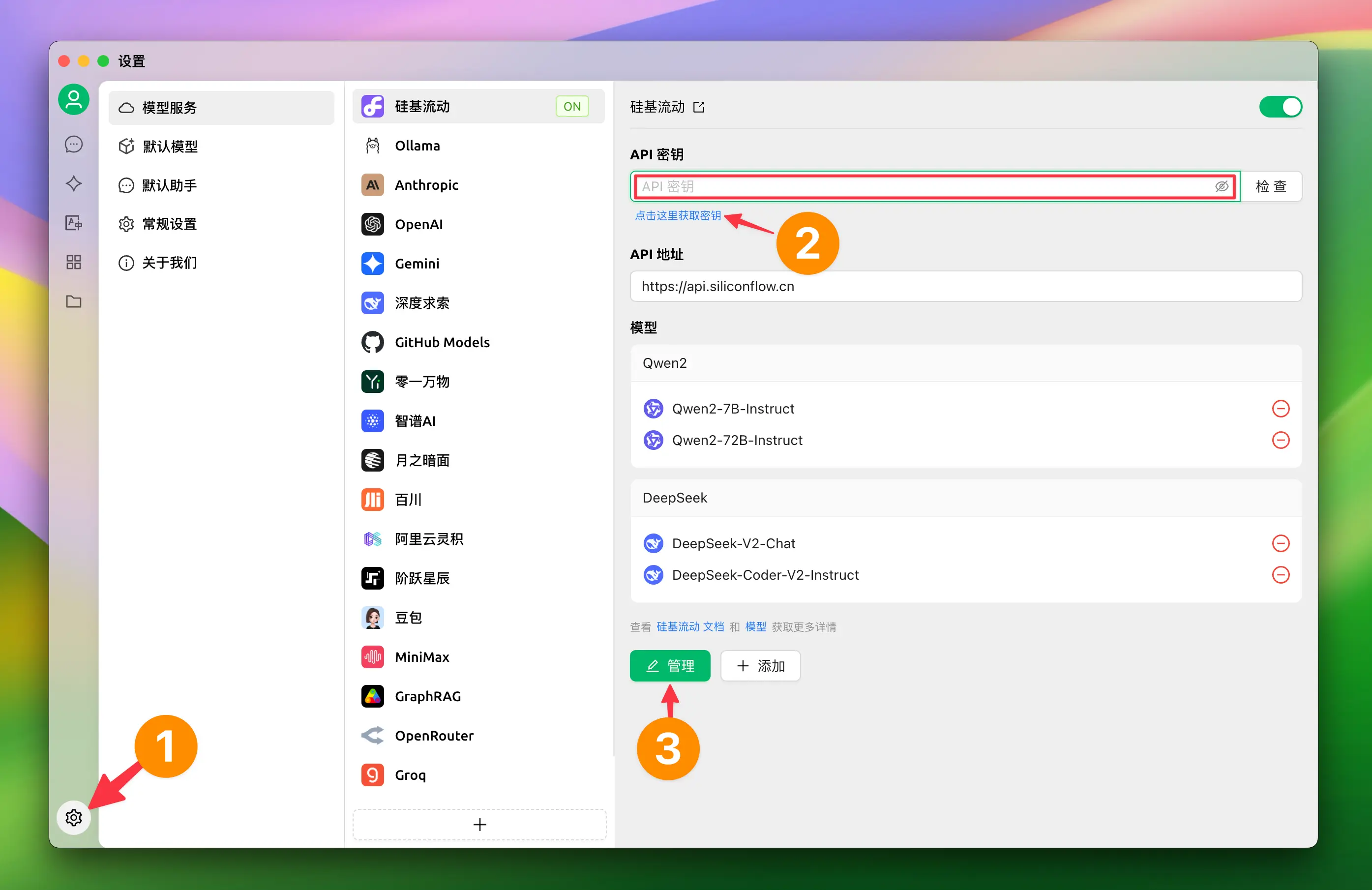 ### 2.2 点击链接获取 SiliconCloud API 密钥
1. 登录[SiliconCloud](https://cloud.siliconflow.cn)(若未注册首次登录会自动注册账号)
2. 访问[API 密钥](https://cloud.siliconflow.cn/account/ak)新建或复制已有密钥
### 2.2 点击链接获取 SiliconCloud API 密钥
1. 登录[SiliconCloud](https://cloud.siliconflow.cn)(若未注册首次登录会自动注册账号)
2. 访问[API 密钥](https://cloud.siliconflow.cn/account/ak)新建或复制已有密钥
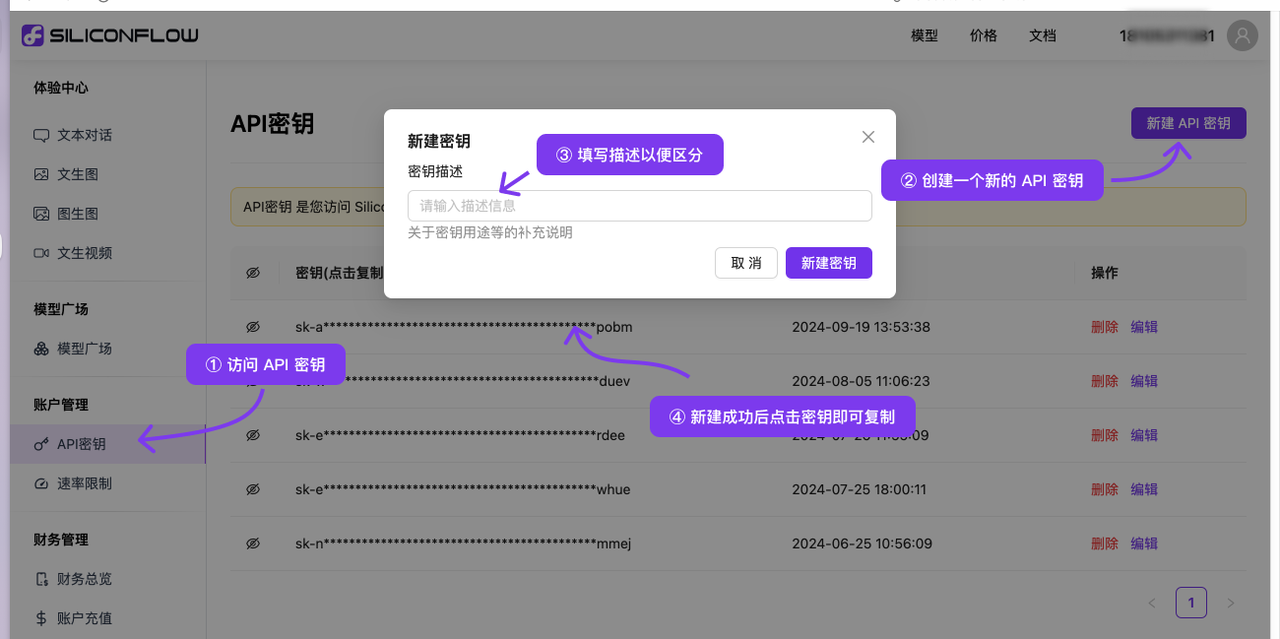 {/* [cherry-studio-api-key](/images/usercases/cherry-studio/cherry-studio-2-api-key.png) */}
### 2.3 点击管理添加模型
{/* [cherry-studio-api-key](/images/usercases/cherry-studio/cherry-studio-2-api-key.png) */}
### 2.3 点击管理添加模型
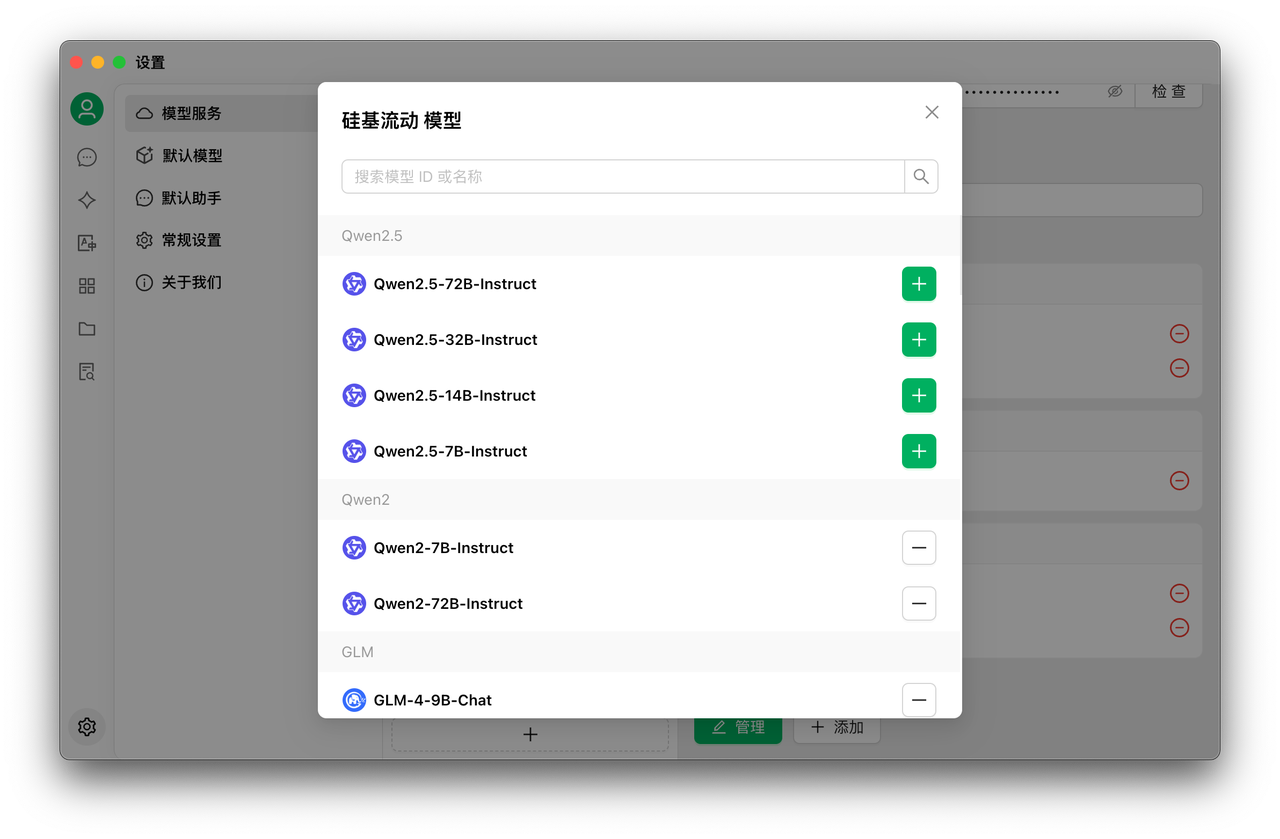 ### 2.4 添加嵌入模型
1. 在模型管理服务中查找模型,可以点击“嵌入模型”快速筛选;
2. 找到需要的模型,添加到我的模型。
### 2.4 添加嵌入模型
1. 在模型管理服务中查找模型,可以点击“嵌入模型”快速筛选;
2. 找到需要的模型,添加到我的模型。
 ## 3. 模型服务使用
### 3.1 使用语言模型服务聊天
1. 点击左侧菜单栏的“对话”按钮
2. 在输入框内输入文字即可开始聊天
3. 可以选择顶部菜单中的模型名字切换模型
## 3. 模型服务使用
### 3.1 使用语言模型服务聊天
1. 点击左侧菜单栏的“对话”按钮
2. 在输入框内输入文字即可开始聊天
3. 可以选择顶部菜单中的模型名字切换模型
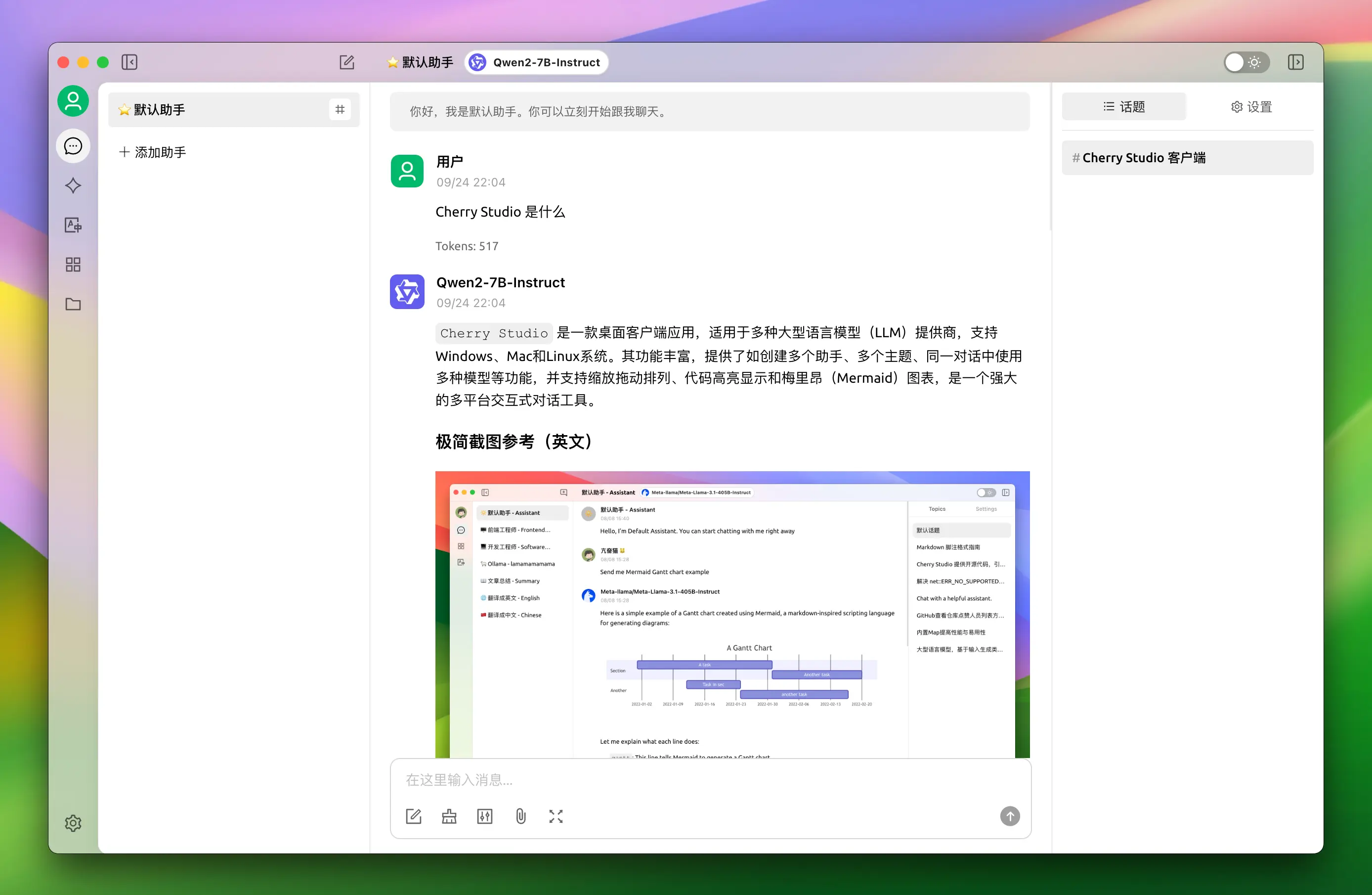 ### 3.2 使用嵌入模型服务创建知识库并使用
#### 3.2.1 创建知识库
1. 知识库入口:在 CherryStudio左侧工具栏,点击知识库图标,即可进入管理页面;
2. 添加知识库:点击添加,开始创建知识库;
3. 命名:输入知识库的名称并添加嵌入模型,以 bge-m3为例,即可完成创建。
### 3.2 使用嵌入模型服务创建知识库并使用
#### 3.2.1 创建知识库
1. 知识库入口:在 CherryStudio左侧工具栏,点击知识库图标,即可进入管理页面;
2. 添加知识库:点击添加,开始创建知识库;
3. 命名:输入知识库的名称并添加嵌入模型,以 bge-m3为例,即可完成创建。

 #### 3.2.2 添加文件并向量化
1. 添加文件:点击添加文件的按钮,打开文件选择;
2. 选择文件:选择支持的文件格式,如 pdf,docx,pptx,xlsx,txt,md,mdx 等,并打开;
3. 向量化:系统会自动进行向量化处理,当显示完成时(绿色✓),代表向量化已完成。
#### 3.2.2 添加文件并向量化
1. 添加文件:点击添加文件的按钮,打开文件选择;
2. 选择文件:选择支持的文件格式,如 pdf,docx,pptx,xlsx,txt,md,mdx 等,并打开;
3. 向量化:系统会自动进行向量化处理,当显示完成时(绿色✓),代表向量化已完成。


 #### 3.2.3 添加多种来源的数据
CherryStudio 支持多种添加数据的方式:
1. 文件夹目录:可以添加整个文件夹目录,该目录下支持格式的文件会被自动向量化;
2. 网址链接:支持网址 url,如[https://docs.siliconflow.cn/introduction](https://docs.siliconflow.cn/introduction);
3. 站点地图:支持 xml 格式的站点地图,如[https://docs.siliconflow.cn/sitemap.xml](https://docs.siliconflow.cn/sitemap.xml);
4. 纯文本笔记:支持输入纯文本的自定义内容。
#### 3.2.3 添加多种来源的数据
CherryStudio 支持多种添加数据的方式:
1. 文件夹目录:可以添加整个文件夹目录,该目录下支持格式的文件会被自动向量化;
2. 网址链接:支持网址 url,如[https://docs.siliconflow.cn/introduction](https://docs.siliconflow.cn/introduction);
3. 站点地图:支持 xml 格式的站点地图,如[https://docs.siliconflow.cn/sitemap.xml](https://docs.siliconflow.cn/sitemap.xml);
4. 纯文本笔记:支持输入纯文本的自定义内容。
 #### 3.2.4 搜索知识库
当文件等资料向量化完成后,即可进行查询:
1. 点击页面下方的搜索知识库按钮;
2. 输入查询的内容;
3. 呈现搜索的结果;
4. 并显示该条结果的匹配分数。
#### 3.2.4 搜索知识库
当文件等资料向量化完成后,即可进行查询:
1. 点击页面下方的搜索知识库按钮;
2. 输入查询的内容;
3. 呈现搜索的结果;
4. 并显示该条结果的匹配分数。

 #### 3.2.5 对话中引用知识库生成回复
1. 创建一个新的话题,在对话工具栏中,点击知识库,会展开已经创建的知识库列表,选择需要引用的知识库;
2. 输入并发送问题,模型即返回通过检索结果生成的答案 ;
3. 同时,引用的数据来源会附在答案下方,可快捷查看源文件。
#### 3.2.5 对话中引用知识库生成回复
1. 创建一个新的话题,在对话工具栏中,点击知识库,会展开已经创建的知识库列表,选择需要引用的知识库;
2. 输入并发送问题,模型即返回通过检索结果生成的答案 ;
3. 同时,引用的数据来源会附在答案下方,可快捷查看源文件。

 # Cline
Source: https://docs.siliconflow.cn/cn/usercases/use-siliconcloud-in-cline
## 1. 安装 Cline
[安装地址](https://marketplace.visualstudio.com/items?itemName=saoudrizwan.claude-dev)
# Cline
Source: https://docs.siliconflow.cn/cn/usercases/use-siliconcloud-in-cline
## 1. 安装 Cline
[安装地址](https://marketplace.visualstudio.com/items?itemName=saoudrizwan.claude-dev)
 ## 2. 打开cline
在VSCode中,通过 Ctrl/Command+Shift+P 打开命令工具,在新 tab 中打开 Cline 进行配置
## 2. 打开cline
在VSCode中,通过 Ctrl/Command+Shift+P 打开命令工具,在新 tab 中打开 Cline 进行配置
 ## 3. 在新窗口中进行配置
1. API Provider:选择 “OpenAI Compatible”
2. Base Url:[https://api.siliconflow.cn/v1](https://api.siliconflow.cn/v1)
3. API Key:从 [https://cloud.siliconflow.cn/account/ak](https://cloud.siliconflow.cn/account/ak) 中获取
4. Model ID:从 [https://cloud.siliconflow.cn/models](https://cloud.siliconflow.cn/models) 中获取
## 3. 在新窗口中进行配置
1. API Provider:选择 “OpenAI Compatible”
2. Base Url:[https://api.siliconflow.cn/v1](https://api.siliconflow.cn/v1)
3. API Key:从 [https://cloud.siliconflow.cn/account/ak](https://cloud.siliconflow.cn/account/ak) 中获取
4. Model ID:从 [https://cloud.siliconflow.cn/models](https://cloud.siliconflow.cn/models) 中获取
 ## 4. 开始使用
## 4. 开始使用
 # 麦悠电台
Source: https://docs.siliconflow.cn/cn/usercases/use-siliconcloud-in-cube-sugar-studio
麦悠电台(my.ft07.com)是独立开发者方糖开发的一款独具特色的 AI 电台 App,借助 AI 大模型为你打造专属播客。
通过与 RSS Hub、Wewe-rss 订阅器的配合,麦悠电台用户可在麦悠电台订阅上千个媒体平台和微信公众号来获取资讯。电台支持本地/云端 TTS 合成,可自由选择多种 AI 音效。在电台中生成的播客还支持分享、导出音频/视频格式,为内容创作者提供了极大便利。
本文将介绍如何借助 SiliconCloud 提供的 API 服务,在麦悠电台创建你的个性化播客节目。
## 1. 获取 API Key
1. 打开 SiliconCloud [官网](https://cloud.siliconflow.cn/) 并注册账号(如果注册过,直接登录即可)。
2. 完成注册后,打开[API密钥](https://cloud.siliconflow.cn/account/ak) ,创建新的 API Key,点击密钥进行复制,以备后续使用。
## 2. 在 Sider 中使用 SiliconCloud 语言模型系列
### 2.1 下载安装麦悠电台
IOS 用户可打开苹果商店进行搜索安装。Android 用户可[下载 APK](https://the7.ft07.com/Maidio/maidio-byok-1.0.9-b29.apk) 安装。
### 2.2 配置 SiliconCloud 的 API 服务
打开麦悠电台 App 首页,点击左上角任务栏中的“设置”,在“AI 设置”中粘贴从 SiliconCloud 获取的 API Key,保存设置,就可以使用 SiliconCloud 上的相应模型了。
# 麦悠电台
Source: https://docs.siliconflow.cn/cn/usercases/use-siliconcloud-in-cube-sugar-studio
麦悠电台(my.ft07.com)是独立开发者方糖开发的一款独具特色的 AI 电台 App,借助 AI 大模型为你打造专属播客。
通过与 RSS Hub、Wewe-rss 订阅器的配合,麦悠电台用户可在麦悠电台订阅上千个媒体平台和微信公众号来获取资讯。电台支持本地/云端 TTS 合成,可自由选择多种 AI 音效。在电台中生成的播客还支持分享、导出音频/视频格式,为内容创作者提供了极大便利。
本文将介绍如何借助 SiliconCloud 提供的 API 服务,在麦悠电台创建你的个性化播客节目。
## 1. 获取 API Key
1. 打开 SiliconCloud [官网](https://cloud.siliconflow.cn/) 并注册账号(如果注册过,直接登录即可)。
2. 完成注册后,打开[API密钥](https://cloud.siliconflow.cn/account/ak) ,创建新的 API Key,点击密钥进行复制,以备后续使用。
## 2. 在 Sider 中使用 SiliconCloud 语言模型系列
### 2.1 下载安装麦悠电台
IOS 用户可打开苹果商店进行搜索安装。Android 用户可[下载 APK](https://the7.ft07.com/Maidio/maidio-byok-1.0.9-b29.apk) 安装。
### 2.2 配置 SiliconCloud 的 API 服务
打开麦悠电台 App 首页,点击左上角任务栏中的“设置”,在“AI 设置”中粘贴从 SiliconCloud 获取的 API Key,保存设置,就可以使用 SiliconCloud 上的相应模型了。
 ### 2.3 设置语音
1. 点击顶部导航栏的“语音”标签,在“本地语音”页面选择主持人和助理的语音引擎,调整语速、音调和音量,点击“声音”按钮可以试听效果。
### 2.3 设置语音
1. 点击顶部导航栏的“语音”标签,在“本地语音”页面选择主持人和助理的语音引擎,调整语速、音调和音量,点击“声音”按钮可以试听效果。
 Android 系统,请先在系统设置中安装中文语音包,推荐使用小米和 Google 的语音引擎,选择合适的中文语音。
如iOS 系统,进入设置→辅助功能→朗读所选内容→声音→中文→月/瀚→下载高质量语音,重启应用,即可在本地 TTS 中选择使用 Yue/Han 的高质量语音。
2. 接入 SiliconCloud 提供的 API Key 后,通过平台的音频模型 `fishaudio/fish-speech-1.5`,用户可以进一步测试 "云端语音",享受 8 种开箱即用预置音色。
{/* */}
### 2.4 创建电台,获取新闻
1. 点击主界面右上角的“+”按钮,自定义电台名称,添加 RSS 订阅源,直接输入 RSS 地址(每行一个)或导入 OPML 文件。
2. 在主界面点击电台右侧的 RSS 图标,点击右上角的刷新按钮,获取最新内容,等待新闻加载完成。
### 2.5 生成节目,收听节目
1. 在新闻列表中选择感兴趣的新闻,点击底部的”创建节目”按钮,根据自己的兴趣选择新闻喜好(分为详细、摘要、略过、原文四个选项),等待 AI 生成对话内容。
Android 系统,请先在系统设置中安装中文语音包,推荐使用小米和 Google 的语音引擎,选择合适的中文语音。
如iOS 系统,进入设置→辅助功能→朗读所选内容→声音→中文→月/瀚→下载高质量语音,重启应用,即可在本地 TTS 中选择使用 Yue/Han 的高质量语音。
2. 接入 SiliconCloud 提供的 API Key 后,通过平台的音频模型 `fishaudio/fish-speech-1.5`,用户可以进一步测试 "云端语音",享受 8 种开箱即用预置音色。
{/* */}
### 2.4 创建电台,获取新闻
1. 点击主界面右上角的“+”按钮,自定义电台名称,添加 RSS 订阅源,直接输入 RSS 地址(每行一个)或导入 OPML 文件。
2. 在主界面点击电台右侧的 RSS 图标,点击右上角的刷新按钮,获取最新内容,等待新闻加载完成。
### 2.5 生成节目,收听节目
1. 在新闻列表中选择感兴趣的新闻,点击底部的”创建节目”按钮,根据自己的兴趣选择新闻喜好(分为详细、摘要、略过、原文四个选项),等待 AI 生成对话内容。
 2. 返回主界面,点击电台右侧的播放按钮,即可享受 AI 主持人为你播报定制化的新闻内容。
{/* */}
### 3. 总结
如果你想开发一个麦悠电台这样的 AI 应用,想快速地测试各类大模型效果或让用户使用高性价比的模型服务,可以选择接入 SiliconCloud 的 API 模型进行快速体验。
# Deep Research Web UI
Source: https://docs.siliconflow.cn/cn/usercases/use-siliconcloud-in-deep-research-web-ui
## 1. 介绍
Deep Research Web UI 是一个由人工智能驱动的研究助手,通过结合搜索引擎、网络抓取和大语言模型,可以让 AI 根据某个问题自己搜索资料并且不断深挖,最后输出一份研究报告。
本项目的特性:
* 💰 **低成本**:可以用很低的成本实现类似 ChatGPT、Perplexity、秘塔等产品的“深度研究”效果
* 🚀 **隐私安全**:所有配置和 API 请求均在浏览器端完成,并且可以自部署
* 🕙 **实时反馈**:流式传输 AI 响应并在界面实时展示
* 🌳 **搜索可视化**:使用树状结构展示研究过程,支持使用英文搜索词
* 📄 **支持导出 PDF**:将最终研究报告导出为 Markdown 和 PDF 格式
* 🤖 **多模型支持**:底层使用纯提示词而非结构化输出等新特性,兼容更多大模型供应商
项目开源地址: [GitHub](https://github.com/AnotiaWang/deep-research-web-ui)
## 2. 如何使用
打开 [Deep Research Web UI 官网](https://deep-research.ataw.top),点击右上角的“⚙️”按钮打开设置弹窗。
2. 返回主界面,点击电台右侧的播放按钮,即可享受 AI 主持人为你播报定制化的新闻内容。
{/* */}
### 3. 总结
如果你想开发一个麦悠电台这样的 AI 应用,想快速地测试各类大模型效果或让用户使用高性价比的模型服务,可以选择接入 SiliconCloud 的 API 模型进行快速体验。
# Deep Research Web UI
Source: https://docs.siliconflow.cn/cn/usercases/use-siliconcloud-in-deep-research-web-ui
## 1. 介绍
Deep Research Web UI 是一个由人工智能驱动的研究助手,通过结合搜索引擎、网络抓取和大语言模型,可以让 AI 根据某个问题自己搜索资料并且不断深挖,最后输出一份研究报告。
本项目的特性:
* 💰 **低成本**:可以用很低的成本实现类似 ChatGPT、Perplexity、秘塔等产品的“深度研究”效果
* 🚀 **隐私安全**:所有配置和 API 请求均在浏览器端完成,并且可以自部署
* 🕙 **实时反馈**:流式传输 AI 响应并在界面实时展示
* 🌳 **搜索可视化**:使用树状结构展示研究过程,支持使用英文搜索词
* 📄 **支持导出 PDF**:将最终研究报告导出为 Markdown 和 PDF 格式
* 🤖 **多模型支持**:底层使用纯提示词而非结构化输出等新特性,兼容更多大模型供应商
项目开源地址: [GitHub](https://github.com/AnotiaWang/deep-research-web-ui)
## 2. 如何使用
打开 [Deep Research Web UI 官网](https://deep-research.ataw.top),点击右上角的“⚙️”按钮打开设置弹窗。
 ### 2.1 配置 AI 大模型服务
1. 在硅基流动官网注册或者登录一个账号。
2. 在 [API 密钥](https://cloud.siliconflow.cn/account/ak)中生成一个新的 API key,然后复制一下。
3. 回到 Deep Research 网页,在设置的 AI 服务部分,选择“SiliconFlow 硅基流动”,在“API 密钥”一栏里粘贴刚才生成的 API key。
### 2.1 配置 AI 大模型服务
1. 在硅基流动官网注册或者登录一个账号。
2. 在 [API 密钥](https://cloud.siliconflow.cn/account/ak)中生成一个新的 API key,然后复制一下。
3. 回到 Deep Research 网页,在设置的 AI 服务部分,选择“SiliconFlow 硅基流动”,在“API 密钥”一栏里粘贴刚才生成的 API key。
 4. 在“模型名称”一栏,点击右侧的下拉按钮(也可以在输入框里输入模型名称来筛选),选择想要使用的模型。
4. 在“模型名称”一栏,点击右侧的下拉按钮(也可以在输入框里输入模型名称来筛选),选择想要使用的模型。
 5. (可选)设置上下文长度:如果要做大规模的研究,建议配置“上下文长度”选项,不要超过所选模型的最大上下文长度,避免请求失败。
### 2.2 配置联网搜索模型
目前支持 Tavily 和 Firecrawl,后续会增加支持更多搜索服务。这里我们选择 Tavily,因为它提供了每月 1000 次的免费搜索,足够大部分场景使用。
1. 在 [Tavily 官网](https://app.tavily.com/home)注册一个账号。然后在控制台里新建一个 API key 并复制。
* Key Name 可以填写 Deep Research。
* Key Type 根据你的使用情况决定,如果是轻度使用,可以选择“Development”;重度使用则选择“Production”,支持更高的请求频率。
* 注意保管好 API key 不要泄露。
5. (可选)设置上下文长度:如果要做大规模的研究,建议配置“上下文长度”选项,不要超过所选模型的最大上下文长度,避免请求失败。
### 2.2 配置联网搜索模型
目前支持 Tavily 和 Firecrawl,后续会增加支持更多搜索服务。这里我们选择 Tavily,因为它提供了每月 1000 次的免费搜索,足够大部分场景使用。
1. 在 [Tavily 官网](https://app.tavily.com/home)注册一个账号。然后在控制台里新建一个 API key 并复制。
* Key Name 可以填写 Deep Research。
* Key Type 根据你的使用情况决定,如果是轻度使用,可以选择“Development”;重度使用则选择“Production”,支持更高的请求频率。
* 注意保管好 API key 不要泄露。
 2. 回到 Deep Research 网页,在设置的“联网搜索服务”部分,选择 “Tavily”;在“API 密钥”一栏填写刚才生成的 API key。
3. (可选)设置搜索时使用的语言。AI 模型默认会使用你网页的当前语言来搜索和回复,不过如果你想用英文搜索词来查找更高质量的资料,可以把“使用语言”设置成 English。
这样就设置完毕,可以开始使用了!
### 3. 开始使用
本项目在每一步都做了说明,力求降低使用门槛。可以用它来查找第一手资料、了解自己感兴趣的话题、查找新闻并汇总等等。例如,查找一下 NVIDIA RTX 50 系列显卡的信息:
2. 回到 Deep Research 网页,在设置的“联网搜索服务”部分,选择 “Tavily”;在“API 密钥”一栏填写刚才生成的 API key。
3. (可选)设置搜索时使用的语言。AI 模型默认会使用你网页的当前语言来搜索和回复,不过如果你想用英文搜索词来查找更高质量的资料,可以把“使用语言”设置成 English。
这样就设置完毕,可以开始使用了!
### 3. 开始使用
本项目在每一步都做了说明,力求降低使用门槛。可以用它来查找第一手资料、了解自己感兴趣的话题、查找新闻并汇总等等。例如,查找一下 NVIDIA RTX 50 系列显卡的信息:

 本项目正在活跃更新中,如果遇到问题可以前往 [GitHub 仓库](https://github.com/AnotiaWang/deep-research-web-ui)反馈。
# Dify
Source: https://docs.siliconflow.cn/cn/usercases/use-siliconcloud-in-dify
结合 SiliconCloud 模型多、速度快的优势,在 Dify 中快速实现工作流/Agent
## 1. 获取 API Key
1. 打开 SiliconCloud [官网](https://cloud.siliconflow.cn/) 并注册账号(如果注册过,直接登录即可)。
2. 完成注册后,打开[API密钥](https://cloud.siliconflow.cn/account/ak) ,创建新的 API Key,点击密钥进行复制,以备后续使用。
## 2. 在 Dify 中使用 SiliconCloud 语言模型系列
### 2.1 调用 Dify 中内置的 SiliconCloud 模型的 API
1. 打开 SiliconCloud 官网 并注册账号(如果注册过,直接登录即可)。 完成注册后,打开 API 密钥 ,创建新的 API Key,点击密钥进行复制,以备后续使用。
2. 在 Dify 首页右上角选择“设置”,选择左上角“模型供应商”。
3. 找到“ SiliconCloud ”,粘贴先前在 SiliconCloud 平台复制的 API Key,然后点击“保存”按钮。
4. 校验成功后可以在模型提供商的顶部区域看到 SiliconCloud 提供的模型,并在应用中使用 SiliconCloud 模型。
### 2.2 使用目前不在 Dify 源代码中的 SiliconCloud 模型
1. 打开 Dify 的“ Settings ”进行设置。
2. 选择导航栏“ Model Provider ”,添加兼容 OpenAI 接口的模型服务平台。
3. 在其中设置对应的 SiliconCloud 对应的 Model Name 、 API Key 、 API 端点。
* **Model Name:** 从[model-list](/api-reference/models/get-model-list) 文档中选择
* **API Key:** 从[https://cloud.siliconflow.cn/account/ak](https://cloud.siliconflow.cn/account/ak) 中获取,请注意,如果您需要使用海外模型,请先进行实名认证
* **API 端点 URL:** [https://api.siliconflow.cn/v1](https://api.siliconflow.cn/v1)
4. 设置完成后,可以在模型列表中看到上述新增的模型。
## 3. 在 Dify 中使用 SiliconCloud 生图模型系列
参考[在 Dify 中使用 SiliconCloud 生图模型系列](https://docs.dify.ai/zh-hans/guides/tools/tool-configuration/siliconflow)
# eechat
Source: https://docs.siliconflow.cn/cn/usercases/use-siliconcloud-in-eechat
## 关于 eechat
[eechat](https://github.com/Lucassssss/eechat) 是一款开源免费的国产 AI 应用,支持 Windows、macOS 和 Linux,集成了聊天、多模态指令执行(MCP)、知识库问答(RAG)、语音识别(ASR)、语音合成(TTS)等功能模块。
* **开箱即用**,无需代码基础,适合非技术背景用户。
* **免费开源**,国产的免费开源应用,数据都存储在本地
* **多模型支持**,同时支持 API 模型和本地模型聊天,可以自定义配置自己喜欢的模型
* **丰富的支持**,支持 MCP、RAG 和插件支持
本文档将演示硅基流动在 eechat 中的使用。
## 下载 eechat
* **[官网下载](https://ee.chat)**
* **[开源下载](https://github.com/Lucassssss/eechat/releases)**
## 安装 eechat 并配置硅基流动模型
### 1. 安装 eechat(以 Windows 为例)
* 下载并运行安装包,点击安装。
本项目正在活跃更新中,如果遇到问题可以前往 [GitHub 仓库](https://github.com/AnotiaWang/deep-research-web-ui)反馈。
# Dify
Source: https://docs.siliconflow.cn/cn/usercases/use-siliconcloud-in-dify
结合 SiliconCloud 模型多、速度快的优势,在 Dify 中快速实现工作流/Agent
## 1. 获取 API Key
1. 打开 SiliconCloud [官网](https://cloud.siliconflow.cn/) 并注册账号(如果注册过,直接登录即可)。
2. 完成注册后,打开[API密钥](https://cloud.siliconflow.cn/account/ak) ,创建新的 API Key,点击密钥进行复制,以备后续使用。
## 2. 在 Dify 中使用 SiliconCloud 语言模型系列
### 2.1 调用 Dify 中内置的 SiliconCloud 模型的 API
1. 打开 SiliconCloud 官网 并注册账号(如果注册过,直接登录即可)。 完成注册后,打开 API 密钥 ,创建新的 API Key,点击密钥进行复制,以备后续使用。
2. 在 Dify 首页右上角选择“设置”,选择左上角“模型供应商”。
3. 找到“ SiliconCloud ”,粘贴先前在 SiliconCloud 平台复制的 API Key,然后点击“保存”按钮。
4. 校验成功后可以在模型提供商的顶部区域看到 SiliconCloud 提供的模型,并在应用中使用 SiliconCloud 模型。
### 2.2 使用目前不在 Dify 源代码中的 SiliconCloud 模型
1. 打开 Dify 的“ Settings ”进行设置。
2. 选择导航栏“ Model Provider ”,添加兼容 OpenAI 接口的模型服务平台。
3. 在其中设置对应的 SiliconCloud 对应的 Model Name 、 API Key 、 API 端点。
* **Model Name:** 从[model-list](/api-reference/models/get-model-list) 文档中选择
* **API Key:** 从[https://cloud.siliconflow.cn/account/ak](https://cloud.siliconflow.cn/account/ak) 中获取,请注意,如果您需要使用海外模型,请先进行实名认证
* **API 端点 URL:** [https://api.siliconflow.cn/v1](https://api.siliconflow.cn/v1)
4. 设置完成后,可以在模型列表中看到上述新增的模型。
## 3. 在 Dify 中使用 SiliconCloud 生图模型系列
参考[在 Dify 中使用 SiliconCloud 生图模型系列](https://docs.dify.ai/zh-hans/guides/tools/tool-configuration/siliconflow)
# eechat
Source: https://docs.siliconflow.cn/cn/usercases/use-siliconcloud-in-eechat
## 关于 eechat
[eechat](https://github.com/Lucassssss/eechat) 是一款开源免费的国产 AI 应用,支持 Windows、macOS 和 Linux,集成了聊天、多模态指令执行(MCP)、知识库问答(RAG)、语音识别(ASR)、语音合成(TTS)等功能模块。
* **开箱即用**,无需代码基础,适合非技术背景用户。
* **免费开源**,国产的免费开源应用,数据都存储在本地
* **多模型支持**,同时支持 API 模型和本地模型聊天,可以自定义配置自己喜欢的模型
* **丰富的支持**,支持 MCP、RAG 和插件支持
本文档将演示硅基流动在 eechat 中的使用。
## 下载 eechat
* **[官网下载](https://ee.chat)**
* **[开源下载](https://github.com/Lucassssss/eechat/releases)**
## 安装 eechat 并配置硅基流动模型
### 1. 安装 eechat(以 Windows 为例)
* 下载并运行安装包,点击安装。
 * 点击“浏览”,选择安装路径,确认后开始安装。
* 点击“浏览”,选择安装路径,确认后开始安装。
 * 安装完成后,打开 eechat,按图示操作
* 安装完成后,打开 eechat,按图示操作
 1. 点击左侧菜单的最后一个图标“设置”
2. 选中设置下的 “API 模型”
3. 在 API 模型提供商中选择 "硅基流动"
4. 点击获取 API Key,打开硅基流动登录页面,如果已登录会进入硅基流动控制台页面
### 2. 获取 API Key
* 点击获取 API Key 后,会在浏览器打开硅基流动登录页面,登录您的账户信息
1. 点击左侧菜单的最后一个图标“设置”
2. 选中设置下的 “API 模型”
3. 在 API 模型提供商中选择 "硅基流动"
4. 点击获取 API Key,打开硅基流动登录页面,如果已登录会进入硅基流动控制台页面
### 2. 获取 API Key
* 点击获取 API Key 后,会在浏览器打开硅基流动登录页面,登录您的账户信息
 * 创建 API Key
* 创建 API Key
 ### 3. 配置 API Key
* 在 eechat 中配置提供商和 API Key
### 3. 配置 API Key
* 在 eechat 中配置提供商和 API Key
 1. 在 eechat 的 API 模型提供商中选择 "硅基流动"
2. 在 API Key 中粘贴刚刚创建的 API Key
3. 在 API URL 中输入 `https://api.siliconflow.cn/v1`
4. 点击测试连接,如果测试成功就可以直接对话了,如果测试失败,请检查 API Key 或 API URL 是否正确。
> 硅基流动的 API 接口默认是`https://api.siliconflow.cn/v1`,如有变动以 API 手册为准。
### 4. 配置模型
* 在 eechat 中点击“模型列表”
1. 在 eechat 的 API 模型提供商中选择 "硅基流动"
2. 在 API Key 中粘贴刚刚创建的 API Key
3. 在 API URL 中输入 `https://api.siliconflow.cn/v1`
4. 点击测试连接,如果测试成功就可以直接对话了,如果测试失败,请检查 API Key 或 API URL 是否正确。
> 硅基流动的 API 接口默认是`https://api.siliconflow.cn/v1`,如有变动以 API 手册为准。
### 4. 配置模型
* 在 eechat 中点击“模型列表”
 * 在弹出的浏览器窗口中,选择所需模型(如 Qwen3),如下图 ①
* 复制对应模型卡片的模型 ID,如下图 ②
* 在弹出的浏览器窗口中,选择所需模型(如 Qwen3),如下图 ①
* 复制对应模型卡片的模型 ID,如下图 ②
 * 点击 eechat "新增模型" 按钮,在弹出的窗口中,粘贴刚刚复制的模型 ID,点击确定
* 点击 eechat "新增模型" 按钮,在弹出的窗口中,粘贴刚刚复制的模型 ID,点击确定
 这样模型就添加成功了。
## 在聊天中使用模型
这样模型就添加成功了。
## 在聊天中使用模型
 打开对话菜单,选择模型,开始聊天吧!
打开对话菜单,选择模型,开始聊天吧!
 ## 相关参考
* 💻 [eechat 官网](https://ee.chat)
* 🧑💻 [eechat GitHub](https://github.com/Lucassssss/eechat)
* ☁️ [硅基流动 API 密钥](https://cloud.siliconflow.cn/account/ak)
* 📘 [硅基流动官方文档](https://docs.siliconflow.cn)
如何你觉得 [eechat](https://github.com/Lucassssss/eechat) 不错,欢迎给一个 Star ⭐️ 支持开源项目发展!
# FastGPT
Source: https://docs.siliconflow.cn/cn/usercases/use-siliconcloud-in-fastgpt
本文转载自 [FastGPT](https://fastgpt.run) 的官方文档,介绍了如何在 FastGPT 中使用 SiliconCloud 的模型。[原文地址](https://doc.tryfastgpt.ai/docs/development/modelconfig/siliconcloud/)
[SiliconCloud](https://cloud.siliconflow.cn/i/TR9Ym0c4) 是一个以提供开源模型调用为主的平台,并拥有自己的加速引擎。帮助用户低成本、快速的进行开源模型的测试和使用。实际体验下来,他们家模型的速度和稳定性都非常不错,并且种类丰富,覆盖语言、向量、重排、TTS、STT、绘图、视频生成模型,可以满足 FastGPT 中所有模型需求。
如果你想部分模型使用 SiliconCloud 的模型,可额外参考[OneAPI接入硅基流动](https://doc.tryfastgpt.ai/docs/development/modelconfig/one-api/#%E7%A1%85%E5%9F%BA%E6%B5%81%E5%8A%A8--%E5%BC%80%E6%BA%90%E6%A8%A1%E5%9E%8B%E5%A4%A7%E5%90%88%E9%9B%86)。
本文会介绍完全使用 SiliconCloud 模型来部署 FastGPT 的方案。
## 1. 注册 SiliconCloud 账号
1. [点击注册硅基流动账号](https://cloud.siliconflow.cn/i/TR9Ym0c4)
2. 进入控制台,获取 API key: [https://cloud.siliconflow.cn/account/ak](https://cloud.siliconflow.cn/account/ak)
## 2. 修改 FastGPT 环境变量
```bash
OPENAI_BASE_URL=https://api.siliconflow.cn/v1
# 填写 SiliconCloud 控制台提供的 Api Key
CHAT_API_KEY=sk-xxxxxx
```
## 3. 修改 FastGPT 配置文件
我们选取 SiliconCloud 中的模型作为 FastGPT 配置。这里配置了 `Qwen2.5 72b` 的纯语言和视觉模型;选择 `bge-m3` 作为向量模型;选择 `bge-reranker-v2-m3` 作为重排模型。选择 `fish-speech-1.5` 作为语音模型;选择 `SenseVoiceSmall` 作为语音输入模型。
注意:ReRank 模型仍需配置一次 Api Key
```json
{
"llmModels": [
{
"provider": "Other", // 模型提供商,主要用于分类展示,目前已经内置提供商包括:https://github.com/labring/FastGPT/blob/main/packages/global/core/ai/provider.ts, 可 pr 提供新的提供商,或直接填写 Other
"model": "Qwen/Qwen2.5-72B-Instruct", // 模型名(对应OneAPI中渠道的模型名)
"name": "Qwen2.5-72B-Instruct", // 模型别名
"maxContext": 32000, // 最大上下文
"maxResponse": 4000, // 最大回复
"quoteMaxToken": 30000, // 最大引用内容
"maxTemperature": 1, // 最大温度
"charsPointsPrice": 0, // n积分/1k token(商业版)
"censor": false, // 是否开启敏感校验(商业版)
"vision": false, // 是否支持图片输入
"datasetProcess": true, // 是否设置为文本理解模型(QA),务必保证至少有一个为true,否则知识库会报错
"usedInClassify": true, // 是否用于问题分类(务必保证至少有一个为true)
"usedInExtractFields": true, // 是否用于内容提取(务必保证至少有一个为true)
"usedInToolCall": true, // 是否用于工具调用(务必保证至少有一个为true)
"usedInQueryExtension": true, // 是否用于问题优化(务必保证至少有一个为true)
"toolChoice": true, // 是否支持工具选择(分类,内容提取,工具调用会用到。)
"functionCall": false, // 是否支持函数调用(分类,内容提取,工具调用会用到。会优先使用 toolChoice,如果为false,则使用 functionCall,如果仍为 false,则使用提示词模式)
"customCQPrompt": "", // 自定义文本分类提示词(不支持工具和函数调用的模型
"customExtractPrompt": "", // 自定义内容提取提示词
"defaultSystemChatPrompt": "", // 对话默认携带的系统提示词
"defaultConfig": {}, // 请求API时,挟带一些默认配置(比如 GLM4 的 top_p)
"fieldMap": {} // 字段映射(o1 模型需要把 max_tokens 映射为 max_completion_tokens)
},
{
"provider": "Other",
"model": "Qwen/Qwen2-VL-72B-Instruct",
"name": "Qwen2-VL-72B-Instruct",
"maxContext": 32000,
"maxResponse": 4000,
"quoteMaxToken": 30000,
"maxTemperature": 1,
"charsPointsPrice": 0,
"censor": false,
"vision": true,
"datasetProcess": false,
"usedInClassify": false,
"usedInExtractFields": false,
"usedInToolCall": false,
"usedInQueryExtension": false,
"toolChoice": false,
"functionCall": false,
"customCQPrompt": "",
"customExtractPrompt": "",
"defaultSystemChatPrompt": "",
"defaultConfig": {}
}
],
"vectorModels": [
{
"provider": "Other",
"model": "Pro/BAAI/bge-m3",
"name": "Pro/BAAI/bge-m3",
"charsPointsPrice": 0,
"defaultToken": 512,
"maxToken": 5000,
"weight": 100
}
],
"reRankModels": [
{
"model": "BAAI/bge-reranker-v2-m3", // 这里的model需要对应 siliconflow 的模型名
"name": "BAAI/bge-reranker-v2-m3",
"requestUrl": "https://api.siliconflow.cn/v1/rerank",
"requestAuth": "siliconflow 上申请的 key"
}
],
"audioSpeechModels": [
{
"model": "fishaudio/fish-speech-1.5",
"name": "fish-speech-1.5",
"voices": [
{
"label": "fish-alex",
"value": "fishaudio/fish-speech-1.5:alex",
"bufferId": "fish-alex"
},
{
"label": "fish-anna",
"value": "fishaudio/fish-speech-1.5:anna",
"bufferId": "fish-anna"
},
{
"label": "fish-bella",
"value": "fishaudio/fish-speech-1.5:bella",
"bufferId": "fish-bella"
},
{
"label": "fish-benjamin",
"value": "fishaudio/fish-speech-1.5:benjamin",
"bufferId": "fish-benjamin"
},
{
"label": "fish-charles",
"value": "fishaudio/fish-speech-1.5:charles",
"bufferId": "fish-charles"
},
{
"label": "fish-claire",
"value": "fishaudio/fish-speech-1.5:claire",
"bufferId": "fish-claire"
},
{
"label": "fish-david",
"value": "fishaudio/fish-speech-1.5:david",
"bufferId": "fish-david"
},
{
"label": "fish-diana",
"value": "fishaudio/fish-speech-1.5:diana",
"bufferId": "fish-diana"
}
]
}
],
"whisperModel": {
"model": "FunAudioLLM/SenseVoiceSmall",
"name": "SenseVoiceSmall",
"charsPointsPrice": 0
}
}
```
## 4. 重启 FastGPT
## 5. 体验测试
### 测试对话和图片识别
随便新建一个简易应用,选择对应模型,并开启图片上传后进行测试:
| | |
| ------------------------------------------------------------------------------------------- | ------------------------------------------------------------------------------------------- |
| 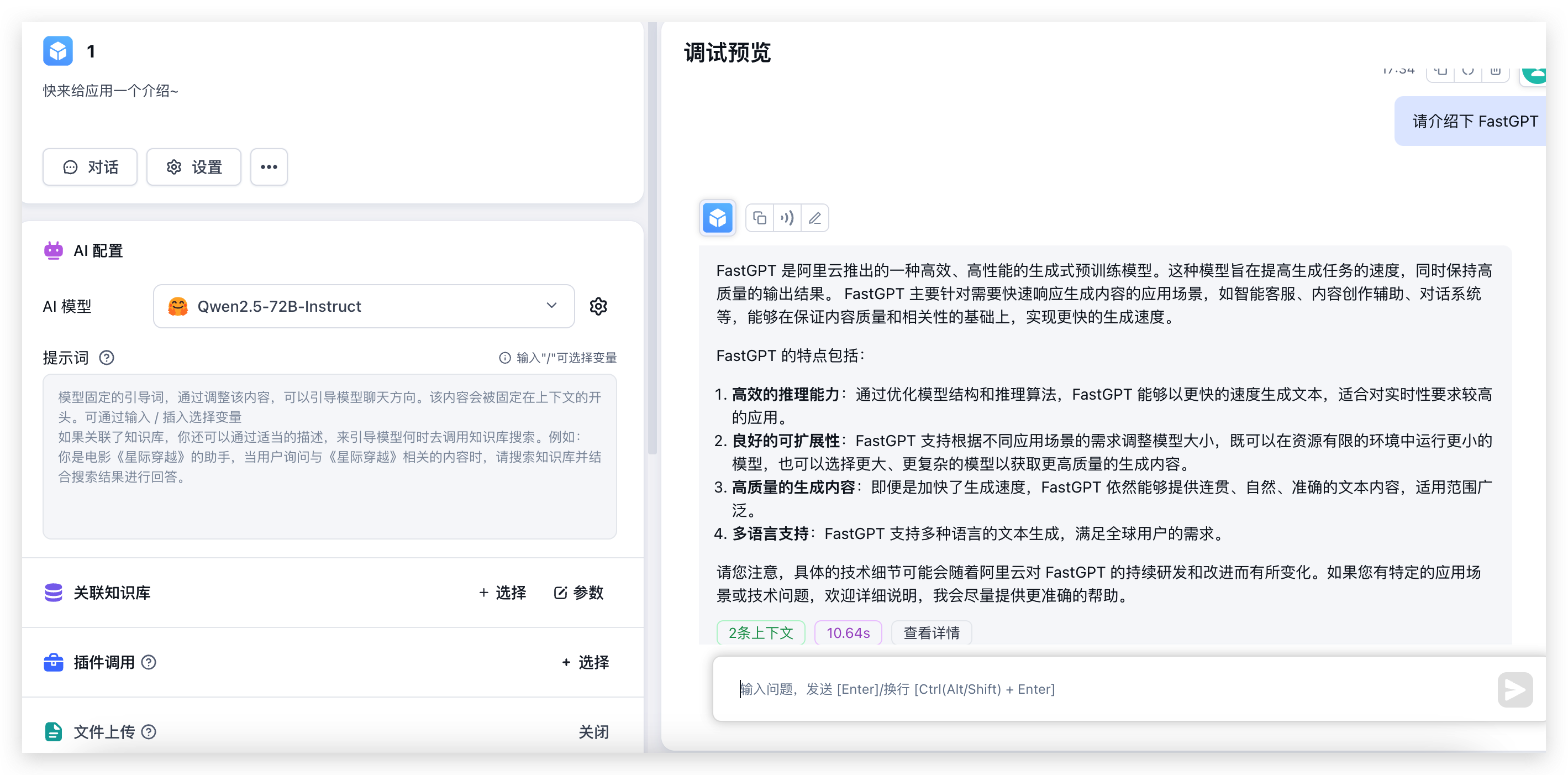 | 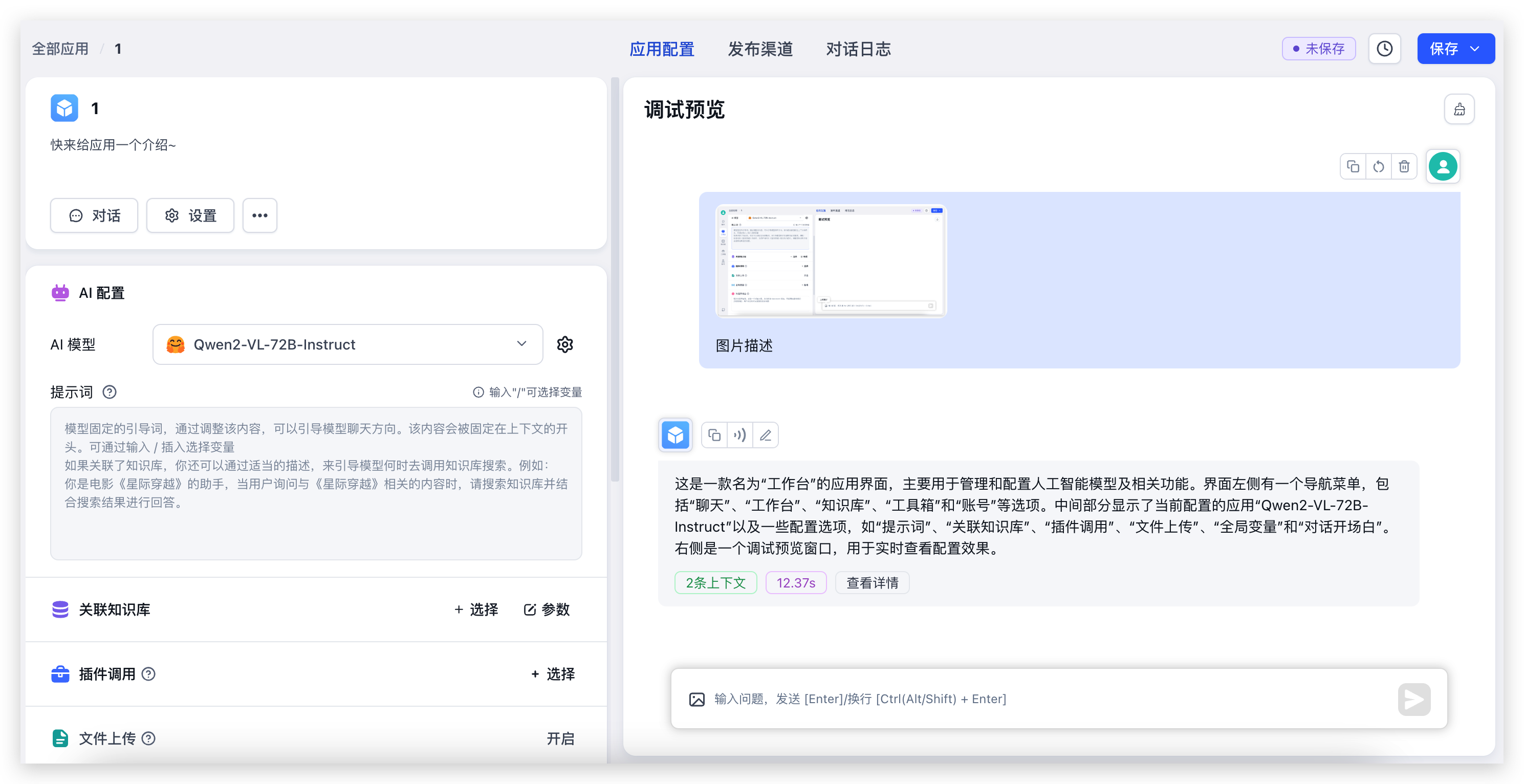 |
可以看到,72B 的模型,性能还是非常快的,这要是本地没几个 4090,不说配置环境,输出怕都要 30s 了。
### 测试知识库导入和知识库问答
新建一个知识库(由于只配置了一个向量模型,页面上不会展示向量模型选择)
| | |
| ------------------------------------------------------------------------------------------- | ------------------------------------------------------------------------------------------- |
| 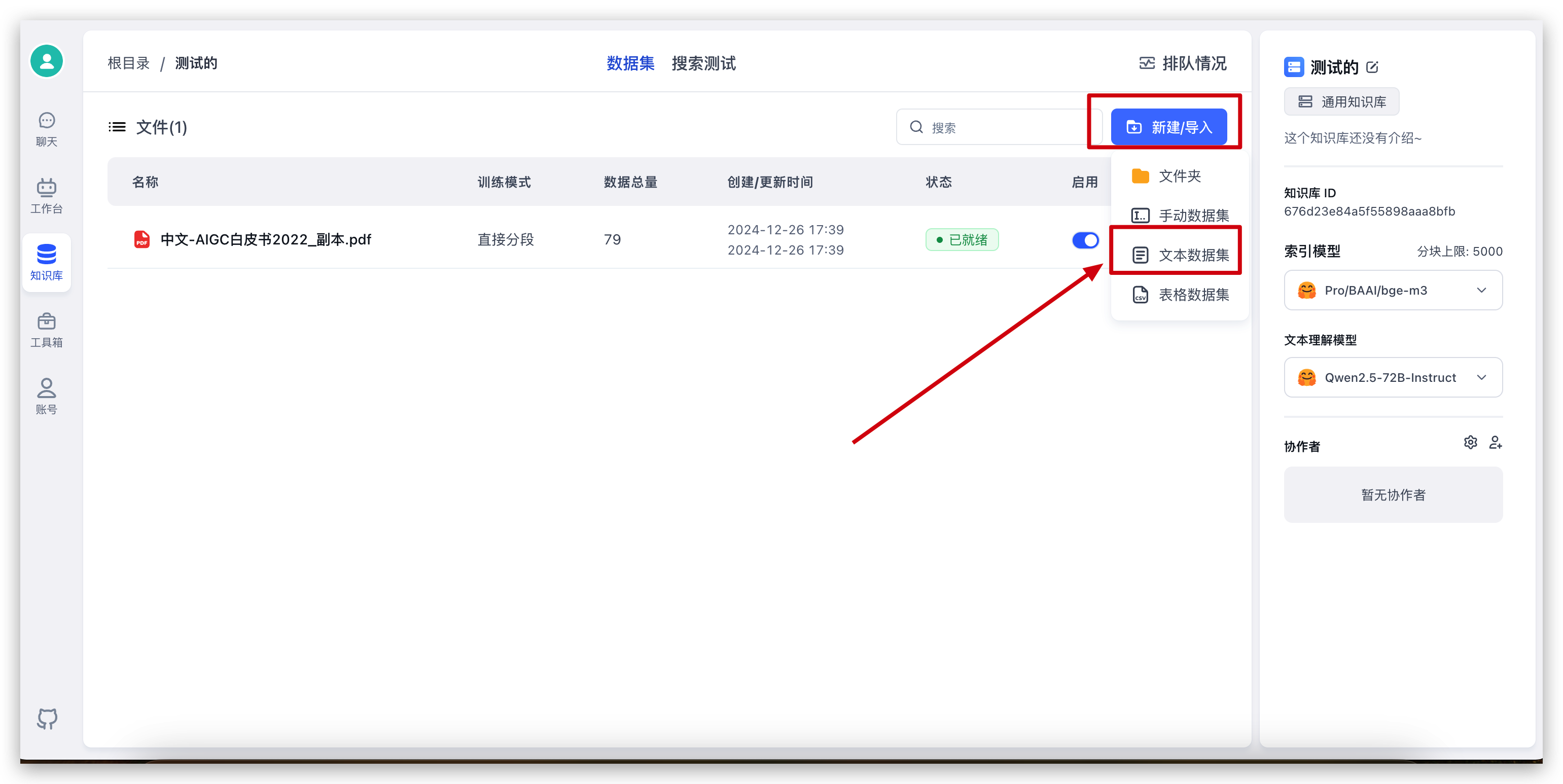 | 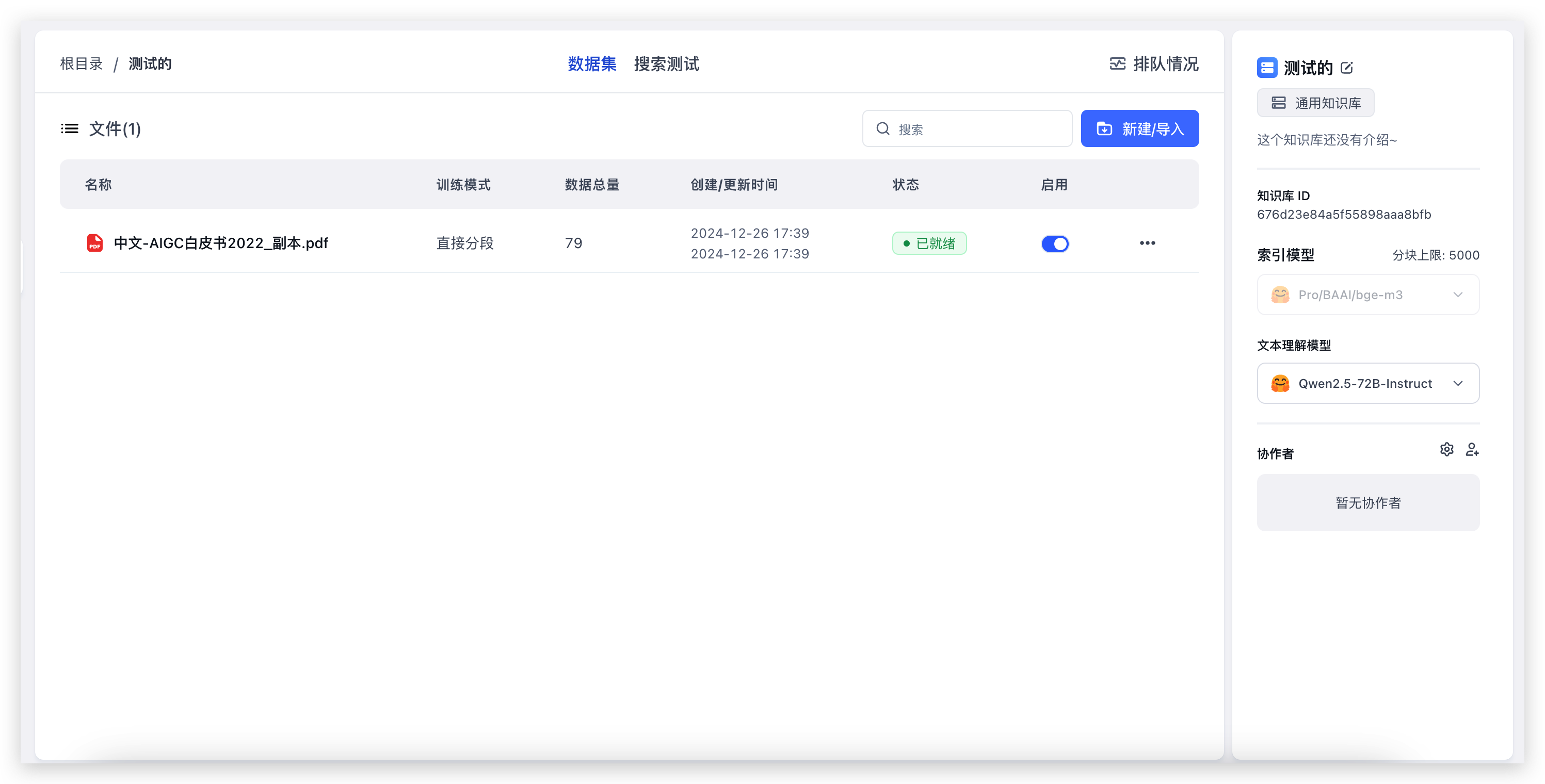 |
导入本地文件,直接选择文件,然后一路下一步即可。79 个索引,大概花了 20s 的时间就完成了。现在我们去测试一下知识库问答。
首先回到我们刚创建的应用,选择知识库,调整一下参数后即可开始对话:
| | | |
| ------------------------------------------------------------------------------------------- | ------------------------------------------------------------------------------------------- | ------------------------------------------------------------------------------------------- |
| 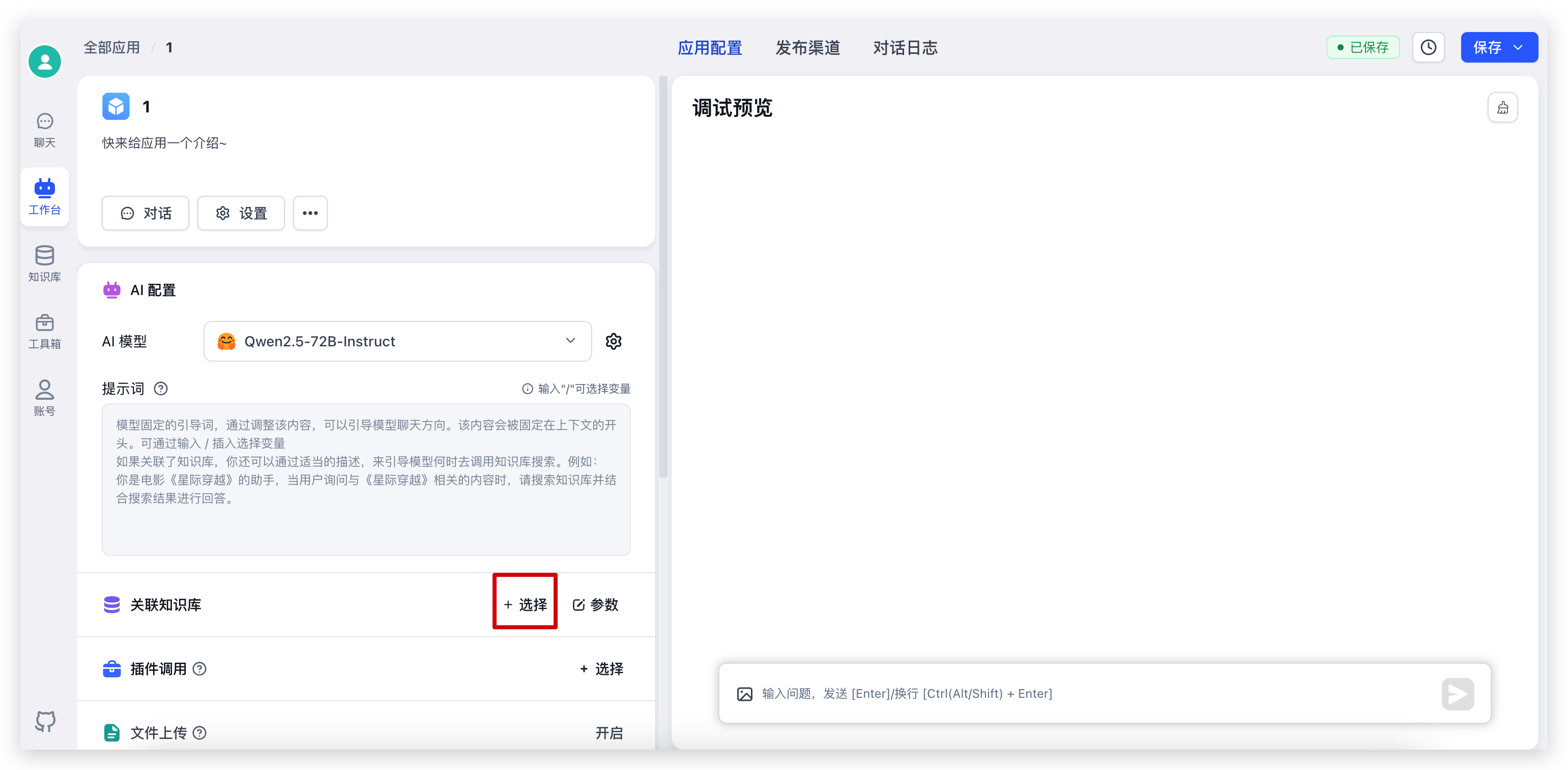 | 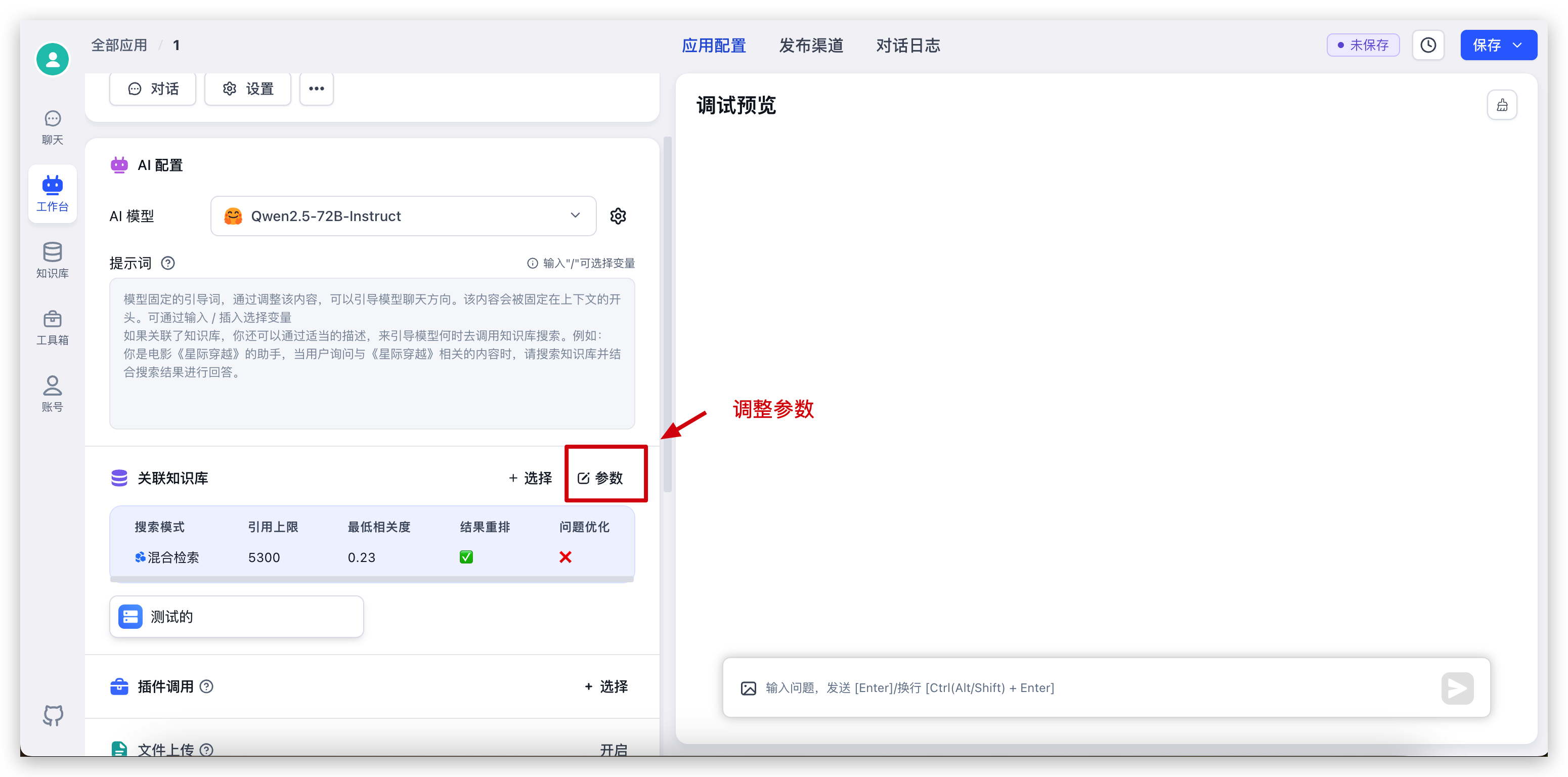 | 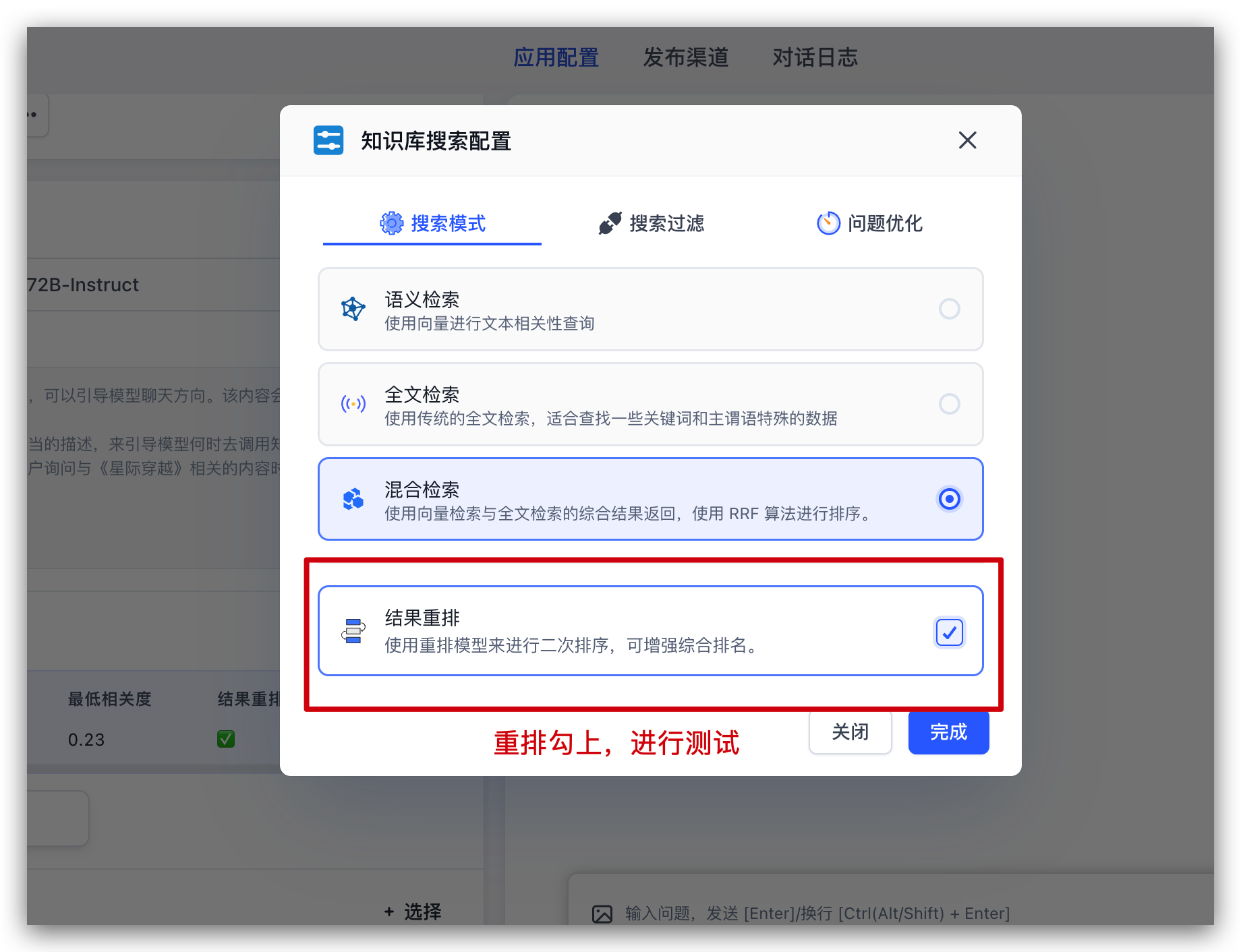 |
对话完成后,点击底部的引用,可以查看引用详情,同时可以看到具体的检索和重排得分:
| | |
| ------------------------------------------------------------------------------------------- | ------------------------------------------------------------------------------------------- |
| 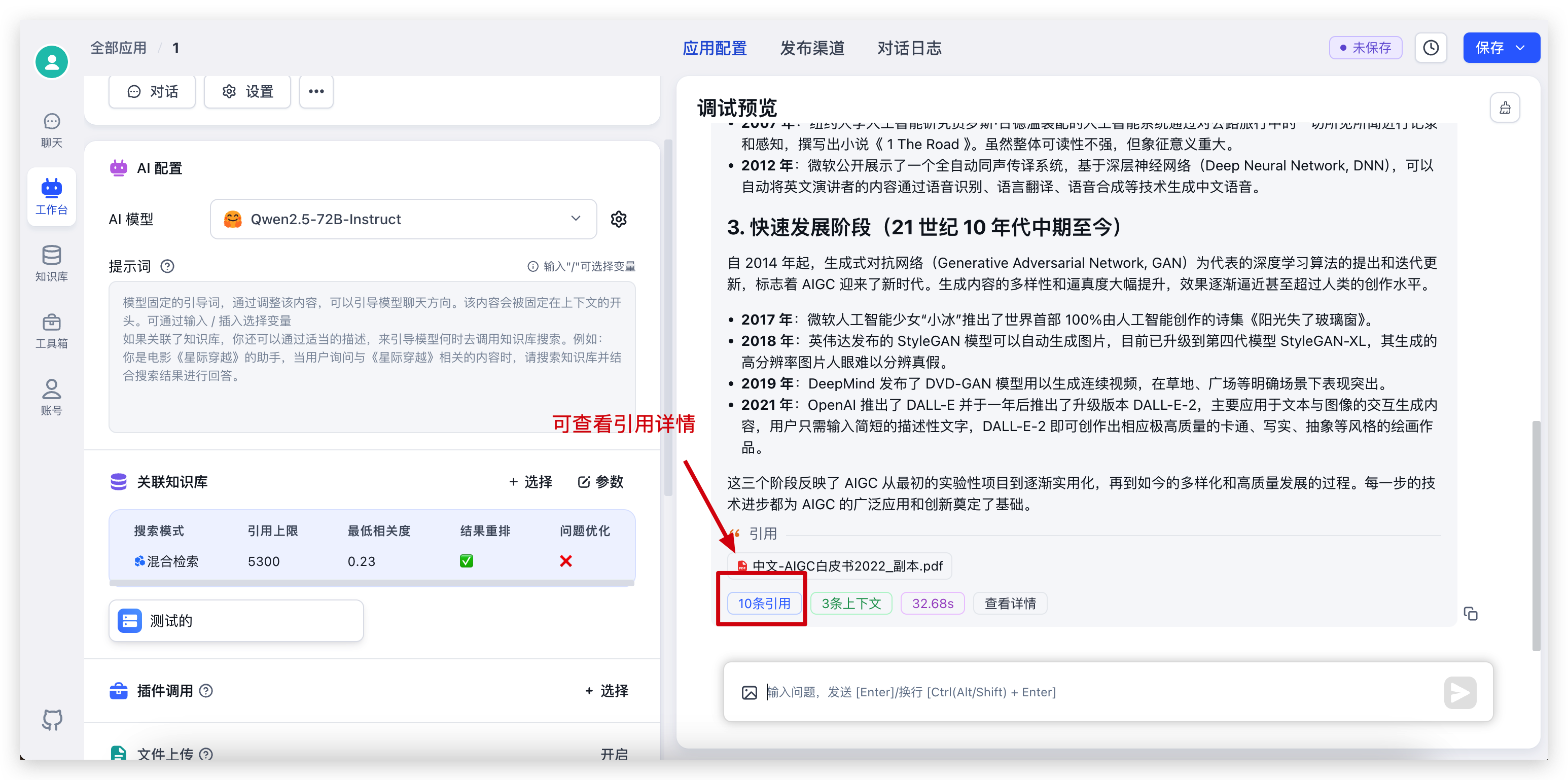 | 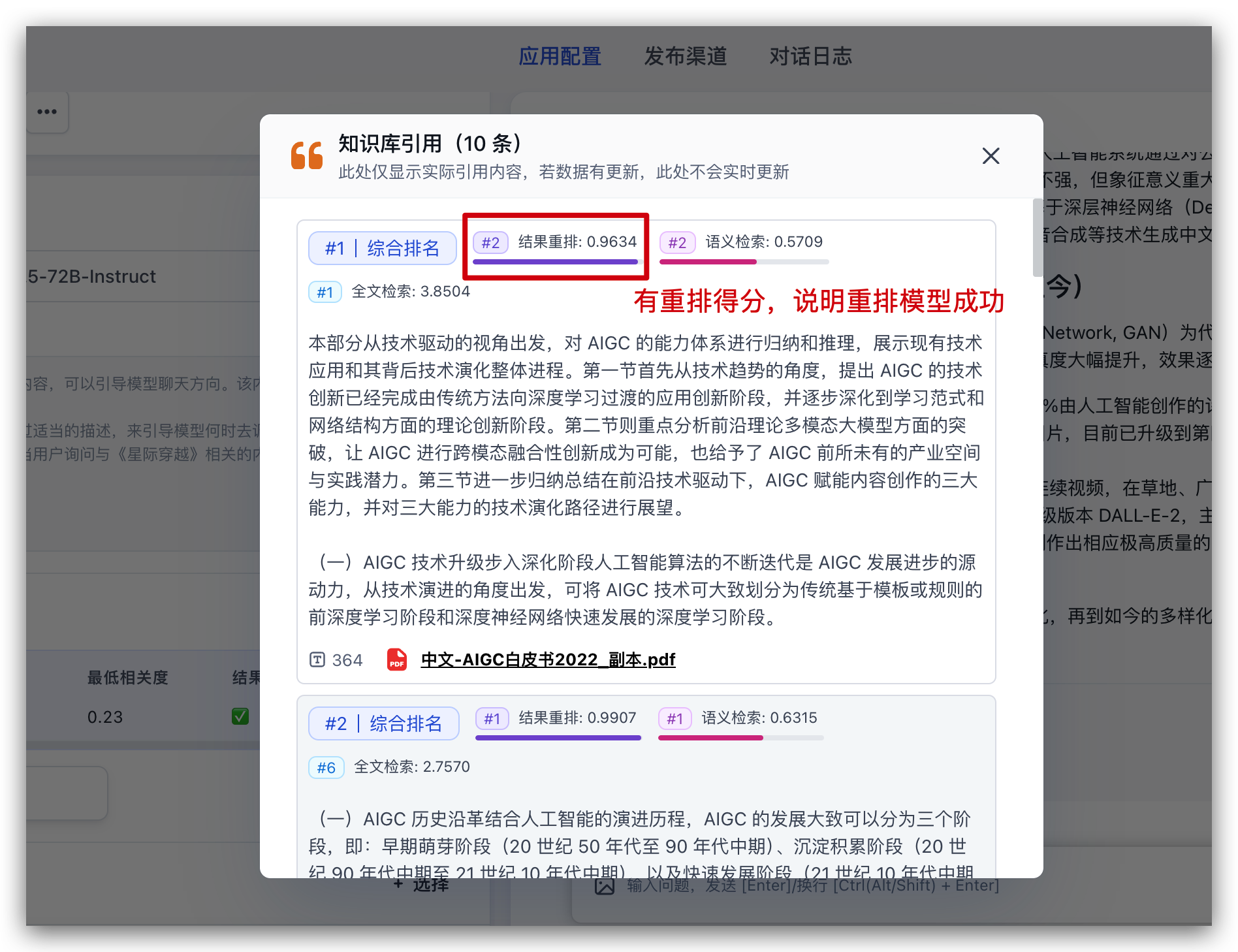 |
### 测试语音播放
继续在刚刚的应用中,左侧配置中找到语音播放,点击后可以从弹窗中选择语音模型,并进行试听:
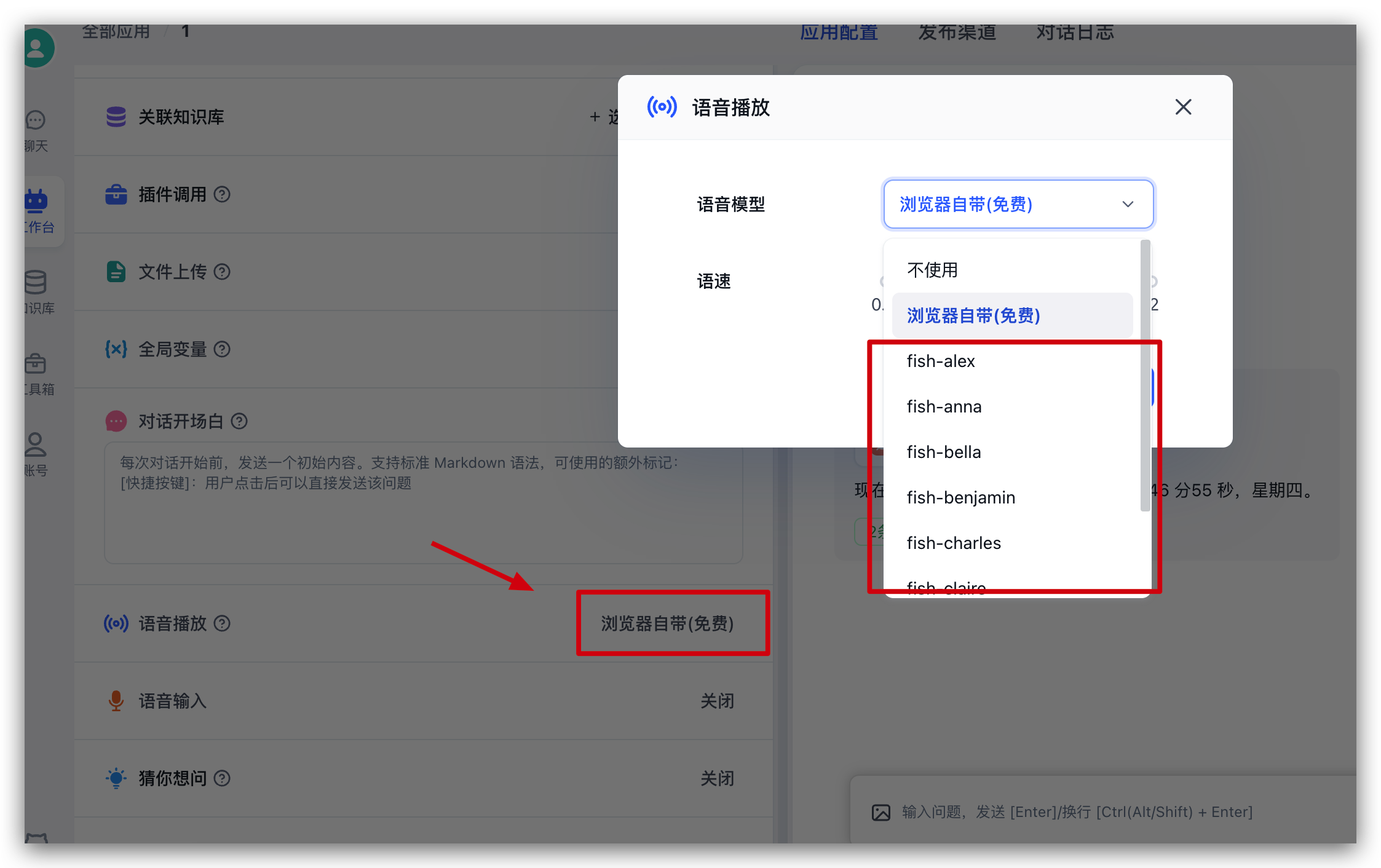
### 测试语言输入
继续在刚刚的应用中,左侧配置中找到语音输入,点击后可以从弹窗中开启语言输入
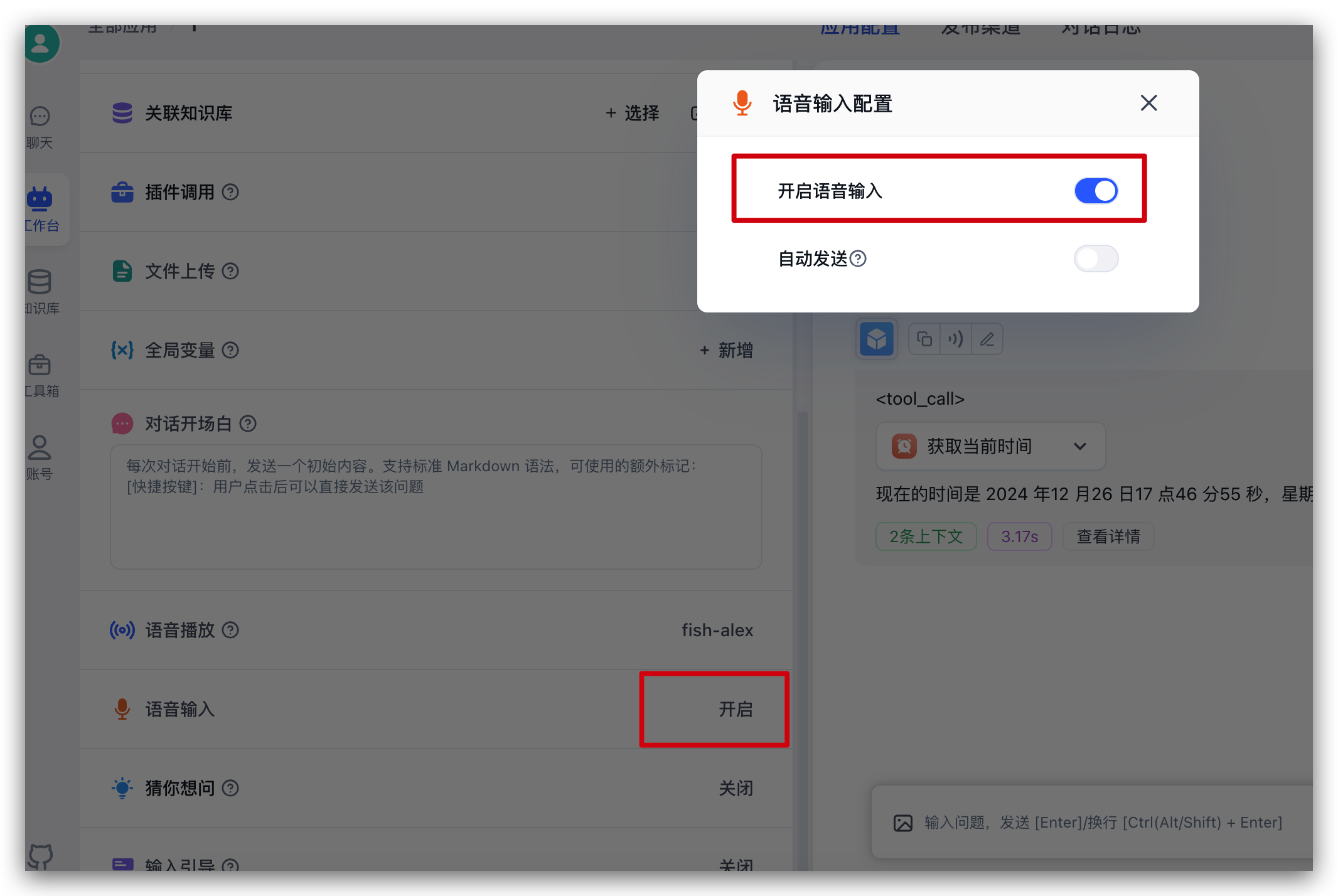
开启后,对话输入框中,会增加一个话筒的图标,点击可进行语音输入:
| | |
| ------------------------------------------------------------------------------------------- | ------------------------------------------------------------------------------------------- |
| 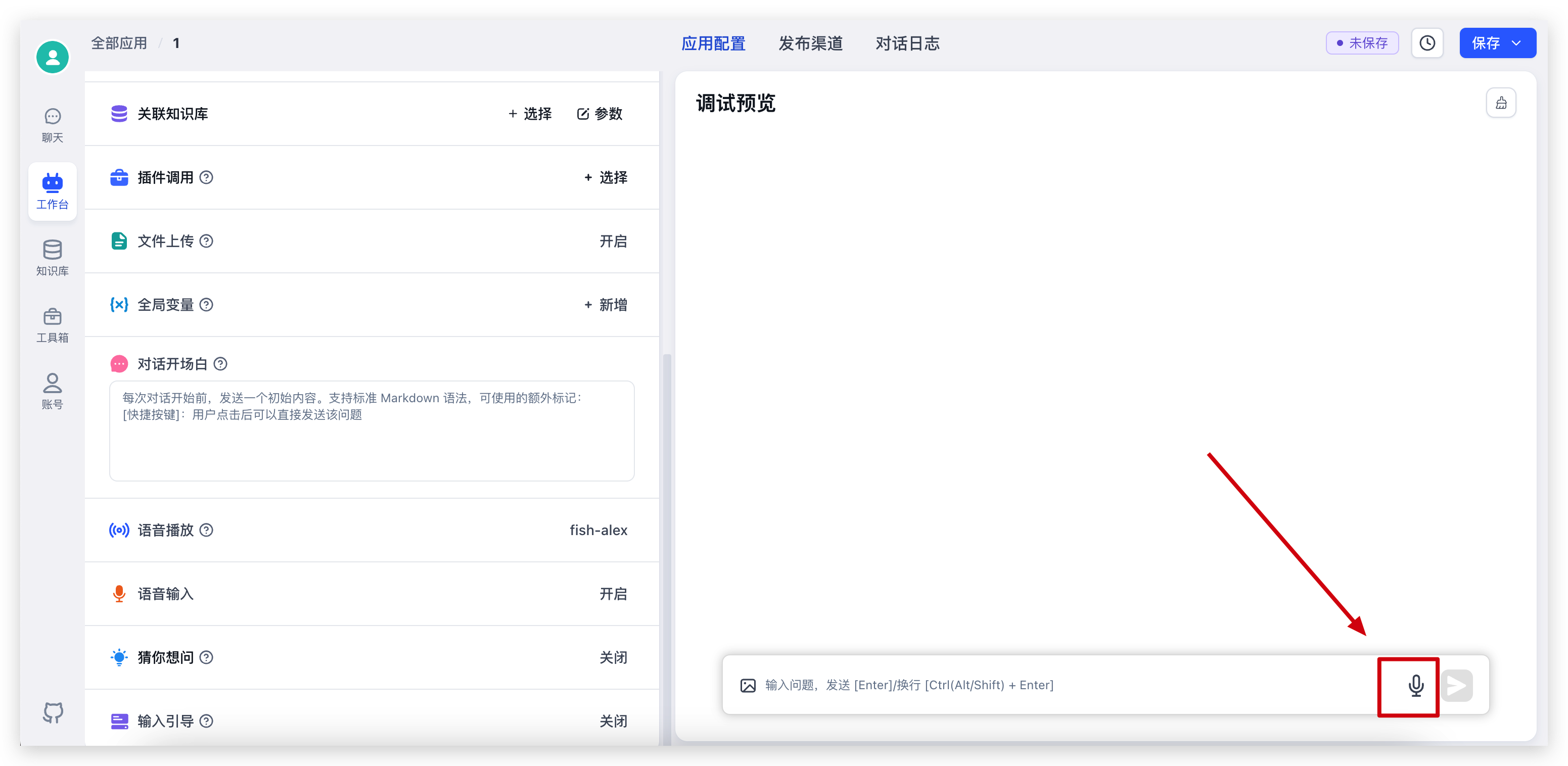 |  |
## 总结
如果你想快速的体验开源模型或者快速的使用 FastGPT,不想在不同服务商申请各类 Api Key,那么可以选择 SiliconCloud 的模型先进行快速体验。
如果你决定未来私有化部署模型和 FastGPT,前期可通过 SiliconCloud 进行测试验证,后期再进行硬件采购,减少 POC 时间和成本。
# 飞书多维表格
Source: https://docs.siliconflow.cn/cn/usercases/use-siliconcloud-in-feishu
飞书多维表格已正式接入硅基流动 SiliconCloud 平台,你可以直接在多维表格的 AI 字段捷径中心调用平台上包括 DeepSeek-R1、QWQ-32B 等热门大模型,搭配多维表格的批量结构化数据处理和业务自动化构建能力,一键完成创作、翻译、分类、总结等操作,享受更快、更准、更聪明的数据管理体验。
## 相关参考
* 💻 [eechat 官网](https://ee.chat)
* 🧑💻 [eechat GitHub](https://github.com/Lucassssss/eechat)
* ☁️ [硅基流动 API 密钥](https://cloud.siliconflow.cn/account/ak)
* 📘 [硅基流动官方文档](https://docs.siliconflow.cn)
如何你觉得 [eechat](https://github.com/Lucassssss/eechat) 不错,欢迎给一个 Star ⭐️ 支持开源项目发展!
# FastGPT
Source: https://docs.siliconflow.cn/cn/usercases/use-siliconcloud-in-fastgpt
本文转载自 [FastGPT](https://fastgpt.run) 的官方文档,介绍了如何在 FastGPT 中使用 SiliconCloud 的模型。[原文地址](https://doc.tryfastgpt.ai/docs/development/modelconfig/siliconcloud/)
[SiliconCloud](https://cloud.siliconflow.cn/i/TR9Ym0c4) 是一个以提供开源模型调用为主的平台,并拥有自己的加速引擎。帮助用户低成本、快速的进行开源模型的测试和使用。实际体验下来,他们家模型的速度和稳定性都非常不错,并且种类丰富,覆盖语言、向量、重排、TTS、STT、绘图、视频生成模型,可以满足 FastGPT 中所有模型需求。
如果你想部分模型使用 SiliconCloud 的模型,可额外参考[OneAPI接入硅基流动](https://doc.tryfastgpt.ai/docs/development/modelconfig/one-api/#%E7%A1%85%E5%9F%BA%E6%B5%81%E5%8A%A8--%E5%BC%80%E6%BA%90%E6%A8%A1%E5%9E%8B%E5%A4%A7%E5%90%88%E9%9B%86)。
本文会介绍完全使用 SiliconCloud 模型来部署 FastGPT 的方案。
## 1. 注册 SiliconCloud 账号
1. [点击注册硅基流动账号](https://cloud.siliconflow.cn/i/TR9Ym0c4)
2. 进入控制台,获取 API key: [https://cloud.siliconflow.cn/account/ak](https://cloud.siliconflow.cn/account/ak)
## 2. 修改 FastGPT 环境变量
```bash
OPENAI_BASE_URL=https://api.siliconflow.cn/v1
# 填写 SiliconCloud 控制台提供的 Api Key
CHAT_API_KEY=sk-xxxxxx
```
## 3. 修改 FastGPT 配置文件
我们选取 SiliconCloud 中的模型作为 FastGPT 配置。这里配置了 `Qwen2.5 72b` 的纯语言和视觉模型;选择 `bge-m3` 作为向量模型;选择 `bge-reranker-v2-m3` 作为重排模型。选择 `fish-speech-1.5` 作为语音模型;选择 `SenseVoiceSmall` 作为语音输入模型。
注意:ReRank 模型仍需配置一次 Api Key
```json
{
"llmModels": [
{
"provider": "Other", // 模型提供商,主要用于分类展示,目前已经内置提供商包括:https://github.com/labring/FastGPT/blob/main/packages/global/core/ai/provider.ts, 可 pr 提供新的提供商,或直接填写 Other
"model": "Qwen/Qwen2.5-72B-Instruct", // 模型名(对应OneAPI中渠道的模型名)
"name": "Qwen2.5-72B-Instruct", // 模型别名
"maxContext": 32000, // 最大上下文
"maxResponse": 4000, // 最大回复
"quoteMaxToken": 30000, // 最大引用内容
"maxTemperature": 1, // 最大温度
"charsPointsPrice": 0, // n积分/1k token(商业版)
"censor": false, // 是否开启敏感校验(商业版)
"vision": false, // 是否支持图片输入
"datasetProcess": true, // 是否设置为文本理解模型(QA),务必保证至少有一个为true,否则知识库会报错
"usedInClassify": true, // 是否用于问题分类(务必保证至少有一个为true)
"usedInExtractFields": true, // 是否用于内容提取(务必保证至少有一个为true)
"usedInToolCall": true, // 是否用于工具调用(务必保证至少有一个为true)
"usedInQueryExtension": true, // 是否用于问题优化(务必保证至少有一个为true)
"toolChoice": true, // 是否支持工具选择(分类,内容提取,工具调用会用到。)
"functionCall": false, // 是否支持函数调用(分类,内容提取,工具调用会用到。会优先使用 toolChoice,如果为false,则使用 functionCall,如果仍为 false,则使用提示词模式)
"customCQPrompt": "", // 自定义文本分类提示词(不支持工具和函数调用的模型
"customExtractPrompt": "", // 自定义内容提取提示词
"defaultSystemChatPrompt": "", // 对话默认携带的系统提示词
"defaultConfig": {}, // 请求API时,挟带一些默认配置(比如 GLM4 的 top_p)
"fieldMap": {} // 字段映射(o1 模型需要把 max_tokens 映射为 max_completion_tokens)
},
{
"provider": "Other",
"model": "Qwen/Qwen2-VL-72B-Instruct",
"name": "Qwen2-VL-72B-Instruct",
"maxContext": 32000,
"maxResponse": 4000,
"quoteMaxToken": 30000,
"maxTemperature": 1,
"charsPointsPrice": 0,
"censor": false,
"vision": true,
"datasetProcess": false,
"usedInClassify": false,
"usedInExtractFields": false,
"usedInToolCall": false,
"usedInQueryExtension": false,
"toolChoice": false,
"functionCall": false,
"customCQPrompt": "",
"customExtractPrompt": "",
"defaultSystemChatPrompt": "",
"defaultConfig": {}
}
],
"vectorModels": [
{
"provider": "Other",
"model": "Pro/BAAI/bge-m3",
"name": "Pro/BAAI/bge-m3",
"charsPointsPrice": 0,
"defaultToken": 512,
"maxToken": 5000,
"weight": 100
}
],
"reRankModels": [
{
"model": "BAAI/bge-reranker-v2-m3", // 这里的model需要对应 siliconflow 的模型名
"name": "BAAI/bge-reranker-v2-m3",
"requestUrl": "https://api.siliconflow.cn/v1/rerank",
"requestAuth": "siliconflow 上申请的 key"
}
],
"audioSpeechModels": [
{
"model": "fishaudio/fish-speech-1.5",
"name": "fish-speech-1.5",
"voices": [
{
"label": "fish-alex",
"value": "fishaudio/fish-speech-1.5:alex",
"bufferId": "fish-alex"
},
{
"label": "fish-anna",
"value": "fishaudio/fish-speech-1.5:anna",
"bufferId": "fish-anna"
},
{
"label": "fish-bella",
"value": "fishaudio/fish-speech-1.5:bella",
"bufferId": "fish-bella"
},
{
"label": "fish-benjamin",
"value": "fishaudio/fish-speech-1.5:benjamin",
"bufferId": "fish-benjamin"
},
{
"label": "fish-charles",
"value": "fishaudio/fish-speech-1.5:charles",
"bufferId": "fish-charles"
},
{
"label": "fish-claire",
"value": "fishaudio/fish-speech-1.5:claire",
"bufferId": "fish-claire"
},
{
"label": "fish-david",
"value": "fishaudio/fish-speech-1.5:david",
"bufferId": "fish-david"
},
{
"label": "fish-diana",
"value": "fishaudio/fish-speech-1.5:diana",
"bufferId": "fish-diana"
}
]
}
],
"whisperModel": {
"model": "FunAudioLLM/SenseVoiceSmall",
"name": "SenseVoiceSmall",
"charsPointsPrice": 0
}
}
```
## 4. 重启 FastGPT
## 5. 体验测试
### 测试对话和图片识别
随便新建一个简易应用,选择对应模型,并开启图片上传后进行测试:
| | |
| ------------------------------------------------------------------------------------------- | ------------------------------------------------------------------------------------------- |
|  |  |
可以看到,72B 的模型,性能还是非常快的,这要是本地没几个 4090,不说配置环境,输出怕都要 30s 了。
### 测试知识库导入和知识库问答
新建一个知识库(由于只配置了一个向量模型,页面上不会展示向量模型选择)
| | |
| ------------------------------------------------------------------------------------------- | ------------------------------------------------------------------------------------------- |
|  |  |
导入本地文件,直接选择文件,然后一路下一步即可。79 个索引,大概花了 20s 的时间就完成了。现在我们去测试一下知识库问答。
首先回到我们刚创建的应用,选择知识库,调整一下参数后即可开始对话:
| | | |
| ------------------------------------------------------------------------------------------- | ------------------------------------------------------------------------------------------- | ------------------------------------------------------------------------------------------- |
|  |  |  |
对话完成后,点击底部的引用,可以查看引用详情,同时可以看到具体的检索和重排得分:
| | |
| ------------------------------------------------------------------------------------------- | ------------------------------------------------------------------------------------------- |
|  |  |
### 测试语音播放
继续在刚刚的应用中,左侧配置中找到语音播放,点击后可以从弹窗中选择语音模型,并进行试听:

### 测试语言输入
继续在刚刚的应用中,左侧配置中找到语音输入,点击后可以从弹窗中开启语言输入

开启后,对话输入框中,会增加一个话筒的图标,点击可进行语音输入:
| | |
| ------------------------------------------------------------------------------------------- | ------------------------------------------------------------------------------------------- |
|  |  |
## 总结
如果你想快速的体验开源模型或者快速的使用 FastGPT,不想在不同服务商申请各类 Api Key,那么可以选择 SiliconCloud 的模型先进行快速体验。
如果你决定未来私有化部署模型和 FastGPT,前期可通过 SiliconCloud 进行测试验证,后期再进行硬件采购,减少 POC 时间和成本。
# 飞书多维表格
Source: https://docs.siliconflow.cn/cn/usercases/use-siliconcloud-in-feishu
飞书多维表格已正式接入硅基流动 SiliconCloud 平台,你可以直接在多维表格的 AI 字段捷径中心调用平台上包括 DeepSeek-R1、QWQ-32B 等热门大模型,搭配多维表格的批量结构化数据处理和业务自动化构建能力,一键完成创作、翻译、分类、总结等操作,享受更快、更准、更聪明的数据管理体验。
 ## 使用方法
### 1. 进入飞书,点击 “多维表格”,“新建多维表格”。
## 使用方法
### 1. 进入飞书,点击 “多维表格”,“新建多维表格”。
 ### 2. 创建 DeepSeek-R1 AI 字段捷径
* 在左侧的导航栏中打开需要使用的数据表,创建文本字段,输入任务关键词(如"自媒体文案主题"),该字段将作为后续 AI 任务指令的引用字段。
### 2. 创建 DeepSeek-R1 AI 字段捷径
* 在左侧的导航栏中打开需要使用的数据表,创建文本字段,输入任务关键词(如"自媒体文案主题"),该字段将作为后续 AI 任务指令的引用字段。
 * 点击字段名右侧的“+”或搜索字段。点击悬停字段类型的 “探索字段捷径” ,搜索“硅基流动”并选择 “AI 大模型(硅基流动)”。
* 点击字段名右侧的“+”或搜索字段。点击悬停字段类型的 “探索字段捷径” ,搜索“硅基流动”并选择 “AI 大模型(硅基流动)”。

 * 点击“关联账号”按钮,跳转 硅基流动 SiliconCloud 平台以获取 API 密钥,复制 API 密钥,返回当前页面,将 API 密钥粘贴至指定输入框内。
* 点击“关联账号”按钮,跳转 硅基流动 SiliconCloud 平台以获取 API 密钥,复制 API 密钥,返回当前页面,将 API 密钥粘贴至指定输入框内。
 硅基流动 SiliconCloud 默认提供 Qwen/QwQ-32B、Pro/deepseek-ai/DeepSeek-R1、THUDM/GLM-Z1-32B-0414 和 DeepSeek-R1-Distill-Qwen-32B 四款 AI 模型,用户可以按需选择。
* 在"输入指令"栏中直接输入文字指令,点击右上角 ”+引用字段” 添加数据表字段,系统自动将输入文字与引用字段拼接为完整指令。
硅基流动 SiliconCloud 默认提供 Qwen/QwQ-32B、Pro/deepseek-ai/DeepSeek-R1、THUDM/GLM-Z1-32B-0414 和 DeepSeek-R1-Distill-Qwen-32B 四款 AI 模型,用户可以按需选择。
* 在"输入指令"栏中直接输入文字指令,点击右上角 ”+引用字段” 添加数据表字段,系统自动将输入文字与引用字段拼接为完整指令。
 * 点击“确认”并生成内容,查看字段名右上角百分比可得知任务处理进度,任务完成后图标自动消失。
* 点击“确认”并生成内容,查看字段名右上角百分比可得知任务处理进度,任务完成后图标自动消失。
 * 鼠标光标悬停在字段列的任意单元格,点击“查看”,上下滑动即可浏览模型生成的完整内容,包括模型执行任务时的思考过程和输出结果。
* 鼠标光标悬停在字段列的任意单元格,点击“查看”,上下滑动即可浏览模型生成的完整内容,包括模型执行任务时的思考过程和输出结果。

 * 你也可以双击单元格查阅对应的生成内容。
* 你也可以双击单元格查阅对应的生成内容。
 注:“硅基流动”字段捷径开箱即用,尝鲜用户会有部分免费配额,超过上限后,用户可自助绑定硅基流动 SiliconCloud 账号继续使用模型。
## 错误码信息
| **错误码** | **原因** | **解决方案** |
| --------- | ------------------------------------------ | --------------------------------------- |
| 800004780 | 密钥填写错误 | 确认密钥正确填写 |
| 800004781 | 当前捷径有大量任务处理中,请稍后重 | 可能遇到高峰期,稍后重试 |
| 800004782 | 1. 飞书赠送额度已用完;2. 需要绑定个人硅基流动账户使用额度 | 硅基流动绑定自己的 api key, |
| 800004783 | 高峰期排队导致服务超时 | 等待一段时间后刷新,不要频繁刷新 |
| 800004788 | 高峰期排队导致服务超时 | 等待一段时间后刷新,不要频繁刷新 |
| 800004789 | 1. 飞书赠送额度已用完;2. 需要绑定个人硅基流动账户使用额度;3. 密钥填写错误 | 请对照以下几个方案依次排查:1. 查看硅基流动账户余额;2. 确认密钥正确填写 |
## 联系开发者
点击此处的“联系开发者”进入话题群,也可以通过直接扫描下面官方群二维码进入。
注:“硅基流动”字段捷径开箱即用,尝鲜用户会有部分免费配额,超过上限后,用户可自助绑定硅基流动 SiliconCloud 账号继续使用模型。
## 错误码信息
| **错误码** | **原因** | **解决方案** |
| --------- | ------------------------------------------ | --------------------------------------- |
| 800004780 | 密钥填写错误 | 确认密钥正确填写 |
| 800004781 | 当前捷径有大量任务处理中,请稍后重 | 可能遇到高峰期,稍后重试 |
| 800004782 | 1. 飞书赠送额度已用完;2. 需要绑定个人硅基流动账户使用额度 | 硅基流动绑定自己的 api key, |
| 800004783 | 高峰期排队导致服务超时 | 等待一段时间后刷新,不要频繁刷新 |
| 800004788 | 高峰期排队导致服务超时 | 等待一段时间后刷新,不要频繁刷新 |
| 800004789 | 1. 飞书赠送额度已用完;2. 需要绑定个人硅基流动账户使用额度;3. 密钥填写错误 | 请对照以下几个方案依次排查:1. 查看硅基流动账户余额;2. 确认密钥正确填写 |
## 联系开发者
点击此处的“联系开发者”进入话题群,也可以通过直接扫描下面官方群二维码进入。
 ### 官方群
### 官方群
 # 沉浸式翻译
Source: https://docs.siliconflow.cn/cn/usercases/use-siliconcloud-in-immersive-translate
在沉浸式翻译中,调用 SiliconCloud 的 API,实现快速跨语言翻译的目标
作为全网口碑炸裂的双语对照网页翻译插件,[沉浸式翻译](https://immersivetranslate.com/)使用大语言模型,具备跨语种理解能力,能够实时翻译外语内容,可应用于网页阅读、 PDF 翻译、 EPUB 电子书翻译、视频双语字幕翻译等场景,并支持各种浏览器插件和应用使用。自 2023 年上线以来,这款备受赞誉的 AI 双语对照网页翻译插件,已帮助超过 100 万用户跨越语言障碍,汲取全球智慧。
硅基流动的 SiliconCloud 第一时间提供 GLM4 、 Qwen2 、 DeepSeek V2 、零一万物等大模型,将三方大模型和沉浸式翻译插件相结合,极大改善翻译时的速度和准确度。
## 1. 获取 API Key
1. 打开 SiliconCloud [官网](https://cloud.siliconflow.cn/) 并注册账号(如果注册过,直接登录即可)。
2. 完成注册后,打开[API密钥](https://cloud.siliconflow.cn/account/ak) ,创建新的 API Key,点击密钥进行复制,以备后续使用。
## 2. 在沉浸式翻译中使用 SiliconCloud
### 2.1 默认配置
1. 在“沉浸式翻译”[官网](https://immersivetranslate.com/zh-Hans/)选择“安装浏览器插件”,选择合适的浏览器版本,根据提示进行安装。如您已安装对应插件,请跳过本步骤。
2. 点击沉浸式翻译拓展,点击设置,出现弹窗,将弹窗中的“翻译服务”设置为“ SiliconCloud 翻译”
3. 设置成功后即可开始使用 SiliconCloud 翻译服务。
### 2.2 使用 SiliconCloud 的其他免费模型:
1. 设置的默认模型是 SiliconCloud 的“ Qwen/Qwen2-7B-Instruct ”,如果需要切换成 SiliconCloud 的其他模型,请点击图标中的“设置”,打开设置界面。
2. 在“基本设置”中选择其他模型,即可使用 SiliconCloud 的其他免费模型。
### 2.3 使用 SiliconCloud 的其他文本生成模型:
1. 如需使用 SiliconCloud 其他模型,点击沉浸式翻译的扩展图标,找到“设置”按钮并点击,选择“更多翻译服务”。
2. 代开设置页后点击“翻译服务”,划到底部,点击`添加兼容 Open AI 接口的自定义 AI 翻译服务?`。
3.根据要求添加 SiliconCloud 模型的相关信息
* **自定义翻译服务名称:** 按照自己的实际情况填写即可。
* **自定义 API 接口地址:** [https://api.siliconflow.cn/v1/chat/completions](https://api.siliconflow.cn/v1/chat/completions)
* **API Key:** 将 SiliconCloud 平台的密钥粘贴到此处。
* **模型名称:** 模型在 SiliconCloud 中的名称
3. 完成配置后,点击右上角的测试,进行验证。
4. 配置成功后即可开始使用其他文本生成大模型。
# 微服务编排框架 Juggle
Source: https://docs.siliconflow.cn/cn/usercases/use-siliconcloud-in-juggle
## 1. 关于 Juggle
[Juggle](https://juggle.plus) 是一个零码 + 低码 + AI 的微服务编排 & 系统集成的强大编排工具平台,致力于为用户提供微服务接口编排、第三方系统对接、标准产品私有化定制、数据清洗等痛点的解决方案。支持 Http , Dubbo , WebService 等协议的接口编排,支持通过 Groovy , JavaScript , Python , Java 等多种脚本语言来增强流程,支持使用 MySQL,达梦等几十种常见数据源。赋能企业业务系统,实现合作共赢。
**项目特点:**
* 全零码化搭建流程,上手容易
* 全私有化部署,数据安全有保障
* 极致性能追求,高并发无压力
项目开源地址:[GitHub](https://github.com/somta/Juggle)
## 2. 使用 Juggle
前往 [Juggle 官网](https://juggle.plus)下载最新 Juggle 版本,参考 [Juggle 安装手册](https://juggle.plus/docs/guide/start/quick-start/)进行安装使用。
## 3. 在 Juggle 中使用 SiliconCloud
### a. 获取 API Key
打开 SiliconCloud [官网](https://cloud.siliconflow.cn/) 并注册账号(如果注册过,直接登录即可),完成注册后,打开 [API 密钥](https://cloud.siliconflow.cn/account/ak),创建新的 API Key,点击密钥进行复制,以备后续使用。
### b. 安装硅基流动套件
进入 Juggle 套件市场,在套件市场中搜索**硅基流动**,安装硅基流动套件,后续就能在流程中使用硅基流动提供的接口了。
# 沉浸式翻译
Source: https://docs.siliconflow.cn/cn/usercases/use-siliconcloud-in-immersive-translate
在沉浸式翻译中,调用 SiliconCloud 的 API,实现快速跨语言翻译的目标
作为全网口碑炸裂的双语对照网页翻译插件,[沉浸式翻译](https://immersivetranslate.com/)使用大语言模型,具备跨语种理解能力,能够实时翻译外语内容,可应用于网页阅读、 PDF 翻译、 EPUB 电子书翻译、视频双语字幕翻译等场景,并支持各种浏览器插件和应用使用。自 2023 年上线以来,这款备受赞誉的 AI 双语对照网页翻译插件,已帮助超过 100 万用户跨越语言障碍,汲取全球智慧。
硅基流动的 SiliconCloud 第一时间提供 GLM4 、 Qwen2 、 DeepSeek V2 、零一万物等大模型,将三方大模型和沉浸式翻译插件相结合,极大改善翻译时的速度和准确度。
## 1. 获取 API Key
1. 打开 SiliconCloud [官网](https://cloud.siliconflow.cn/) 并注册账号(如果注册过,直接登录即可)。
2. 完成注册后,打开[API密钥](https://cloud.siliconflow.cn/account/ak) ,创建新的 API Key,点击密钥进行复制,以备后续使用。
## 2. 在沉浸式翻译中使用 SiliconCloud
### 2.1 默认配置
1. 在“沉浸式翻译”[官网](https://immersivetranslate.com/zh-Hans/)选择“安装浏览器插件”,选择合适的浏览器版本,根据提示进行安装。如您已安装对应插件,请跳过本步骤。
2. 点击沉浸式翻译拓展,点击设置,出现弹窗,将弹窗中的“翻译服务”设置为“ SiliconCloud 翻译”
3. 设置成功后即可开始使用 SiliconCloud 翻译服务。
### 2.2 使用 SiliconCloud 的其他免费模型:
1. 设置的默认模型是 SiliconCloud 的“ Qwen/Qwen2-7B-Instruct ”,如果需要切换成 SiliconCloud 的其他模型,请点击图标中的“设置”,打开设置界面。
2. 在“基本设置”中选择其他模型,即可使用 SiliconCloud 的其他免费模型。
### 2.3 使用 SiliconCloud 的其他文本生成模型:
1. 如需使用 SiliconCloud 其他模型,点击沉浸式翻译的扩展图标,找到“设置”按钮并点击,选择“更多翻译服务”。
2. 代开设置页后点击“翻译服务”,划到底部,点击`添加兼容 Open AI 接口的自定义 AI 翻译服务?`。
3.根据要求添加 SiliconCloud 模型的相关信息
* **自定义翻译服务名称:** 按照自己的实际情况填写即可。
* **自定义 API 接口地址:** [https://api.siliconflow.cn/v1/chat/completions](https://api.siliconflow.cn/v1/chat/completions)
* **API Key:** 将 SiliconCloud 平台的密钥粘贴到此处。
* **模型名称:** 模型在 SiliconCloud 中的名称
3. 完成配置后,点击右上角的测试,进行验证。
4. 配置成功后即可开始使用其他文本生成大模型。
# 微服务编排框架 Juggle
Source: https://docs.siliconflow.cn/cn/usercases/use-siliconcloud-in-juggle
## 1. 关于 Juggle
[Juggle](https://juggle.plus) 是一个零码 + 低码 + AI 的微服务编排 & 系统集成的强大编排工具平台,致力于为用户提供微服务接口编排、第三方系统对接、标准产品私有化定制、数据清洗等痛点的解决方案。支持 Http , Dubbo , WebService 等协议的接口编排,支持通过 Groovy , JavaScript , Python , Java 等多种脚本语言来增强流程,支持使用 MySQL,达梦等几十种常见数据源。赋能企业业务系统,实现合作共赢。
**项目特点:**
* 全零码化搭建流程,上手容易
* 全私有化部署,数据安全有保障
* 极致性能追求,高并发无压力
项目开源地址:[GitHub](https://github.com/somta/Juggle)
## 2. 使用 Juggle
前往 [Juggle 官网](https://juggle.plus)下载最新 Juggle 版本,参考 [Juggle 安装手册](https://juggle.plus/docs/guide/start/quick-start/)进行安装使用。
## 3. 在 Juggle 中使用 SiliconCloud
### a. 获取 API Key
打开 SiliconCloud [官网](https://cloud.siliconflow.cn/) 并注册账号(如果注册过,直接登录即可),完成注册后,打开 [API 密钥](https://cloud.siliconflow.cn/account/ak),创建新的 API Key,点击密钥进行复制,以备后续使用。
### b. 安装硅基流动套件
进入 Juggle 套件市场,在套件市场中搜索**硅基流动**,安装硅基流动套件,后续就能在流程中使用硅基流动提供的接口了。
 ### c. 使用硅基流动接口
在流程中新建一个**方法节点**,在方法节点的设置中选择**硅基流动套件**,就可以选择硅基流动提供的文本对话,生成图片,生成视频等各种接口了,基于这些接口能力,用户可以编排出各种场景的流程,来满足用户的不同场景的需求。
### c. 使用硅基流动接口
在流程中新建一个**方法节点**,在方法节点的设置中选择**硅基流动套件**,就可以选择硅基流动提供的文本对话,生成图片,生成视频等各种接口了,基于这些接口能力,用户可以编排出各种场景的流程,来满足用户的不同场景的需求。
 # minbricks 智能小说编辑器
Source: https://docs.siliconflow.cn/cn/usercases/use-siliconcloud-in-minbricks
## 1. 关于 mindbricks
mindbricks 是一款 macOS 平台与 Windows 平台皆可使用的智能小说编辑器,您可以将它下载到您的电脑上进行使用,感受 mindbrikcs 带来的写作新体验!
本文将介绍如何借助 SiliconCloud 提供的 API 服务在 mindbricks 中进行小说创作。
## 2. 安装 mindbricks
前往 [mindbricks 官网](https://mindbricks.cn) 安装, 选择合适的系统版本下载.
## 3. 在 mindbricks 中使用 SiliconCloud
### 3.1 默认配置
安装完 mindbricks 之后,鼠标左键点击右下角的 \[齿轮] 图标,选择 \[模型设置] 。
# minbricks 智能小说编辑器
Source: https://docs.siliconflow.cn/cn/usercases/use-siliconcloud-in-minbricks
## 1. 关于 mindbricks
mindbricks 是一款 macOS 平台与 Windows 平台皆可使用的智能小说编辑器,您可以将它下载到您的电脑上进行使用,感受 mindbrikcs 带来的写作新体验!
本文将介绍如何借助 SiliconCloud 提供的 API 服务在 mindbricks 中进行小说创作。
## 2. 安装 mindbricks
前往 [mindbricks 官网](https://mindbricks.cn) 安装, 选择合适的系统版本下载.
## 3. 在 mindbricks 中使用 SiliconCloud
### 3.1 默认配置
安装完 mindbricks 之后,鼠标左键点击右下角的 \[齿轮] 图标,选择 \[模型设置] 。
 在 \[模型] 中选择 「硅基流动(免费)」,鼠标左键点击保存。
在 \[模型] 中选择 「硅基流动(免费)」,鼠标左键点击保存。
 在主界面左键点击\[开始创作],输入作品名称及作品位置即可创建新作品。
在主界面左键点击\[开始创作],输入作品名称及作品位置即可创建新作品。

 **注: 免费模型使用的模型是 Qwen3-8B,如需使用 SiliconCloud 的其他模型,需要自行获取 SiliconCloud API Key**
## 3.2 使用 SiliconCloud 的其他文本生成模型
打开 [SiliconCloud 官网](https://cloud.siliconflow.cn/) 并注册账号(如果注册过,直接登录即可)。
完成注册后,打开 [API 密钥](https://cloud.siliconflow.cn/account/ak) ,创建新的 API Key,点击密钥进行复制,以备后续使用。
进入之前提到的 mindbricks \[模型设置] 页面,点击 \[模型],选择 \[硅基流动] 将API Key 填入硅基流动服务的 API Key 设置项中,点击保存即可使用。
**注: 免费模型使用的模型是 Qwen3-8B,如需使用 SiliconCloud 的其他模型,需要自行获取 SiliconCloud API Key**
## 3.2 使用 SiliconCloud 的其他文本生成模型
打开 [SiliconCloud 官网](https://cloud.siliconflow.cn/) 并注册账号(如果注册过,直接登录即可)。
完成注册后,打开 [API 密钥](https://cloud.siliconflow.cn/account/ak) ,创建新的 API Key,点击密钥进行复制,以备后续使用。
进入之前提到的 mindbricks \[模型设置] 页面,点击 \[模型],选择 \[硅基流动] 将API Key 填入硅基流动服务的 API Key 设置项中,点击保存即可使用。

 **注:MindBricks 已针对不同应用场景内置了不同模型,主要分为以下几类:**
* 对话模型: 在硅基流动服务商下默认为 Qwen/Qwen3-235B-A22B
* 角色模型: 在硅基流动服务商下默认为 Qwen/Qwen3-235B-A22B
* 推理模型: 在硅基流动服务商下默认为 deepseek-ai/DeepSeek-R1
若需要自定义完全自定义模型, 可使用自定义配置。
# MindSearch
Source: https://docs.siliconflow.cn/cn/usercases/use-siliconcloud-in-mindsearch
## 1. 获取 API Key
1. 打开 SiliconCloud [官网](https://cloud.siliconflow.cn/) 并注册账号(如果注册过,直接登录即可)。
2. 完成注册后,打开[API密钥](https://cloud.siliconflow.cn/account/ak) ,创建新的 API Key,点击密钥进行复制,以备后续使用。
## 2. 部署MindSearch
1. 复制 MindSearch 到本地并安装相关依赖后(参考 [https://github.com/InternLM/MindSearch/blob/main/README.md)](https://github.com/InternLM/MindSearch/blob/main/README.md)) ,
2. 修改:
`/path/to/MindSearch/mindsearch/models.py`
3. 加上调用硅基流动 API 的相关配置。配置如下:
```
internlm_silicon = dict(type=GPTAPI,
model_type='internlm/internlm2_5-7b-chat',
key=os.environ.get('SILICON_API_KEY', 'YOUR SILICON API KEY'),
openai_api_base='https://api.siliconflow.cn/v1/chat/completions',
meta_template=[
dict(role='system', api_role='system'),
dict(role='user', api_role='user'),
dict(role='assistant', api_role='assistant'),
dict(role='environment', api_role='system')
],
top_p=0.8,
top_k=1,
temperature=0,
max_new_tokens=8192,
repetition_penalty=1.02,
stop_words=['<|im_end|>'])
```
加入这段配置后,可以执行相关指令来启动 MindSearch。
4. 启动后端:
```
# 指定硅基流动的 API Key
export SILICON_API_KEY=上面流程中复制的密钥
# 启动
python -m mindsearch.app --lang en --model_format internlm_silicon --search_engine DuckDuckGoSearch
```
5. 启动前端。这里以gradio前端为例,其他前端启动可以参考MindSearch的README:
`python frontend/mindsearch_gradio.py`
## 3. 上传到 HuggingFace Space
我们也可以选择部署到 HuggingFace 的 Space 当中。
1. 在 [https://huggingface.co/new-space](https://huggingface.co/new-space) 创建一个新的Space,
配置为:
Gradio
Template:Blank
Hardware:CPU basic·2 vCPU·16GB·FREE
2. 创建成功后,进入" Settings "设置 API Key。
3. 把第二步中的 MindSearch 目录、requirements.txt 和一个 app.py 一并上传。
app.py 详细内容请参考:[https://huggingface.co/spaces/SmartFlowAI/MindSearch\_X\_SiliconFlow/blob/main/app.py](https://huggingface.co/spaces/SmartFlowAI/MindSearch_X_SiliconFlow/blob/main/app.py)
# NextChat
Source: https://docs.siliconflow.cn/cn/usercases/use-siliconcloud-in-nextchat
## 1. 获取 API Key
1. 打开 SiliconCloud [官网](https://cloud.siliconflow.cn/) 并注册账号(如果注册过,直接登录即可)。
2. 完成注册后,打开[API密钥](https://cloud.siliconflow.cn/account/ak) ,创建新的 API Key,点击密钥进行复制,以备后续使用。
## 2. 部署 NextChat
访问[ NextChat ](https://app.nextchat.dev/)官网,或者本地安装[ ChatGPT-Next-Web ](https://github.com/ChatGPTNextWeb/ChatGPT-Next-Web)之后:
1. 点击页面左下角的“设置”按钮
2. 找到其中的“自定义接口”选项并选中
3. 填入参数:
* **接口地址:** [https://api.siliconflow.cn](https://api.siliconflow.cn)
* **API Key:** 输入“ API 密钥页签 ”生成的 API Key 并填入“自定义模型名”和“模型( model )”
其它自定义模型名可以在 [https://docs.siliconflow.cn/api-reference/chat-completions/chat-completions](https://docs.siliconflow.cn/api-reference/chat-completions/chat-completions) 中查找
# Obsidian Copilot
Source: https://docs.siliconflow.cn/cn/usercases/use-siliconcloud-in-obsidian
Obsidian Copilot 是一款开源的 AI 助手插件,设计简洁,使用方便。用户可通过自带的 API 密钥或本地模型与多种模型交互。支持自定义提示,快速与整个笔记库对话,获取答案和见解。旨在成为注重隐私的终极 AI 助手,深入理解您的个人知识库。
**注:MindBricks 已针对不同应用场景内置了不同模型,主要分为以下几类:**
* 对话模型: 在硅基流动服务商下默认为 Qwen/Qwen3-235B-A22B
* 角色模型: 在硅基流动服务商下默认为 Qwen/Qwen3-235B-A22B
* 推理模型: 在硅基流动服务商下默认为 deepseek-ai/DeepSeek-R1
若需要自定义完全自定义模型, 可使用自定义配置。
# MindSearch
Source: https://docs.siliconflow.cn/cn/usercases/use-siliconcloud-in-mindsearch
## 1. 获取 API Key
1. 打开 SiliconCloud [官网](https://cloud.siliconflow.cn/) 并注册账号(如果注册过,直接登录即可)。
2. 完成注册后,打开[API密钥](https://cloud.siliconflow.cn/account/ak) ,创建新的 API Key,点击密钥进行复制,以备后续使用。
## 2. 部署MindSearch
1. 复制 MindSearch 到本地并安装相关依赖后(参考 [https://github.com/InternLM/MindSearch/blob/main/README.md)](https://github.com/InternLM/MindSearch/blob/main/README.md)) ,
2. 修改:
`/path/to/MindSearch/mindsearch/models.py`
3. 加上调用硅基流动 API 的相关配置。配置如下:
```
internlm_silicon = dict(type=GPTAPI,
model_type='internlm/internlm2_5-7b-chat',
key=os.environ.get('SILICON_API_KEY', 'YOUR SILICON API KEY'),
openai_api_base='https://api.siliconflow.cn/v1/chat/completions',
meta_template=[
dict(role='system', api_role='system'),
dict(role='user', api_role='user'),
dict(role='assistant', api_role='assistant'),
dict(role='environment', api_role='system')
],
top_p=0.8,
top_k=1,
temperature=0,
max_new_tokens=8192,
repetition_penalty=1.02,
stop_words=['<|im_end|>'])
```
加入这段配置后,可以执行相关指令来启动 MindSearch。
4. 启动后端:
```
# 指定硅基流动的 API Key
export SILICON_API_KEY=上面流程中复制的密钥
# 启动
python -m mindsearch.app --lang en --model_format internlm_silicon --search_engine DuckDuckGoSearch
```
5. 启动前端。这里以gradio前端为例,其他前端启动可以参考MindSearch的README:
`python frontend/mindsearch_gradio.py`
## 3. 上传到 HuggingFace Space
我们也可以选择部署到 HuggingFace 的 Space 当中。
1. 在 [https://huggingface.co/new-space](https://huggingface.co/new-space) 创建一个新的Space,
配置为:
Gradio
Template:Blank
Hardware:CPU basic·2 vCPU·16GB·FREE
2. 创建成功后,进入" Settings "设置 API Key。
3. 把第二步中的 MindSearch 目录、requirements.txt 和一个 app.py 一并上传。
app.py 详细内容请参考:[https://huggingface.co/spaces/SmartFlowAI/MindSearch\_X\_SiliconFlow/blob/main/app.py](https://huggingface.co/spaces/SmartFlowAI/MindSearch_X_SiliconFlow/blob/main/app.py)
# NextChat
Source: https://docs.siliconflow.cn/cn/usercases/use-siliconcloud-in-nextchat
## 1. 获取 API Key
1. 打开 SiliconCloud [官网](https://cloud.siliconflow.cn/) 并注册账号(如果注册过,直接登录即可)。
2. 完成注册后,打开[API密钥](https://cloud.siliconflow.cn/account/ak) ,创建新的 API Key,点击密钥进行复制,以备后续使用。
## 2. 部署 NextChat
访问[ NextChat ](https://app.nextchat.dev/)官网,或者本地安装[ ChatGPT-Next-Web ](https://github.com/ChatGPTNextWeb/ChatGPT-Next-Web)之后:
1. 点击页面左下角的“设置”按钮
2. 找到其中的“自定义接口”选项并选中
3. 填入参数:
* **接口地址:** [https://api.siliconflow.cn](https://api.siliconflow.cn)
* **API Key:** 输入“ API 密钥页签 ”生成的 API Key 并填入“自定义模型名”和“模型( model )”
其它自定义模型名可以在 [https://docs.siliconflow.cn/api-reference/chat-completions/chat-completions](https://docs.siliconflow.cn/api-reference/chat-completions/chat-completions) 中查找
# Obsidian Copilot
Source: https://docs.siliconflow.cn/cn/usercases/use-siliconcloud-in-obsidian
Obsidian Copilot 是一款开源的 AI 助手插件,设计简洁,使用方便。用户可通过自带的 API 密钥或本地模型与多种模型交互。支持自定义提示,快速与整个笔记库对话,获取答案和见解。旨在成为注重隐私的终极 AI 助手,深入理解您的个人知识库。
如何在 Obsidian 中使用 SiliconCloud 模型呢?
## 1. 获取 API Key
1. 打开 SiliconCloud [官网](https://cloud.siliconflow.cn/) 并注册账号(如果注册过,直接登录即可)。
2. 完成注册后,打开[API密钥](https://cloud.siliconflow.cn/account/ak) ,创建新的 API Key,点击密钥进行复制,以备后续使用。
## 2. 在 Obsidian Copilot 中使用 SiliconCloud 语言模型系列
### 2.1 安装 Obsidian Copilot
1. 安装 Obsidian 应用,详见[Obsidian 官网](https://obsidian.md/)
2. 在 Obsidian 中安装 Copilot 插件:
 ### 2.2 在 Obsidian Copilot中配置 SiliconCloud 模型
#### 2.2.1 设置 LLM 模型
* 模型: [SiliconCloud 平台 LLM 列表](https://cloud.siliconflow.cn/models?types=chat)
* Provider: 3rd party (openai-format)
* Base URL: [https://api.siliconflow.cn/v1](https://api.siliconflow.cn/v1)
* API Key: [获取 API Key](use-siliconcloud-in-obsidian#1-api-key)
### 2.2 在 Obsidian Copilot中配置 SiliconCloud 模型
#### 2.2.1 设置 LLM 模型
* 模型: [SiliconCloud 平台 LLM 列表](https://cloud.siliconflow.cn/models?types=chat)
* Provider: 3rd party (openai-format)
* Base URL: [https://api.siliconflow.cn/v1](https://api.siliconflow.cn/v1)
* API Key: [获取 API Key](use-siliconcloud-in-obsidian#1-api-key)
 #### 2.2.2 设置 Embedding 模型
* 模型: 详见 [SiliconCloud 平台 Embedding 列表](https://cloud.siliconflow.cn/models?types=embedding)
* Provider: 3rd party (openai-format)
* Base URL: [https://api.siliconflow.cn/v1](https://api.siliconflow.cn/v1)
* API Key: [获取 API Key](use-siliconcloud-in-obsidian#1-api-key)
#### 2.2.2 设置 Embedding 模型
* 模型: 详见 [SiliconCloud 平台 Embedding 列表](https://cloud.siliconflow.cn/models?types=embedding)
* Provider: 3rd party (openai-format)
* Base URL: [https://api.siliconflow.cn/v1](https://api.siliconflow.cn/v1)
* API Key: [获取 API Key](use-siliconcloud-in-obsidian#1-api-key)
 #### 2.2.3 加载配置
#### 2.2.3 加载配置
 ### 2.3 在 Obsidian Copilot中使用 SiliconCloud 模型
接下来就可以基于 SiliconCloud 模型和本地知识库进行检索和问答了。
### 2.3 在 Obsidian Copilot中使用 SiliconCloud 模型
接下来就可以基于 SiliconCloud 模型和本地知识库进行检索和问答了。

 # OpenManus
Source: https://docs.siliconflow.cn/cn/usercases/use-siliconcloud-in-openmanus
## 1. 安装 OpenManus
参考[安装指南](https://github.com/mannaandpoem/OpenManus?tab=readme-ov-file#installation)完成相关代码下载和依赖安装。
## 2. 配置 OpenManus
在 config 目录设置 config.toml,参考如下配置:
```toml
# Global LLM configuration
[llm]
model = "Qwen/QwQ-32B" # 或者平台中的其他支持 function calling 模型,参见[Function Calling](https://docs.siliconflow.cn/cn/userguide/guides/function-calling)
base_url = "https://api.siliconflow.cn/v1"
api_key = "your_api_key_from_siliconcloud"
max_tokens = 16384
temperature = 0.6
# Optional configuration for specific LLM models
[llm.vision]
model = "Qwen/Qwen2-VL-72B-Instruct" # 或者平台中的其他视觉语言模型,参见[vision](https://docs.siliconflow.cn/cn/userguide/capabilities/vision)
base_url = "https://api.siliconflow.cn/v1"
api_key = "your_api_key_from_siliconcloud"
```
## 3. 使用 OpenManus
通过命令行
```shell
python main.py
```
### 3.1 下面是某次运行的大致流程:
| 步骤 | 工作内容 | 使用工具 | 输入/参数 | 输出/结果 |
| -- | ------------------- | --------------- | -------------------------------------------------- | ------------- |
| 1 | 分析用户需求,确定搜索策略 | google\_search | "global soybean market analysis 2025 report" | 搜索结果链接列表 |
| 2 | 分析搜索结果,决定使用中文搜索 | google\_search | "全球大豆市场 2025 年分析报告" | 搜索结果链接列表 |
| 3 | 分析中文搜索结果,决定访问USDA网站 | browser\_use | action: "navigate", url: USDA网站链接 | 成功导航到USDA网站 |
| 4 | 获取USDA网站HTML内容 | browser\_use | action: "get\_html" | 网页HTML内容 |
| 5 | 分析HTML内容,决定保存数据 | file\_saver | 保存HTML内容到文件 | 成功保存HTML文件 |
| 6 | 分析如何处理HTML数据 | - | - | 思考处理HTML的策略 |
| 7 | 编写Python脚本解析HTML数据 | python\_execute | 解析HTML的Python代码 | 解析结果(大豆产量数据) |
| 8 | 分析解析结果,决定获取更多数据 | browser\_use | action: "navigate", url: FAO网站链接 | 成功导航到FAO网站 |
| 9 | 获取FAO网站HTML内容 | browser\_use | action: "get\_html" | 网页HTML内容 |
| 10 | 编写Python脚本解析FAO数据 | python\_execute | 解析FAO数据的Python代码 | 解析结果(FAO大豆数据) |
| 11 | 编写Python脚本合并数据 | python\_execute | 合并USDA和FAO数据的代码 | 合并后的数据集 |
| 12 | 编写Python脚本生成图表 | python\_execute | 生成图表的Python代码 | 生成的图表数据 |
| 13 | 保存生成的图表 | file\_saver | 保存图表数据到文件 | 成功保存图表文件 |
| 14 | 搜索气候变化对大豆影响 | google\_search | "climate change impact on soybean production 2025" | 搜索结果链接列表 |
| 15 | 访问气候变化研究网站 | browser\_use | action: "navigate", url: 气候研究网站链接 | 成功导航到气候研究网站 |
| 16 | 获取气候研究网站HTML | browser\_use | action: "get\_html" | 网页HTML内容 |
| 17 | 编写Python脚本分析气候数据 | python\_execute | 分析气候数据的Python代码 | 气候影响分析结果 |
| 18 | 编写Python脚本整合所有数据 | python\_execute | 整合所有数据的Python代码 | 整合后的完整数据集 |
| 19 | 编写Python脚本生成报告框架 | python\_execute | 生成报告框架的Python代码 | 报告HTML框架 |
| 20 | 编写Python脚本添加数据到报告 | python\_execute | 添加数据到报告的Python代码 | 带数据的报告HTML |
| 21 | 编写Python脚本添加图表到报告 | python\_execute | 添加图表到报告的Python代码 | 带图表的报告HTML |
| 22 | 编写Python脚本添加气候分析到报告 | python\_execute | 添加气候分析的Python代码 | 带气候分析的报告HTML |
| 23 | 编写Python脚本添加结论到报告 | python\_execute | 添加结论的Python代码 | 带结论的完整报告HTML |
| 24 | 保存完整报告HTML | file\_saver | 保存报告HTML到文件 | 成功保存报告HTML文件 |
| 25 | 编写Python脚本将报告转为PDF | python\_execute | HTML转PDF的Python代码 | 报告PDF数据 |
| 26 | 保存报告PDF | file\_saver | 保存PDF数据到文件 | 成功保存报告PDF文件 |
| 27 | 编写Python脚本创建报告摘要 | python\_execute | 创建摘要的Python代码 | 报告摘要文本 |
| 28 | 保存报告摘要 | file\_saver | 保存摘要到文件 | 成功保存摘要文件 |
| 29 | 编写Python脚本发送报告邮件 | python\_execute | 发送邮件的Python代码 | 邮件发送结果 |
| 30 | 总结完成的工作,等待下一步指示 | - | - | 最终总结和下一步建议 |
### 3.2 执行日志
INFO \[browser\_use] BrowserUse logging setup complete with level info
INFO \[root] Anonymized telemetry enabled. See [https://docs.browser-use.com/development/telemetry](https://docs.browser-use.com/development/telemetry) for more information.
Enter your prompt (or 'exit' to quit): 全球大豆市场 2025 年分析报告
2025-03-08 18:08:00.304 | WARNING | **main**:main:15 - Processing your request...
2025-03-08 18:08:00.305 | INFO | app.agent.base:run:137 - Executing step 1/30
2025-03-08 18:08:25.067 | INFO | app.agent.toolcall:think:53 - ✨ Manus's thoughts: 好的,我现在需要处理用户关于“全球大豆市场2025年分析报告”的请求。首先,用户想要一份分析报告,这可能包括市场趋势、产量、价格、主要生产国、消费国以及未来预测等方面的信息。由于报告涉及未来数据,可能需要最新的行业数据和预测,而这些信息通常来自市场研究公司或权威机构的报告。
接下来,我需要考虑如何获取这些信息。用户提供的工具包括Google搜索、浏览器使用、Python执行和文件保存。首先,我应该使用Google搜索来查找相关的分析报告或数据来源。可能需要搜索关键词如“global soybean market analysis 2025 report”或者“大豆市场预测2025”,看看是否有权威机构如美国农业部(USDA)、国际粮食政策研究所(IFPRI)或市场研究公司如Frost & Sullivan、Mordor Intelligence等发布的报告。
使用Google搜索工具时,我需要构造合适的查询词,并可能需要多个关键词组合来确保找到最新的信息。搜索结果返回的链接可能包括PDF报告、行业分析文章或新闻稿。之后,可能需要使用浏览器工具访问这些链接,查看具体内容,提取关键数据。如果某些报告需要付费或注册,可能需要寻找免费摘要或通过其他途径获取。
另外,用户可能希望报告以结构化的方式呈现,比如图表或数据表格。这时候可能需要使用Python来处理数据,例如从网页中抓取数据,或者生成图表。但首先需要确保有可用的数据源。如果搜索到的数据是文本形式,可能需要手动整理或使用Python的解析库如BeautifulSoup或Pandas来处理。
保存最终的报告或分析结果可能需要使用文件保存工具,将整理好的数据、图表或总结文本保存为文档或代码文件。例如,将分析结果写入Markdown或PDF文件,或者生成一个HTML页面展示图表。
现在,第一步应该是执行Google搜索,收集相关链接。然后根据搜索结果决定下一步行动,可能是访问具体网页提取数据,或者发现需要进一步处理的数据。如果搜索结果中有直接可下载的PDF报告,可能需要使用浏览器工具下载文件,但可能需要处理文件内容,比如使用Python读取PDF内容。如果报告需要付费,可能需要寻找替代资源或建议用户购买。
另外,可能需要考虑时间因素,2025年的预测数据可能在2023或2024年的报告中已经存在,因此搜索时可能需要限定时间范围。不过Google搜索工具的参数中没有时间选项,可能需要在查询词中加入年份,如“2023 global soybean market forecast 2025”。
总结步骤:
1. 使用Google搜索查找相关报告链接。
2. 分析搜索结果,访问相关网页,提取关键数据。
3. 使用Python处理和整理数据,生成图表或分析结果。
4. 将最终报告保存为文件。
现在,首先执行Google搜索,看看能找到哪些资源。可能需要多次调整关键词以确保找到足够的信息。如果搜索结果不够,可能需要进一步细化查询,例如按地区、主要公司或特定方面(如价格趋势、产量预测)来搜索。
```
"name": "google_search",
"arguments": {
"query": "global soybean market analysis 2025 report",
"num_results": 10
}
```
如需查看详细结果,请[参见此处链接](https://raw.githubusercontent.com/siliconflow/siliconcloud-cookbook/refs/heads/main/examples/openmanus/30-step-log.txt)
# 却惑几菩提
Source: https://docs.siliconflow.cn/cn/usercases/use-siliconcloud-in-qhgpt
## 一、关于却惑几菩提
[却惑几菩提](https://qhgpt.aihub.ren) 是一个将人工智能技术与佛教文化深度融合的对话平台。在这里,以禅宗思想、佛教经典为根基,借助 AI 的强大语言处理能力,为用户打造一场充满智慧与禅意的对话之旅。无论您是想探寻佛法的真谛、求解生活困惑,还是单纯想感受禅意的宁静,都能在与平台的对话中有所收获。
平台秉持 “自性求佛” 的理念,希望通过一问一答的形式,引导您向内思考,体悟内心的智慧。同时,平台承诺不存储任何对话信息,在页面刷新后,所有内容都会重置,充分保障用户的隐私安全。但也请您注意,平台内容仅作为文化交流与探讨,若存在佛教知识方面的不准确之处,还望宽容理解。
## 二、如何使用
### 1. API 配置
本平台基于**硅基流动 API** 驱动,平台内置 API,可直接开启对话。
> 建议设置你自己的硅基流动 API 密钥,将会优先调用。可避免公用 API 因使用人数过多导致的回复速率问题。
1、打开 **硅基流动 [官网](https://cloud.siliconflow.cn/)** 并注册账号(如果注册过,直接登录即可)。
2、完成注册后,进入 [API 密钥](https://cloud.siliconflow.cn/account/ak) ,点击 **新建 API 密钥**,点击密钥进行复制保存,以备后续使用。
# OpenManus
Source: https://docs.siliconflow.cn/cn/usercases/use-siliconcloud-in-openmanus
## 1. 安装 OpenManus
参考[安装指南](https://github.com/mannaandpoem/OpenManus?tab=readme-ov-file#installation)完成相关代码下载和依赖安装。
## 2. 配置 OpenManus
在 config 目录设置 config.toml,参考如下配置:
```toml
# Global LLM configuration
[llm]
model = "Qwen/QwQ-32B" # 或者平台中的其他支持 function calling 模型,参见[Function Calling](https://docs.siliconflow.cn/cn/userguide/guides/function-calling)
base_url = "https://api.siliconflow.cn/v1"
api_key = "your_api_key_from_siliconcloud"
max_tokens = 16384
temperature = 0.6
# Optional configuration for specific LLM models
[llm.vision]
model = "Qwen/Qwen2-VL-72B-Instruct" # 或者平台中的其他视觉语言模型,参见[vision](https://docs.siliconflow.cn/cn/userguide/capabilities/vision)
base_url = "https://api.siliconflow.cn/v1"
api_key = "your_api_key_from_siliconcloud"
```
## 3. 使用 OpenManus
通过命令行
```shell
python main.py
```
### 3.1 下面是某次运行的大致流程:
| 步骤 | 工作内容 | 使用工具 | 输入/参数 | 输出/结果 |
| -- | ------------------- | --------------- | -------------------------------------------------- | ------------- |
| 1 | 分析用户需求,确定搜索策略 | google\_search | "global soybean market analysis 2025 report" | 搜索结果链接列表 |
| 2 | 分析搜索结果,决定使用中文搜索 | google\_search | "全球大豆市场 2025 年分析报告" | 搜索结果链接列表 |
| 3 | 分析中文搜索结果,决定访问USDA网站 | browser\_use | action: "navigate", url: USDA网站链接 | 成功导航到USDA网站 |
| 4 | 获取USDA网站HTML内容 | browser\_use | action: "get\_html" | 网页HTML内容 |
| 5 | 分析HTML内容,决定保存数据 | file\_saver | 保存HTML内容到文件 | 成功保存HTML文件 |
| 6 | 分析如何处理HTML数据 | - | - | 思考处理HTML的策略 |
| 7 | 编写Python脚本解析HTML数据 | python\_execute | 解析HTML的Python代码 | 解析结果(大豆产量数据) |
| 8 | 分析解析结果,决定获取更多数据 | browser\_use | action: "navigate", url: FAO网站链接 | 成功导航到FAO网站 |
| 9 | 获取FAO网站HTML内容 | browser\_use | action: "get\_html" | 网页HTML内容 |
| 10 | 编写Python脚本解析FAO数据 | python\_execute | 解析FAO数据的Python代码 | 解析结果(FAO大豆数据) |
| 11 | 编写Python脚本合并数据 | python\_execute | 合并USDA和FAO数据的代码 | 合并后的数据集 |
| 12 | 编写Python脚本生成图表 | python\_execute | 生成图表的Python代码 | 生成的图表数据 |
| 13 | 保存生成的图表 | file\_saver | 保存图表数据到文件 | 成功保存图表文件 |
| 14 | 搜索气候变化对大豆影响 | google\_search | "climate change impact on soybean production 2025" | 搜索结果链接列表 |
| 15 | 访问气候变化研究网站 | browser\_use | action: "navigate", url: 气候研究网站链接 | 成功导航到气候研究网站 |
| 16 | 获取气候研究网站HTML | browser\_use | action: "get\_html" | 网页HTML内容 |
| 17 | 编写Python脚本分析气候数据 | python\_execute | 分析气候数据的Python代码 | 气候影响分析结果 |
| 18 | 编写Python脚本整合所有数据 | python\_execute | 整合所有数据的Python代码 | 整合后的完整数据集 |
| 19 | 编写Python脚本生成报告框架 | python\_execute | 生成报告框架的Python代码 | 报告HTML框架 |
| 20 | 编写Python脚本添加数据到报告 | python\_execute | 添加数据到报告的Python代码 | 带数据的报告HTML |
| 21 | 编写Python脚本添加图表到报告 | python\_execute | 添加图表到报告的Python代码 | 带图表的报告HTML |
| 22 | 编写Python脚本添加气候分析到报告 | python\_execute | 添加气候分析的Python代码 | 带气候分析的报告HTML |
| 23 | 编写Python脚本添加结论到报告 | python\_execute | 添加结论的Python代码 | 带结论的完整报告HTML |
| 24 | 保存完整报告HTML | file\_saver | 保存报告HTML到文件 | 成功保存报告HTML文件 |
| 25 | 编写Python脚本将报告转为PDF | python\_execute | HTML转PDF的Python代码 | 报告PDF数据 |
| 26 | 保存报告PDF | file\_saver | 保存PDF数据到文件 | 成功保存报告PDF文件 |
| 27 | 编写Python脚本创建报告摘要 | python\_execute | 创建摘要的Python代码 | 报告摘要文本 |
| 28 | 保存报告摘要 | file\_saver | 保存摘要到文件 | 成功保存摘要文件 |
| 29 | 编写Python脚本发送报告邮件 | python\_execute | 发送邮件的Python代码 | 邮件发送结果 |
| 30 | 总结完成的工作,等待下一步指示 | - | - | 最终总结和下一步建议 |
### 3.2 执行日志
INFO \[browser\_use] BrowserUse logging setup complete with level info
INFO \[root] Anonymized telemetry enabled. See [https://docs.browser-use.com/development/telemetry](https://docs.browser-use.com/development/telemetry) for more information.
Enter your prompt (or 'exit' to quit): 全球大豆市场 2025 年分析报告
2025-03-08 18:08:00.304 | WARNING | **main**:main:15 - Processing your request...
2025-03-08 18:08:00.305 | INFO | app.agent.base:run:137 - Executing step 1/30
2025-03-08 18:08:25.067 | INFO | app.agent.toolcall:think:53 - ✨ Manus's thoughts: 好的,我现在需要处理用户关于“全球大豆市场2025年分析报告”的请求。首先,用户想要一份分析报告,这可能包括市场趋势、产量、价格、主要生产国、消费国以及未来预测等方面的信息。由于报告涉及未来数据,可能需要最新的行业数据和预测,而这些信息通常来自市场研究公司或权威机构的报告。
接下来,我需要考虑如何获取这些信息。用户提供的工具包括Google搜索、浏览器使用、Python执行和文件保存。首先,我应该使用Google搜索来查找相关的分析报告或数据来源。可能需要搜索关键词如“global soybean market analysis 2025 report”或者“大豆市场预测2025”,看看是否有权威机构如美国农业部(USDA)、国际粮食政策研究所(IFPRI)或市场研究公司如Frost & Sullivan、Mordor Intelligence等发布的报告。
使用Google搜索工具时,我需要构造合适的查询词,并可能需要多个关键词组合来确保找到最新的信息。搜索结果返回的链接可能包括PDF报告、行业分析文章或新闻稿。之后,可能需要使用浏览器工具访问这些链接,查看具体内容,提取关键数据。如果某些报告需要付费或注册,可能需要寻找免费摘要或通过其他途径获取。
另外,用户可能希望报告以结构化的方式呈现,比如图表或数据表格。这时候可能需要使用Python来处理数据,例如从网页中抓取数据,或者生成图表。但首先需要确保有可用的数据源。如果搜索到的数据是文本形式,可能需要手动整理或使用Python的解析库如BeautifulSoup或Pandas来处理。
保存最终的报告或分析结果可能需要使用文件保存工具,将整理好的数据、图表或总结文本保存为文档或代码文件。例如,将分析结果写入Markdown或PDF文件,或者生成一个HTML页面展示图表。
现在,第一步应该是执行Google搜索,收集相关链接。然后根据搜索结果决定下一步行动,可能是访问具体网页提取数据,或者发现需要进一步处理的数据。如果搜索结果中有直接可下载的PDF报告,可能需要使用浏览器工具下载文件,但可能需要处理文件内容,比如使用Python读取PDF内容。如果报告需要付费,可能需要寻找替代资源或建议用户购买。
另外,可能需要考虑时间因素,2025年的预测数据可能在2023或2024年的报告中已经存在,因此搜索时可能需要限定时间范围。不过Google搜索工具的参数中没有时间选项,可能需要在查询词中加入年份,如“2023 global soybean market forecast 2025”。
总结步骤:
1. 使用Google搜索查找相关报告链接。
2. 分析搜索结果,访问相关网页,提取关键数据。
3. 使用Python处理和整理数据,生成图表或分析结果。
4. 将最终报告保存为文件。
现在,首先执行Google搜索,看看能找到哪些资源。可能需要多次调整关键词以确保找到足够的信息。如果搜索结果不够,可能需要进一步细化查询,例如按地区、主要公司或特定方面(如价格趋势、产量预测)来搜索。
```
"name": "google_search",
"arguments": {
"query": "global soybean market analysis 2025 report",
"num_results": 10
}
```
如需查看详细结果,请[参见此处链接](https://raw.githubusercontent.com/siliconflow/siliconcloud-cookbook/refs/heads/main/examples/openmanus/30-step-log.txt)
# 却惑几菩提
Source: https://docs.siliconflow.cn/cn/usercases/use-siliconcloud-in-qhgpt
## 一、关于却惑几菩提
[却惑几菩提](https://qhgpt.aihub.ren) 是一个将人工智能技术与佛教文化深度融合的对话平台。在这里,以禅宗思想、佛教经典为根基,借助 AI 的强大语言处理能力,为用户打造一场充满智慧与禅意的对话之旅。无论您是想探寻佛法的真谛、求解生活困惑,还是单纯想感受禅意的宁静,都能在与平台的对话中有所收获。
平台秉持 “自性求佛” 的理念,希望通过一问一答的形式,引导您向内思考,体悟内心的智慧。同时,平台承诺不存储任何对话信息,在页面刷新后,所有内容都会重置,充分保障用户的隐私安全。但也请您注意,平台内容仅作为文化交流与探讨,若存在佛教知识方面的不准确之处,还望宽容理解。
## 二、如何使用
### 1. API 配置
本平台基于**硅基流动 API** 驱动,平台内置 API,可直接开启对话。
> 建议设置你自己的硅基流动 API 密钥,将会优先调用。可避免公用 API 因使用人数过多导致的回复速率问题。
1、打开 **硅基流动 [官网](https://cloud.siliconflow.cn/)** 并注册账号(如果注册过,直接登录即可)。
2、完成注册后,进入 [API 密钥](https://cloud.siliconflow.cn/account/ak) ,点击 **新建 API 密钥**,点击密钥进行复制保存,以备后续使用。
 ### 2. 填入 API Key
1、请先阅读页面下方的 **【告示】**
### 2. 填入 API Key
1、请先阅读页面下方的 **【告示】**
 2、在页面对话输入框,右下角位置找到 **【拈花】**,点击会展开 **【API Key** 以及 **自定义角色】**输入框。请在**【API Key】**右侧的输入框中**粘贴您刚刚在硅基流动页面复制保存的 API 密钥**。
2、在页面对话输入框,右下角位置找到 **【拈花】**,点击会展开 **【API Key** 以及 **自定义角色】**输入框。请在**【API Key】**右侧的输入框中**粘贴您刚刚在硅基流动页面复制保存的 API 密钥**。
 3、点击人物头像,在头像下方的输入框中,输入您想要询问的问题、探讨的话题或内心的困惑。例如,您可以问 “如何理解‘诸行无常’?” 或 “生活中遇到烦恼该如何化解?”回车或点击右侧【 **卍** 】按钮开启对话。输入框左侧为\*\*【清空对话】**,右侧为 **【发送对话】** 、**【导出对话记录】**,点击**【录经】**复制当前回复,点击 **【轮转】** 将重新生成回复。等待回复过程中点击**【唵】\*\* 将终止回复。
3、点击人物头像,在头像下方的输入框中,输入您想要询问的问题、探讨的话题或内心的困惑。例如,您可以问 “如何理解‘诸行无常’?” 或 “生活中遇到烦恼该如何化解?”回车或点击右侧【 **卍** 】按钮开启对话。输入框左侧为\*\*【清空对话】**,右侧为 **【发送对话】** 、**【导出对话记录】**,点击**【录经】**复制当前回复,点击 **【轮转】** 将重新生成回复。等待回复过程中点击**【唵】\*\* 将终止回复。
 4、当前版本仍处于持续迭代升级阶段,平台将陆续融入更多禅意新功能与趣味小彩蛋,静待您前来探索发现。
注:本指南由合作伙伴提供,内容涉及宗教或哲学元素,旨在展示其技术应用场景,SiliconCloud 平台不持任何宗教立场。
# 轻流无代码开发平台
Source: https://docs.siliconflow.cn/cn/usercases/use-siliconcloud-in-qingflow
## 1. 关于轻流
[轻流](https://qingflow.com)是一款领先的无代码开发平台,致力于为企业提供便捷、高效、智能的业务系统搭建工具。通过轻流平台,企业用户无需编写复杂代码即可快速构建个性化业务应用,轻松实现业务流程的自动化与智能化!
本文将介绍如何借助 SiliconCloud 提供的 API 服务在轻流中快捷使用,赋能企业业务系统。
## 2. 使用轻流
无需下载安装,前往轻流官网,注册即可使用。[注册入口](https://qingflow.com/passport/register)
## 3. 在轻流中使用 SiliconCloud 连接器
### 3.1 订阅连接器
注册轻流之后,进入工作区点击“更多”-“轻商城”进入轻流连接中心,点击“硅基流动”,点击“订阅”,如下图所示。
4、当前版本仍处于持续迭代升级阶段,平台将陆续融入更多禅意新功能与趣味小彩蛋,静待您前来探索发现。
注:本指南由合作伙伴提供,内容涉及宗教或哲学元素,旨在展示其技术应用场景,SiliconCloud 平台不持任何宗教立场。
# 轻流无代码开发平台
Source: https://docs.siliconflow.cn/cn/usercases/use-siliconcloud-in-qingflow
## 1. 关于轻流
[轻流](https://qingflow.com)是一款领先的无代码开发平台,致力于为企业提供便捷、高效、智能的业务系统搭建工具。通过轻流平台,企业用户无需编写复杂代码即可快速构建个性化业务应用,轻松实现业务流程的自动化与智能化!
本文将介绍如何借助 SiliconCloud 提供的 API 服务在轻流中快捷使用,赋能企业业务系统。
## 2. 使用轻流
无需下载安装,前往轻流官网,注册即可使用。[注册入口](https://qingflow.com/passport/register)
## 3. 在轻流中使用 SiliconCloud 连接器
### 3.1 订阅连接器
注册轻流之后,进入工作区点击“更多”-“轻商城”进入轻流连接中心,点击“硅基流动”,点击“订阅”,如下图所示。
 ### 3.2 在业务系统中使用硅基流动连接器
在应用中插入“Q-Linker”字段,配置模式选择“使用连接中心模板”“硅基流动”后,即可选择你所需要的AI大模型;发布后即可投入使用。
### 3.2 在业务系统中使用硅基流动连接器
在应用中插入“Q-Linker”字段,配置模式选择“使用连接中心模板”“硅基流动”后,即可选择你所需要的AI大模型;发布后即可投入使用。
 值得注意的是,在轻流平台使用硅基流动提供的大模型服务时,无需额外填写自己的 API key,轻流平台已自动配置与硅基流动账户的对接,大家可以轻松享受便捷的服务接入体验。
# Sider
Source: https://docs.siliconflow.cn/cn/usercases/use-siliconcloud-in-sider
作为 2023 年度 “Chrome 年度精选插件”,Sider 获得了 50K+ “5星好评”,并有 6+百万 的活跃用户。Sider 浏览器插件主要解决:
* Sider(ChatGPT 侧边栏)是您有用的人工智能助手,您可以在浏览任何网站时使用它。
开发者可以打开 [Sider官网](https://sider.ai/zh-CN/) 来使用 Sider 应用。
Sider 为满足软件开发者的需求,提供了 OpenAI API的兼容模型注册方式,以便大家可以更加便利的使用大家想要的模型。
作为集合顶尖大模型的一站式云服务平台,SiliconCloud 致力于为开发者提供更快、更便宜、更全面、体验更丝滑的模型API。
那么怎么在 Sider 中使用 SiliconCloud 呢?
## 1. 获取 API Key
1. 打开 SiliconCloud [官网](https://cloud.siliconflow.cn/) 并注册账号(如果注册过,直接登录即可)。
2. 完成注册后,打开[API密钥](https://cloud.siliconflow.cn/account/ak) ,创建新的 API Key,点击密钥进行复制,以备后续使用。
## 2. 在 Sider 中使用 SiliconCloud 语言模型系列
按照下图操作即可
值得注意的是,在轻流平台使用硅基流动提供的大模型服务时,无需额外填写自己的 API key,轻流平台已自动配置与硅基流动账户的对接,大家可以轻松享受便捷的服务接入体验。
# Sider
Source: https://docs.siliconflow.cn/cn/usercases/use-siliconcloud-in-sider
作为 2023 年度 “Chrome 年度精选插件”,Sider 获得了 50K+ “5星好评”,并有 6+百万 的活跃用户。Sider 浏览器插件主要解决:
* Sider(ChatGPT 侧边栏)是您有用的人工智能助手,您可以在浏览任何网站时使用它。
开发者可以打开 [Sider官网](https://sider.ai/zh-CN/) 来使用 Sider 应用。
Sider 为满足软件开发者的需求,提供了 OpenAI API的兼容模型注册方式,以便大家可以更加便利的使用大家想要的模型。
作为集合顶尖大模型的一站式云服务平台,SiliconCloud 致力于为开发者提供更快、更便宜、更全面、体验更丝滑的模型API。
那么怎么在 Sider 中使用 SiliconCloud 呢?
## 1. 获取 API Key
1. 打开 SiliconCloud [官网](https://cloud.siliconflow.cn/) 并注册账号(如果注册过,直接登录即可)。
2. 完成注册后,打开[API密钥](https://cloud.siliconflow.cn/account/ak) ,创建新的 API Key,点击密钥进行复制,以备后续使用。
## 2. 在 Sider 中使用 SiliconCloud 语言模型系列
按照下图操作即可
 # ToMemo
Source: https://docs.siliconflow.cn/cn/usercases/use-siliconcloud-in-tomemo
ToMemo 是一款多功能快捷键盘 + 剪切内容记录 + 懒人短语的便签应用。可以帮助你快速获取和输入常用的内容,比如邮箱地址、快递地址、身份证号、发票抬头等。
## 添加 SiliconFlow 供应商
进入添加页面后,直接点击「供应商」选项,在里面选择 SiliconFlow (硅基流动),此时,会自动填入名称、Base URL 和接口类型。
# ToMemo
Source: https://docs.siliconflow.cn/cn/usercases/use-siliconcloud-in-tomemo
ToMemo 是一款多功能快捷键盘 + 剪切内容记录 + 懒人短语的便签应用。可以帮助你快速获取和输入常用的内容,比如邮箱地址、快递地址、身份证号、发票抬头等。
## 添加 SiliconFlow 供应商
进入添加页面后,直接点击「供应商」选项,在里面选择 SiliconFlow (硅基流动),此时,会自动填入名称、Base URL 和接口类型。
 ## 从 SiliconFlow 获取 API Key
SiliconFlow 的 API Key 获取地址:[点击打开 ](https://cloud.siliconflow.cn/account/ak)
点击后,完成登录,进入到下面所展示的页面。
点击「创建API密钥」按钮,逐步完成创建。
需要**拷贝 API 密钥**, 并妥善保管。
## 从 SiliconFlow 获取 API Key
SiliconFlow 的 API Key 获取地址:[点击打开 ](https://cloud.siliconflow.cn/account/ak)
点击后,完成登录,进入到下面所展示的页面。
点击「创建API密钥」按钮,逐步完成创建。
需要**拷贝 API 密钥**, 并妥善保管。
 ### 拉取模型
将上面获取的 API Key,填入到当前页面的 API Key 输入框中。
点击「拉取模型」按钮,会自动拉取模型。
### 拉取模型
将上面获取的 API Key,填入到当前页面的 API Key 输入框中。
点击「拉取模型」按钮,会自动拉取模型。
 然后选择需要加载的模型,最后点击「保存」按钮,完成 SiliconFlow 的集成。
💡
**Tip**
需要选择文字生成模型,应用暂时不支持图片输入和输出。
## 添加单词助理 🤓
进入「AI助手」页面,开始添加 AI 助手。
我们从模版中添加「单词助理 🤓」。
然后选择需要加载的模型,最后点击「保存」按钮,完成 SiliconFlow 的集成。
💡
**Tip**
需要选择文字生成模型,应用暂时不支持图片输入和输出。
## 添加单词助理 🤓
进入「AI助手」页面,开始添加 AI 助手。
我们从模版中添加「单词助理 🤓」。
 ## 键盘中的单词助理 🤓
在键盘中使用「单词助理」,需要先在「AI助手」中添加「单词助理」的助手。
## 键盘中的单词助理 🤓
在键盘中使用「单词助理」,需要先在「AI助手」中添加「单词助理」的助手。
 # Trae
Source: https://docs.siliconflow.cn/cn/usercases/use-siliconcloud-in-trae
[Trae](https://www.trae.com.cn/) 是字节推出的首个 AI IDE,Trae 预置了一系列业内表现比较出色的模型,你可以直接切换不同的模型进行使用。此外,Trae Chat 模式还支持通过 API 密钥(API Key)接入硅基流动的模型资源,从而满足个性化的需求。
## 切换模型
在输入框的右下角,点击当前模型名称,打开模型列表,然后选择你想使用的模型。
# Trae
Source: https://docs.siliconflow.cn/cn/usercases/use-siliconcloud-in-trae
[Trae](https://www.trae.com.cn/) 是字节推出的首个 AI IDE,Trae 预置了一系列业内表现比较出色的模型,你可以直接切换不同的模型进行使用。此外,Trae Chat 模式还支持通过 API 密钥(API Key)接入硅基流动的模型资源,从而满足个性化的需求。
## 切换模型
在输入框的右下角,点击当前模型名称,打开模型列表,然后选择你想使用的模型。
 各个模型的能力不同,你可以将鼠标悬浮至模型名称上,然后查看该模型支持的能力。
## 添加硅基流动模型
1、前往 **头像** > **设置** > **Trae AI** > **模型管理**。
2、点击 **添加模型** 按钮。
各个模型的能力不同,你可以将鼠标悬浮至模型名称上,然后查看该模型支持的能力。
## 添加硅基流动模型
1、前往 **头像** > **设置** > **Trae AI** > **模型管理**。
2、点击 **添加模型** 按钮。
 页面上显示 **添加模型** 窗口。
页面上显示 **添加模型** 窗口。
 3、选择 **服务商**为硅基流动
3、选择 **服务商**为硅基流动
 4、选择 **模型**:
4、选择 **模型**:
 ○ 直接从列表中选择 Trae 为每个服务商预置的模型(均为默认版本)。
○ 若你希望使用其他模型或使用特定版本的模型,点击列表中的 **使用其他模型**,然后在输入框中填写模型 ID。
5、填写 **API 密钥**
点击 **获取 API 密钥** 按钮,Trae 会为你打开硅基流动的 API 密钥配置页面。(若未注册/登录对应网站,需先完成注册/登录动作)
进入页面后创建新的 API Key,点击密钥进行复制。
6、点击 **添加模型** 按钮
Trae 将调用服务商的接口来检测 API 密钥是否有效。可能的结果如下:
○ 若连接成功,该自定义模型会被添加。
○ 若连接失败,**添加模型** 窗口中展示错误信息和服务商返回的错误日志,你可以参考这些信息排查问题。
**管理自定义模型**
在设置中心,你可以管理自定义模型。
○ 直接从列表中选择 Trae 为每个服务商预置的模型(均为默认版本)。
○ 若你希望使用其他模型或使用特定版本的模型,点击列表中的 **使用其他模型**,然后在输入框中填写模型 ID。
5、填写 **API 密钥**
点击 **获取 API 密钥** 按钮,Trae 会为你打开硅基流动的 API 密钥配置页面。(若未注册/登录对应网站,需先完成注册/登录动作)
进入页面后创建新的 API Key,点击密钥进行复制。
6、点击 **添加模型** 按钮
Trae 将调用服务商的接口来检测 API 密钥是否有效。可能的结果如下:
○ 若连接成功,该自定义模型会被添加。
○ 若连接失败,**添加模型** 窗口中展示错误信息和服务商返回的错误日志,你可以参考这些信息排查问题。
**管理自定义模型**
在设置中心,你可以管理自定义模型。
 | **编号** | **操作类型** | **说明** |
| ------ | -------- | ---------------------------------------------------------------------------- |
| 1 | 编辑模型 | 点击 **编辑** 图标,然后在弹窗中修改服务商、模型名称、API 密钥等信息。 |
| 2 | 删除模型 | 点击 **删除** 图标,然后在弹窗中二次确认。删除后,当前模型将被从列表里移除,不可被继续使用。 |
| 3 | 启用/禁用模型 | 若你不希望删除模型,但在一段时间内无需使用这个模型,你可以禁用该模型。被禁用的模型将保留在设置页面的列表中,但不会出现在 AI 对话框的模型选择列表中。 |
# translate.js
Source: https://docs.siliconflow.cn/cn/usercases/use-siliconcloud-in-translate-js
## 简介
[translate.js](https://gitee.com/mail_osc/translate) 是面向前端开发者的 AI i18n
专注于多语言切换能力,两行 js 实现 html 全自动翻译,百多语种一键切换,无需改动页面、无语言配置文件、支持[几十个微调扩展指令](https://gitee.com/mail_osc/translate),满足你的一切个性化需求、对 SEO 友好。
采用 MIT 协议进行开源: [GitHub](https://github.com/xnx3/translate) | [Gitee](https://gitee.com/mail_osc/translate) ,完全免费开放并允许商业使用。
本文将详细介绍依靠 [硅基流动](https://cloud.siliconflow.cn/i/64MyJQtM) 提供的 API 服务,让你的网站支持上百语种切换。
| **编号** | **操作类型** | **说明** |
| ------ | -------- | ---------------------------------------------------------------------------- |
| 1 | 编辑模型 | 点击 **编辑** 图标,然后在弹窗中修改服务商、模型名称、API 密钥等信息。 |
| 2 | 删除模型 | 点击 **删除** 图标,然后在弹窗中二次确认。删除后,当前模型将被从列表里移除,不可被继续使用。 |
| 3 | 启用/禁用模型 | 若你不希望删除模型,但在一段时间内无需使用这个模型,你可以禁用该模型。被禁用的模型将保留在设置页面的列表中,但不会出现在 AI 对话框的模型选择列表中。 |
# translate.js
Source: https://docs.siliconflow.cn/cn/usercases/use-siliconcloud-in-translate-js
## 简介
[translate.js](https://gitee.com/mail_osc/translate) 是面向前端开发者的 AI i18n
专注于多语言切换能力,两行 js 实现 html 全自动翻译,百多语种一键切换,无需改动页面、无语言配置文件、支持[几十个微调扩展指令](https://gitee.com/mail_osc/translate),满足你的一切个性化需求、对 SEO 友好。
采用 MIT 协议进行开源: [GitHub](https://github.com/xnx3/translate) | [Gitee](https://gitee.com/mail_osc/translate) ,完全免费开放并允许商业使用。
本文将详细介绍依靠 [硅基流动](https://cloud.siliconflow.cn/i/64MyJQtM) 提供的 API 服务,让你的网站支持上百语种切换。
 ## 模型优化
提到翻译,可能你第一时间想到的这种情景:输入框输入一段文字,后面跟上一句 : 帮我翻译为 xxx 语言 ,它并不是这样的。
大模型有比传统机器翻译更好的译文质量,但稳定可靠的结果输出是线上场景是必须要具备的,它对大(小)模型在文本翻译领域的实际应用场景应用使用进行了深度调优及多重自检修复,以达到稳定可用的能力。展开聊聊见 [这里](https://e.gitee.com/leimingyun/doc/share/6d69716d52be98f0/?sub_id=14253611#%E6%A8%A1%E5%9E%8B%E4%BC%98%E5%8C%96)。
简单来说,就是可以通过 [SiliconCloud](https://cloud.siliconflow.cn/i/64MyJQtM) ,来对各种不规则的句子、多语种混合的句子、前后各种不通顺的句子进行翻译,进行翻译,质量比传统文本翻译的阅读通顺度跟高,同时还能达到传统文本翻译的极速响应。
## 快速使用
您无需做任何前提准备,各种注册等,只需加入几行 js 就能完成
### 代码
只需在你原本的 html**底部**增加以下代码,即可完成接入
```
```
### 说明
只需要 js 加入 `translate.service.use('siliconflow');` 即可使用 [硅基流动](https://cloud.siliconflow.cn/i/64MyJQtM) 免费的 qwen3-8b 模型来进行翻译,我们已对硅基流动进行了深度集成,所以你无需其他任何设置。
translate.js由 [指点云](https://www.zhidianyun.cn/?i125cc1) 提供服务器赞助支持,将大模型转化为文本翻译 API 并开放给 translate.js 进行使用,亚、欧、美洲等都有网络节点以支持全球范围的网络使用畅通。
如果您接入时遇到困难,可[点此反馈求助](https://gitee.com/mail_osc/translate/issues),或加 QQ 群(1034085260)向作者求助。
### 微调指令
translate.js 有极其丰富的扩展指令,让你可以对它进行各种精准控制,满足各种难缠客户的各种脑洞要求。(如果满足不了,可通过上方 QQ 群提出来我们加) 比如:
[切换语言select选择框的位置、CSS美化、是否出现、显示的语种等](https://translate.zvo.cn/41541.html)、[设置默认翻译为什么语种进行显示](http://translate.zvo.cn/4071.html)、[自定义翻译术语](http://translate.zvo.cn/41555.html)、[翻译完后自动触发执行](http://translate.zvo.cn/4069.html)、[指定私有部署的翻译服务接口](http://translate.zvo.cn/4068.html)、[监控页面动态渲染的文本进行自动翻译](http://translate.zvo.cn/4067.html)、[自动切换为用户所使用的语种](http://translate.zvo.cn/4065.html)、[用js控制主动进行语言切换](http://translate.zvo.cn/4064.html)、[只翻译指定的元素](http://translate.zvo.cn/4063.html)、[翻译时忽略指定的元素](http://translate.zvo.cn/4061.html)、[翻译时忽略指定的文字不翻译](http://translate.zvo.cn/283381.html)、[对网页中图片进行翻译](http://translate.zvo.cn/4055.html)、[鼠标划词翻译](http://translate.zvo.cn/4072.html)、[网页ajax请求触发自动翻译](http://translate.zvo.cn/4086.html)、[设置只对指定语种进行翻译](http://translate.zvo.cn/4085.html)、[对指定标签的属性进行翻译](http://translate.zvo.cn/231504.html) ……
更多指令及其说明可 [点此查看](https://gitee.com/mail_osc/translate).
## 使用 SiliconCloud 实现私有部署
您可以注册 [SiliconCloud](https://cloud.siliconflow.cn/i/64MyJQtM) 自己的账号,然后私有部署此服务,来进行更多设定,极大提升使用体验。
### 优势
* **翻译质量**:你可以对接 [硅基流动](https://cloud.siliconflow.cn/i/64MyJQtM) 更大尺寸的模型,比如 qwen3-32B,让翻译语句更通顺,拥有极高的阅读体验。
* **极速响应**:可开启 [内存缓存](https://translate.zvo.cn/391130.html) 来极大提高文本翻译 API 的响应速度
* **用量限制**:可针对某个域名(或者开通 API 接口的 key)来设定它的 [用量限制](https://translate.zvo.cn/391130.html) ,如果你是网络公司,你可以以套餐的形式卖给使用用户。
* **管理接口**:可以通过开放的 [管理 API 接口](https://doc.zvo.cn/translate.service/20250312/admin.getCache.json.html) ,来实时获取当前有哪些域名(或 key)在使用、翻译的字符数有多少、等等。
* **数据隐私**:接口请求、缓存数据等完全都在自己的服务器上,数据隐私无需担忧。
* **并发控制**:可自由定义每秒的[并发请求上限](https://translate.zvo.cn/413975.html),以及调用大模型进行翻译时[请求线程池](https://translate.zvo.cn/391753.html)的线程上限,以极大缩减接口等待的耗时。另还可以通过管理接口实时获取当前请求线程池的并发数等
### 部署
#### 1. 服务器规格
* **CPU** :1 核
* **架构** :x86\_64 (也就是 Intel 的 CPU )
* **内存** :1G
* **操作系统** :
1. CentOS 7.4 (这个版本没有可选 7.6 、7.2 等,7.x 系列的都可以)
2. openEulor 20 (如果没有 20 版本那就选 22 版本)
* **系统盘** :默认的系统盘即可,无需数据盘
* **弹性公网 IP** :按流量计费(带宽大小 10MB。如果是个人使用,翻译的量不大,完全可以选 1MB 带宽)
* **所在区域** : 选国内,这样请求硅基流动接口就会更快。
其他没提到的,都按照便宜的来即可。
#### 2. 一键部署
执行以下 shell 命令进行一键部署:
```
yum -y install wget && wget https://raw.githubusercontent.com/xnx3/translate/refs/heads/master/deploy/service.sh -O ~/install.sh && chmod -R 777 ~/install.sh && sh ~/install.sh
```
#### 3. 获取 API 密钥
1. 进入 [硅基流动](https://cloud.siliconflow.cn/i/64MyJQtM) 注册账号
2. 在控制台的左侧,找到 **账户管理** 下的 **API 密钥** ,点开,去新建一个即可。
## 模型优化
提到翻译,可能你第一时间想到的这种情景:输入框输入一段文字,后面跟上一句 : 帮我翻译为 xxx 语言 ,它并不是这样的。
大模型有比传统机器翻译更好的译文质量,但稳定可靠的结果输出是线上场景是必须要具备的,它对大(小)模型在文本翻译领域的实际应用场景应用使用进行了深度调优及多重自检修复,以达到稳定可用的能力。展开聊聊见 [这里](https://e.gitee.com/leimingyun/doc/share/6d69716d52be98f0/?sub_id=14253611#%E6%A8%A1%E5%9E%8B%E4%BC%98%E5%8C%96)。
简单来说,就是可以通过 [SiliconCloud](https://cloud.siliconflow.cn/i/64MyJQtM) ,来对各种不规则的句子、多语种混合的句子、前后各种不通顺的句子进行翻译,进行翻译,质量比传统文本翻译的阅读通顺度跟高,同时还能达到传统文本翻译的极速响应。
## 快速使用
您无需做任何前提准备,各种注册等,只需加入几行 js 就能完成
### 代码
只需在你原本的 html**底部**增加以下代码,即可完成接入
```
```
### 说明
只需要 js 加入 `translate.service.use('siliconflow');` 即可使用 [硅基流动](https://cloud.siliconflow.cn/i/64MyJQtM) 免费的 qwen3-8b 模型来进行翻译,我们已对硅基流动进行了深度集成,所以你无需其他任何设置。
translate.js由 [指点云](https://www.zhidianyun.cn/?i125cc1) 提供服务器赞助支持,将大模型转化为文本翻译 API 并开放给 translate.js 进行使用,亚、欧、美洲等都有网络节点以支持全球范围的网络使用畅通。
如果您接入时遇到困难,可[点此反馈求助](https://gitee.com/mail_osc/translate/issues),或加 QQ 群(1034085260)向作者求助。
### 微调指令
translate.js 有极其丰富的扩展指令,让你可以对它进行各种精准控制,满足各种难缠客户的各种脑洞要求。(如果满足不了,可通过上方 QQ 群提出来我们加) 比如:
[切换语言select选择框的位置、CSS美化、是否出现、显示的语种等](https://translate.zvo.cn/41541.html)、[设置默认翻译为什么语种进行显示](http://translate.zvo.cn/4071.html)、[自定义翻译术语](http://translate.zvo.cn/41555.html)、[翻译完后自动触发执行](http://translate.zvo.cn/4069.html)、[指定私有部署的翻译服务接口](http://translate.zvo.cn/4068.html)、[监控页面动态渲染的文本进行自动翻译](http://translate.zvo.cn/4067.html)、[自动切换为用户所使用的语种](http://translate.zvo.cn/4065.html)、[用js控制主动进行语言切换](http://translate.zvo.cn/4064.html)、[只翻译指定的元素](http://translate.zvo.cn/4063.html)、[翻译时忽略指定的元素](http://translate.zvo.cn/4061.html)、[翻译时忽略指定的文字不翻译](http://translate.zvo.cn/283381.html)、[对网页中图片进行翻译](http://translate.zvo.cn/4055.html)、[鼠标划词翻译](http://translate.zvo.cn/4072.html)、[网页ajax请求触发自动翻译](http://translate.zvo.cn/4086.html)、[设置只对指定语种进行翻译](http://translate.zvo.cn/4085.html)、[对指定标签的属性进行翻译](http://translate.zvo.cn/231504.html) ……
更多指令及其说明可 [点此查看](https://gitee.com/mail_osc/translate).
## 使用 SiliconCloud 实现私有部署
您可以注册 [SiliconCloud](https://cloud.siliconflow.cn/i/64MyJQtM) 自己的账号,然后私有部署此服务,来进行更多设定,极大提升使用体验。
### 优势
* **翻译质量**:你可以对接 [硅基流动](https://cloud.siliconflow.cn/i/64MyJQtM) 更大尺寸的模型,比如 qwen3-32B,让翻译语句更通顺,拥有极高的阅读体验。
* **极速响应**:可开启 [内存缓存](https://translate.zvo.cn/391130.html) 来极大提高文本翻译 API 的响应速度
* **用量限制**:可针对某个域名(或者开通 API 接口的 key)来设定它的 [用量限制](https://translate.zvo.cn/391130.html) ,如果你是网络公司,你可以以套餐的形式卖给使用用户。
* **管理接口**:可以通过开放的 [管理 API 接口](https://doc.zvo.cn/translate.service/20250312/admin.getCache.json.html) ,来实时获取当前有哪些域名(或 key)在使用、翻译的字符数有多少、等等。
* **数据隐私**:接口请求、缓存数据等完全都在自己的服务器上,数据隐私无需担忧。
* **并发控制**:可自由定义每秒的[并发请求上限](https://translate.zvo.cn/413975.html),以及调用大模型进行翻译时[请求线程池](https://translate.zvo.cn/391753.html)的线程上限,以极大缩减接口等待的耗时。另还可以通过管理接口实时获取当前请求线程池的并发数等
### 部署
#### 1. 服务器规格
* **CPU** :1 核
* **架构** :x86\_64 (也就是 Intel 的 CPU )
* **内存** :1G
* **操作系统** :
1. CentOS 7.4 (这个版本没有可选 7.6 、7.2 等,7.x 系列的都可以)
2. openEulor 20 (如果没有 20 版本那就选 22 版本)
* **系统盘** :默认的系统盘即可,无需数据盘
* **弹性公网 IP** :按流量计费(带宽大小 10MB。如果是个人使用,翻译的量不大,完全可以选 1MB 带宽)
* **所在区域** : 选国内,这样请求硅基流动接口就会更快。
其他没提到的,都按照便宜的来即可。
#### 2. 一键部署
执行以下 shell 命令进行一键部署:
```
yum -y install wget && wget https://raw.githubusercontent.com/xnx3/translate/refs/heads/master/deploy/service.sh -O ~/install.sh && chmod -R 777 ~/install.sh && sh ~/install.sh
```
#### 3. 获取 API 密钥
1. 进入 [硅基流动](https://cloud.siliconflow.cn/i/64MyJQtM) 注册账号
2. 在控制台的左侧,找到 **账户管理** 下的 **API 密钥** ,点开,去新建一个即可。
 #### 4. 配置 API 密钥
首先,找到配置文件 /mnt/service/config.properties 编辑它,找到
```
translate.service.leimingyun.domain=http://api.translate.zvo.cn
```
这个,将它注释掉(这个是默认体验的),然后增加以下配置:
```
# 这个url固定填写,无需改动
translate.service.openai.url=https://api.siliconflow.cn/v1/chat/completions
# 使用哪个大模型。比如你这里可以填写 Qwen/Qwen3-32B , 具体模型可以通过 https://cloud.siliconflow.cn/models 获得
translate.service.openai.model=Qwen/Qwen3-32B
# 硅基流动的 API 密钥,你上一步获取到的,填到这里
translate.service.openai.key=sk-kqpnpfhlikgacrmdab2946d28eb00ede7acd9b3axfiIadf4P81
# 进行大模型API调用线程池的程数。不懂可设置100即可。此参数的具体说明可参考 http://translate.zvo.cn/396728.html
translate.service.thread.number=100
```
当然,还有更多的配置方式可以解锁更高的能力,这些刚部署初期你可以忽略,熟悉了可以研究:
* [翻译精准度效验及自动修复](https://translate.zvo.cn/411064.html)
* [配置多翻译通道支持的语种分流策略](https://translate.zvo.cn/426176.html)
* [配置翻译API接口的流量控制](https://translate.zvo.cn/413975.html)
* [配置备用翻译通道](https://translate.zvo.cn/404947.html)
* ...
#### 5. 重启项目
操作完毕后,重启 translate.service 服务,执行重启命令 :
```
/mnt/service/start.sh
```
#### 6. 访问测试
直接访问你的服务器 ip,即可看到效果:
#### 4. 配置 API 密钥
首先,找到配置文件 /mnt/service/config.properties 编辑它,找到
```
translate.service.leimingyun.domain=http://api.translate.zvo.cn
```
这个,将它注释掉(这个是默认体验的),然后增加以下配置:
```
# 这个url固定填写,无需改动
translate.service.openai.url=https://api.siliconflow.cn/v1/chat/completions
# 使用哪个大模型。比如你这里可以填写 Qwen/Qwen3-32B , 具体模型可以通过 https://cloud.siliconflow.cn/models 获得
translate.service.openai.model=Qwen/Qwen3-32B
# 硅基流动的 API 密钥,你上一步获取到的,填到这里
translate.service.openai.key=sk-kqpnpfhlikgacrmdab2946d28eb00ede7acd9b3axfiIadf4P81
# 进行大模型API调用线程池的程数。不懂可设置100即可。此参数的具体说明可参考 http://translate.zvo.cn/396728.html
translate.service.thread.number=100
```
当然,还有更多的配置方式可以解锁更高的能力,这些刚部署初期你可以忽略,熟悉了可以研究:
* [翻译精准度效验及自动修复](https://translate.zvo.cn/411064.html)
* [配置多翻译通道支持的语种分流策略](https://translate.zvo.cn/426176.html)
* [配置翻译API接口的流量控制](https://translate.zvo.cn/413975.html)
* [配置备用翻译通道](https://translate.zvo.cn/404947.html)
* ...
#### 5. 重启项目
操作完毕后,重启 translate.service 服务,执行重启命令 :
```
/mnt/service/start.sh
```
#### 6. 访问测试
直接访问你的服务器 ip,即可看到效果:
 随便选个语种切换一下试试,切换后“你好,世界”能被翻译,说明已接入成功,可以正常使用了。
### 使用
#### 文本翻译 API 接口
它以 [硅基流动](https://cloud.siliconflow.cn/i/64MyJQtM) 平台的大模型算力作为基础支撑,通过 [translate.service](https://gitee.com/mail_osc/translate) 作为中间调度。
你完全不需要去了解 大模型 是什么以及怎么使用,给你暴露出标准的API翻译接口进行使用。
**请求 URL** :[http://你的服务器 ip/translate.json](http://api.zvo.cn/translate/service/20230807/translate.json.html)
**请求方式** :POST
**请求方式** :POST
**请求参数** :
* **to** 将文本翻译为什么语种。可传入如 english 更多语种可访问 [http://你服务器的 ip/language.json](http://api.zvo.cn/translate/service/20230807/language.json.html) 就能看到
* **text** 需要翻译的语言。格式如 `["你好","世界"]` 它是 json 数组格式,支持一次翻译多个不同的文本,每个文本可以分别是不同的语言。
**响应示例** :
`{"result":1,"info":"success","to":"english","text":["Hello","World"]}`
注意,header 头的 Content-Type 要么不设置,如果设置的话值是 application/x-www-form-urlencoded
**curl 翻译示例:**
为了方便理解上面的 API 接口使用,这里给出了一个 curl 请求的示例,另外这个示例你也可以直接复制就能运行使用,看到效果
```
curl --request POST \
--url https://siliconflow.zvo.cn/translate.json \
--header 'content-type: application/x-www-form-urlencoded' \
--data to=english \
--data 'text=["你好,世界","让我们探索星辰大海"]'
```
它是开放的,你不需要再去买高额的文本翻译了,硅基流动给你提供免费的,翻译通顺度还更高!
[可点此查看有关文本翻译API接口的详细文档](http://api.zvo.cn/translate/service/20230807/translate.json.html)
#### 网页多语言切换
使用方式为,在网页最末尾,html 结束之前,加入以下代码,一般在页面的最底部就出现了选择语言的 select 切换标签,你可以点击切换语言试试切换效果
```
```
如此,翻译请求接口就会走您自己服务器了。有关这个手动指定翻译接口的详细说明,可参考: [http://translate.zvo.cn/4068.html](https://gitee.com/link?target=http%3A%2F%2Ftranslate.zvo.cn%2F4068.html)
另外 translate.js 这个 js 文件你可以自己下载下来放到你自己项目里使用,它没有任何别的依赖,是标准的原生 JavaScript 。而且 translate.js 是完全开源的,你可以从 [https://raw.githubusercontent.com/xnx3/translate/refs/heads/master/translate.js/translate.js](https://gitee.com/link?target=https%3A%2F%2Fraw.githubusercontent.com%2Fxnx3%2Ftranslate%2Frefs%2Fheads%2Fmaster%2Ftranslate.js%2Ftranslate.js) 下载最新的 js,放到你项目里进行使用。
他的原理是直接扫描你网页的 dom 元素进行自动分析识别,然后将文本集中化进行翻译。也就是你要讲这个 translate.execute(); 这行要放在最底部,就是因为上面的渲染完了在执行它,可以直接触发整个页面的翻译。
### 日志查看
你可以从服务器中查看相关日志情况。
日志存放于 /mnt/service/logs/ 目录下
#### 文本翻译日志
openai\_yyyy-MM-dd.log 是硅基流动通过openai接口调用大模型进行文本翻译的日志
比如: `openai_2025-05-17.log`
yyyy-MM-dd 是当前的年月日,它按照日期每天都会创建一个日志文件。
它记录了你所有文本翻译的原文、译文、进行时间、翻译结果审查得分、是否启用了修复机制 等
它每行都是一个文本翻译记录。
示例:
```
{"time":"00:40:59","originalText":"按钮切换语言:","resultText":"Button switch language:","to":"english","useTime":583,"score":96}
{"time":"00:40:59","originalText":"语言切换示例:","resultText":"Language Switching Example:","to":"english","useTime":482,"score":96}
{"time":"00:40:59","originalText":"你好","resultText":"Hello","to":"english","useTime":546,"score":96}
```
* **time** 发生时间
* **originalText** 翻译的原文
* **resultText** 翻译的译文
* **to** 翻译为什么语种
* **score** 对译文进行校验后的打分。 1\~100 分,分数越高表示翻译越精准
* **useTime** 当前使用[SiliconCloud](https://cloud.siliconflow.cn/i/64MyJQtM)翻译的耗时,单位是毫秒
#### 系统运行日志
translate.service.log 是系统运行日志,它存放 translate.service 本身的运行情况的日志
#### 访问请求日志
request\_yyyy-MM-dd.log 是进行翻译请求(/translate.json)的请求日志。\
它并不是你访问后它就会立即产生日志,而是它有一个日志缓冲,比如当日志达到几百条、或者距离上次将其保存到日志文件超过 2 分钟,它才会进行将日志信息打包写入到日志文件中。
这里列出其中两条示例:
```
{"method":"translate.json","size":4,"ip":"192.168.31.95","domain":"192.168.31.95","memoryCacheHitsSize":5,"time":"2025-03-19 10:22:56","memoryCacheHitsNumber":1,"to":"english"}
{"fileCache":"1845bbcbd9e600fab184b346d82042a9_english.txt","method":"translate.json","size":4,"ip":"192.168.31.95","domain":"192.168.31.95","time":"2025-03-19 10:26:56","to":"english"}
```
* **method** 当前请求的是哪个接口。比如 translate.json 则是请求的文本翻译 API 接口; language.json 则是请求的获取当前所支持的语言列表接口
* **fileCache** 针对 translate.json 翻译接口的请求,如果有命中文件缓存,则有这个参数,其值是 文件缓存的名字,它是在 `/mnt/service/cache/` 内的
* **originalSize** 针对 translate.json 翻译接口的请求,记录当前翻译的字符数(原文的字符数,非译文)
* **size** 针对 translate.json 翻译接口的请求,记录当前翻译的字符数(译文的字符数,非原文)
* **ip** 请求来源的 ip
* **domain** 针对 translate.json 翻译接口的请求,如果是网站使用了 translate.js ,那这个则是这个网站的域名(它是自动获取到的)
* **time** 触发的时间
* **to** 针对 translate.json 翻译接口的请求,翻译为什么语种
* **key** 针对 translate.json 翻译接口的请求,如果是你给对方通过 domain.json 配置设置的文本翻译 key,那这个就是记录的 key。
* **memoryCacheHitsNumber** 针对 translate.json 翻译接口的请求,如果有命中内存缓存,这里是记录命中内存缓存的条数(translate.json 支持同时翻译多条)
* **memoryCacheHitsSize** 针对 translate.json 翻译接口的请求,如果有命中内存缓存,这里是记录命中内存缓存的字符数(译文的字符数,非原文)
# Tyrion
Source: https://docs.siliconflow.cn/cn/usercases/use-siliconcloud-in-tyrion
[Tyrion.ai](https://www.tyrion.ai) 一站式企业复合 AI 系统平台,融合生成式 AI、大语言模型智能体(Agent)与知识本体语义层打造统一的 AI 中枢,帮助大型企业实现跨业务的智能自动化与决策支持。平台低代码开发界面、基于大语言模型(LLM),支持快速构建 AI Agent,可视化工作流编排和智能知识库,打造高效协同的一体化产品矩阵。
本文将介绍如何在 Tyrion 中使用 SiliconFlow 提供的模型能力。
## 配置 SiliconFlow 模型
进入设置中的模型管理页面,点击 SiliconFlow 设置按钮,在编辑模型组窗口中点击**从 SiliconFlow 获取 API Key** 按钮,Tyrion 会打开相应配置页面,点击密钥复制并在 **API Key** 中粘贴,点击确认即可完成配置。
随便选个语种切换一下试试,切换后“你好,世界”能被翻译,说明已接入成功,可以正常使用了。
### 使用
#### 文本翻译 API 接口
它以 [硅基流动](https://cloud.siliconflow.cn/i/64MyJQtM) 平台的大模型算力作为基础支撑,通过 [translate.service](https://gitee.com/mail_osc/translate) 作为中间调度。
你完全不需要去了解 大模型 是什么以及怎么使用,给你暴露出标准的API翻译接口进行使用。
**请求 URL** :[http://你的服务器 ip/translate.json](http://api.zvo.cn/translate/service/20230807/translate.json.html)
**请求方式** :POST
**请求方式** :POST
**请求参数** :
* **to** 将文本翻译为什么语种。可传入如 english 更多语种可访问 [http://你服务器的 ip/language.json](http://api.zvo.cn/translate/service/20230807/language.json.html) 就能看到
* **text** 需要翻译的语言。格式如 `["你好","世界"]` 它是 json 数组格式,支持一次翻译多个不同的文本,每个文本可以分别是不同的语言。
**响应示例** :
`{"result":1,"info":"success","to":"english","text":["Hello","World"]}`
注意,header 头的 Content-Type 要么不设置,如果设置的话值是 application/x-www-form-urlencoded
**curl 翻译示例:**
为了方便理解上面的 API 接口使用,这里给出了一个 curl 请求的示例,另外这个示例你也可以直接复制就能运行使用,看到效果
```
curl --request POST \
--url https://siliconflow.zvo.cn/translate.json \
--header 'content-type: application/x-www-form-urlencoded' \
--data to=english \
--data 'text=["你好,世界","让我们探索星辰大海"]'
```
它是开放的,你不需要再去买高额的文本翻译了,硅基流动给你提供免费的,翻译通顺度还更高!
[可点此查看有关文本翻译API接口的详细文档](http://api.zvo.cn/translate/service/20230807/translate.json.html)
#### 网页多语言切换
使用方式为,在网页最末尾,html 结束之前,加入以下代码,一般在页面的最底部就出现了选择语言的 select 切换标签,你可以点击切换语言试试切换效果
```
```
如此,翻译请求接口就会走您自己服务器了。有关这个手动指定翻译接口的详细说明,可参考: [http://translate.zvo.cn/4068.html](https://gitee.com/link?target=http%3A%2F%2Ftranslate.zvo.cn%2F4068.html)
另外 translate.js 这个 js 文件你可以自己下载下来放到你自己项目里使用,它没有任何别的依赖,是标准的原生 JavaScript 。而且 translate.js 是完全开源的,你可以从 [https://raw.githubusercontent.com/xnx3/translate/refs/heads/master/translate.js/translate.js](https://gitee.com/link?target=https%3A%2F%2Fraw.githubusercontent.com%2Fxnx3%2Ftranslate%2Frefs%2Fheads%2Fmaster%2Ftranslate.js%2Ftranslate.js) 下载最新的 js,放到你项目里进行使用。
他的原理是直接扫描你网页的 dom 元素进行自动分析识别,然后将文本集中化进行翻译。也就是你要讲这个 translate.execute(); 这行要放在最底部,就是因为上面的渲染完了在执行它,可以直接触发整个页面的翻译。
### 日志查看
你可以从服务器中查看相关日志情况。
日志存放于 /mnt/service/logs/ 目录下
#### 文本翻译日志
openai\_yyyy-MM-dd.log 是硅基流动通过openai接口调用大模型进行文本翻译的日志
比如: `openai_2025-05-17.log`
yyyy-MM-dd 是当前的年月日,它按照日期每天都会创建一个日志文件。
它记录了你所有文本翻译的原文、译文、进行时间、翻译结果审查得分、是否启用了修复机制 等
它每行都是一个文本翻译记录。
示例:
```
{"time":"00:40:59","originalText":"按钮切换语言:","resultText":"Button switch language:","to":"english","useTime":583,"score":96}
{"time":"00:40:59","originalText":"语言切换示例:","resultText":"Language Switching Example:","to":"english","useTime":482,"score":96}
{"time":"00:40:59","originalText":"你好","resultText":"Hello","to":"english","useTime":546,"score":96}
```
* **time** 发生时间
* **originalText** 翻译的原文
* **resultText** 翻译的译文
* **to** 翻译为什么语种
* **score** 对译文进行校验后的打分。 1\~100 分,分数越高表示翻译越精准
* **useTime** 当前使用[SiliconCloud](https://cloud.siliconflow.cn/i/64MyJQtM)翻译的耗时,单位是毫秒
#### 系统运行日志
translate.service.log 是系统运行日志,它存放 translate.service 本身的运行情况的日志
#### 访问请求日志
request\_yyyy-MM-dd.log 是进行翻译请求(/translate.json)的请求日志。\
它并不是你访问后它就会立即产生日志,而是它有一个日志缓冲,比如当日志达到几百条、或者距离上次将其保存到日志文件超过 2 分钟,它才会进行将日志信息打包写入到日志文件中。
这里列出其中两条示例:
```
{"method":"translate.json","size":4,"ip":"192.168.31.95","domain":"192.168.31.95","memoryCacheHitsSize":5,"time":"2025-03-19 10:22:56","memoryCacheHitsNumber":1,"to":"english"}
{"fileCache":"1845bbcbd9e600fab184b346d82042a9_english.txt","method":"translate.json","size":4,"ip":"192.168.31.95","domain":"192.168.31.95","time":"2025-03-19 10:26:56","to":"english"}
```
* **method** 当前请求的是哪个接口。比如 translate.json 则是请求的文本翻译 API 接口; language.json 则是请求的获取当前所支持的语言列表接口
* **fileCache** 针对 translate.json 翻译接口的请求,如果有命中文件缓存,则有这个参数,其值是 文件缓存的名字,它是在 `/mnt/service/cache/` 内的
* **originalSize** 针对 translate.json 翻译接口的请求,记录当前翻译的字符数(原文的字符数,非译文)
* **size** 针对 translate.json 翻译接口的请求,记录当前翻译的字符数(译文的字符数,非原文)
* **ip** 请求来源的 ip
* **domain** 针对 translate.json 翻译接口的请求,如果是网站使用了 translate.js ,那这个则是这个网站的域名(它是自动获取到的)
* **time** 触发的时间
* **to** 针对 translate.json 翻译接口的请求,翻译为什么语种
* **key** 针对 translate.json 翻译接口的请求,如果是你给对方通过 domain.json 配置设置的文本翻译 key,那这个就是记录的 key。
* **memoryCacheHitsNumber** 针对 translate.json 翻译接口的请求,如果有命中内存缓存,这里是记录命中内存缓存的条数(translate.json 支持同时翻译多条)
* **memoryCacheHitsSize** 针对 translate.json 翻译接口的请求,如果有命中内存缓存,这里是记录命中内存缓存的字符数(译文的字符数,非原文)
# Tyrion
Source: https://docs.siliconflow.cn/cn/usercases/use-siliconcloud-in-tyrion
[Tyrion.ai](https://www.tyrion.ai) 一站式企业复合 AI 系统平台,融合生成式 AI、大语言模型智能体(Agent)与知识本体语义层打造统一的 AI 中枢,帮助大型企业实现跨业务的智能自动化与决策支持。平台低代码开发界面、基于大语言模型(LLM),支持快速构建 AI Agent,可视化工作流编排和智能知识库,打造高效协同的一体化产品矩阵。
本文将介绍如何在 Tyrion 中使用 SiliconFlow 提供的模型能力。
## 配置 SiliconFlow 模型
进入设置中的模型管理页面,点击 SiliconFlow 设置按钮,在编辑模型组窗口中点击**从 SiliconFlow 获取 API Key** 按钮,Tyrion 会打开相应配置页面,点击密钥复制并在 **API Key** 中粘贴,点击确认即可完成配置。

 ## 在流程中使用 SiliconFlow 模型
在模型分组下拉框中选择 **SiliconFlow**,完成提示词的编写等配置后,便可以体验 SiliconFlow 提供的强大的模型能力。
## 在流程中使用 SiliconFlow 模型
在模型分组下拉框中选择 **SiliconFlow**,完成提示词的编写等配置后,便可以体验 SiliconFlow 提供的强大的模型能力。

 # 问道
Source: https://docs.siliconflow.cn/cn/usercases/use-siliconcloud-in-wendao
## 1、关于问道
[问道](https://wendao.aihub.ren)是一个 AI 聊天平台,以“问道”为主题,预设道家人物角色(如老子、庄子等)作为交互对象。用户可通过对话形式与“道家先贤”互动,探索道家思想,兼具文化传播与智能交流功能。
平台对话服务基于 [硅基流动](https://cloud.siliconflow.cn/) API ,本文将介绍如何在网站中使用 **硅基流动** 提供的 API 服务。
## 2、获取 API 密钥
> 建议设置你自己的硅基流动API 密钥,将会优先调用。若不设置,将使用内置硅基流动密钥(使用人数多时,可能会有速率限制)。
1. 打开硅基流动 [官网](https://cloud.siliconflow.cn/) 并注册账号(如果注册过,直接登录即可)。
2. 完成注册后,打开 [API 密钥](https://cloud.siliconflow.cn/account/ak) ,点击 **新建 API 密钥**,点击密钥进行复制,以备后续使用。
# 问道
Source: https://docs.siliconflow.cn/cn/usercases/use-siliconcloud-in-wendao
## 1、关于问道
[问道](https://wendao.aihub.ren)是一个 AI 聊天平台,以“问道”为主题,预设道家人物角色(如老子、庄子等)作为交互对象。用户可通过对话形式与“道家先贤”互动,探索道家思想,兼具文化传播与智能交流功能。
平台对话服务基于 [硅基流动](https://cloud.siliconflow.cn/) API ,本文将介绍如何在网站中使用 **硅基流动** 提供的 API 服务。
## 2、获取 API 密钥
> 建议设置你自己的硅基流动API 密钥,将会优先调用。若不设置,将使用内置硅基流动密钥(使用人数多时,可能会有速率限制)。
1. 打开硅基流动 [官网](https://cloud.siliconflow.cn/) 并注册账号(如果注册过,直接登录即可)。
2. 完成注册后,打开 [API 密钥](https://cloud.siliconflow.cn/account/ak) ,点击 **新建 API 密钥**,点击密钥进行复制,以备后续使用。
 ## 3、在平台使用
1、[问道](https://wendao.aihub.ren) 首页选择任一人物卡片,进入对话框后点击右上角 **太极八卦图标**,打开 **设置框**,API Key 处填入刚刚复制的 API 密钥。API 地址和模型名称、温度也可根据需求自定义。设置完成后,点击 **保存设置** 生效。
## 3、在平台使用
1、[问道](https://wendao.aihub.ren) 首页选择任一人物卡片,进入对话框后点击右上角 **太极八卦图标**,打开 **设置框**,API Key 处填入刚刚复制的 API 密钥。API 地址和模型名称、温度也可根据需求自定义。设置完成后,点击 **保存设置** 生效。

 2、在老子、庄子独立页面使用:点击首页“太上”、“逍遥”进入对应页面,点击对话框右上角 “**枢**” 字按钮弹出设置,在设置框中填入 API 密钥。
2、在老子、庄子独立页面使用:点击首页“太上”、“逍遥”进入对应页面,点击对话框右上角 “**枢**” 字按钮弹出设置,在设置框中填入 API 密钥。
 3、完成配置后,直接在对话框进行对话使用即可。更多页面功能可自行探索。
# wiseflow AI 首席情报官
Source: https://docs.siliconflow.cn/cn/usercases/use-siliconcloud-in-wiseflow
## 关于 wiseflow
[wiseflow](https://github.com/TeamWiseFlow/wiseflow/)(中文名:AI 首席情报官)是一款利用大模型帮用户每日从海量信息、各类信源中挖掘真正感兴趣信息的开源应用。
与 ChatGPT、Manus 等 **'deep search'** 类应用不同,wiseflow 定位于 **'wide search'**,特别适合行业情报、客户信息、招投标信息、竞对动态、舆情监控以及知识情报等需要信息“广度”收集的场景。而相对于传统的 RPA 类爬虫,项目又支持免手工提取 xpath 的“开箱即用"模式,并使用大模型对每条信息严格根据用户设定的关注点进行分析、过滤和总结。
wiseflow 刚刚发布了全新的 4.0 版本,在已有的普通网页、rss 和搜索引擎信源基础上,增加提供了对微博和快手平台的支持,4.x 后续版本还将陆续提供对微信公众号平台、抖音、小红书、b 站以及知乎平台的支持。4.0 版本还对程序架构进行了比较大的重构,运行起来更加稳定、更加快速,同时对内存更加友好。
## 使用方法
**wiseflow 自 3.1 版本开始一直推荐使用 SiliconFlow 提供的 llm 服务,4.0 版本对比 3.x 进一步简化了操作步骤,只需三步即可开始使用!**
温馨提示:windows 用户请提前下载 git bash 工具,并在 bash 中执行如下命令 [bash下载链接](https://git-scm.com/downloads/win)
### 下载项目源代码并安装 uv 和 pocketbase
```Plain
curl -LsSf https://astral.sh/uv/install.sh | sh
git clone https://github.com/TeamWiseFlow/wiseflow.git
```
上述操作会完成 uv 的安装。
接下来去 [pocketbase docs](https://pocketbase.io/docs/) 下载对应自己系统的 pocketbase 程序并放置于 wiseflow/pb 文件夹下。
注意,使用 MacOS 的小伙伴需要在这一步完成后,去到 wiseflow/pb 文件夹执行一次:
```
xattr -d com.apple.quarantine pocketbase
```
### 参考 env\_sample 配置 .env 文件
先在 wiseflow 文件夹(项目根目录)参考 env\_sample 创建 .env 文件,并填入相关设定信息。
**接下来就要轮到 SiliconFlow 登场了!**
* 进入 SiliconFlow [官网](https://cloud.siliconflow.cn/) 并注册账号(如果注册过,直接登录即可);
* 完成注册后,打开 [API 密钥](https://cloud.siliconflow.cn/account/ak) ,创建新的 API Key;
* 点击密钥进行复制,然后填入上一步创建的 .env 文件的 LLM\_API\_KEY 中,同时将 LLM\_API\_BASE 设置为 [https://api.siliconflow.cn/v1](https://api.siliconflow.cn/v1)
.env 文件最终可以参考如下:
```Python
LLM_API_KEY=你的 API KEY
LLM_API_BASE=https://api.siliconflow.cn/v1 # LLM 服务接口地址
PRIMARY_MODEL=Qwen/Qwen3-14B # 推荐 Qwen3-14B 或同量级思考模型
VL_MODEL=Pro/Qwen/Qwen2.5-VL-7B-Instruct
```
对于 wiseflow 这种“广度信息搜集”任务,Qwen3-14B 模型已经可以实现不错的效果,VL\_MODEL 只是辅助作用。Qwen2.5-VL-7B-Instruct 也可以满足要求,wiseflow 也特别针对小尺寸模型做了优化,当然如果你的关注点涉及大量约束限制条件以及专有名词,也可以选择尺寸更大的 Qwen3-32B 模型。
有关 .env 其他项目的说明可以参考 wiseflow 的 [docs/manual/manual.md](https://github.com/TeamWiseFlow/wiseflow/blob/master/docs/manual/manual.md)
### 起飞!
接下来只需要依次执行如下命令即可
```Bash
cd wiseflow
uv venv # 仅第一次执行需要
source .venv/bin/activate # Linux/macOS#
#或者在 Windows 上:
# .venv\Scripts\activate
uv sync # 仅第一次执行需要
python -m playwright install --with-deps chromium # 仅第一次执行需要
chmod +x run.sh # 仅第一次执行需要
./run.sh
```
项目会自动拉起浏览器,引导你注册并进入使用界面。
# Zadig
Source: https://docs.siliconflow.cn/cn/usercases/use-siliconcloud-in-zadig
[Zadig ](https://www.koderover.com/)是由 KodeRover 公司基于 Kubernetes 研发的自助式云原生 DevOps 平台,源码 100% 开放。Zadig 提供灵活可扩展的工作流支持、多种发布策略编排以及一键安全审核等特性。该平台还支持定制的企业级 XOps 敏捷效能看板,深度集成多种企业级平台,并通过项目模板化批量快速接入,实现数千个服务的一键纳管治理。其主要目标是帮助企业实现产研的数字化转型,使工程师成为创新引擎,并为数字经济的无限价值链接提供支持。
本文主要介绍如何借助 SiliconCloud 提供的 DeepSeek 模型在 Zadig 上进行 AI 环境巡检和 AI 效能巡检。
## 安装 Zadig
* [基于主机快速试用](https://docs.koderover.com/zadig/install/all-in-one/)
* [基于 k8s 正式运维](https://docs.koderover.com/zadig/install/helm-deploy/)
## 获取 API Key
* 打开 [SiliconCloud 官网](https://cloud.siliconflow.cn/) 并注册账号(如果注册过,直接登录即可)。
* 完成注册后,打开[ API 密钥](https://cloud.siliconflow.cn/account/ak) ,创建新的 API Key,点击密钥进行复制,以备后续使用。
## 配置 SiliconCloud 模型
在 Zadig 上,访问 `系统设置` -> `系统集成` -> `AI 服务` ,添加 AI 服务。
3、完成配置后,直接在对话框进行对话使用即可。更多页面功能可自行探索。
# wiseflow AI 首席情报官
Source: https://docs.siliconflow.cn/cn/usercases/use-siliconcloud-in-wiseflow
## 关于 wiseflow
[wiseflow](https://github.com/TeamWiseFlow/wiseflow/)(中文名:AI 首席情报官)是一款利用大模型帮用户每日从海量信息、各类信源中挖掘真正感兴趣信息的开源应用。
与 ChatGPT、Manus 等 **'deep search'** 类应用不同,wiseflow 定位于 **'wide search'**,特别适合行业情报、客户信息、招投标信息、竞对动态、舆情监控以及知识情报等需要信息“广度”收集的场景。而相对于传统的 RPA 类爬虫,项目又支持免手工提取 xpath 的“开箱即用"模式,并使用大模型对每条信息严格根据用户设定的关注点进行分析、过滤和总结。
wiseflow 刚刚发布了全新的 4.0 版本,在已有的普通网页、rss 和搜索引擎信源基础上,增加提供了对微博和快手平台的支持,4.x 后续版本还将陆续提供对微信公众号平台、抖音、小红书、b 站以及知乎平台的支持。4.0 版本还对程序架构进行了比较大的重构,运行起来更加稳定、更加快速,同时对内存更加友好。
## 使用方法
**wiseflow 自 3.1 版本开始一直推荐使用 SiliconFlow 提供的 llm 服务,4.0 版本对比 3.x 进一步简化了操作步骤,只需三步即可开始使用!**
温馨提示:windows 用户请提前下载 git bash 工具,并在 bash 中执行如下命令 [bash下载链接](https://git-scm.com/downloads/win)
### 下载项目源代码并安装 uv 和 pocketbase
```Plain
curl -LsSf https://astral.sh/uv/install.sh | sh
git clone https://github.com/TeamWiseFlow/wiseflow.git
```
上述操作会完成 uv 的安装。
接下来去 [pocketbase docs](https://pocketbase.io/docs/) 下载对应自己系统的 pocketbase 程序并放置于 wiseflow/pb 文件夹下。
注意,使用 MacOS 的小伙伴需要在这一步完成后,去到 wiseflow/pb 文件夹执行一次:
```
xattr -d com.apple.quarantine pocketbase
```
### 参考 env\_sample 配置 .env 文件
先在 wiseflow 文件夹(项目根目录)参考 env\_sample 创建 .env 文件,并填入相关设定信息。
**接下来就要轮到 SiliconFlow 登场了!**
* 进入 SiliconFlow [官网](https://cloud.siliconflow.cn/) 并注册账号(如果注册过,直接登录即可);
* 完成注册后,打开 [API 密钥](https://cloud.siliconflow.cn/account/ak) ,创建新的 API Key;
* 点击密钥进行复制,然后填入上一步创建的 .env 文件的 LLM\_API\_KEY 中,同时将 LLM\_API\_BASE 设置为 [https://api.siliconflow.cn/v1](https://api.siliconflow.cn/v1)
.env 文件最终可以参考如下:
```Python
LLM_API_KEY=你的 API KEY
LLM_API_BASE=https://api.siliconflow.cn/v1 # LLM 服务接口地址
PRIMARY_MODEL=Qwen/Qwen3-14B # 推荐 Qwen3-14B 或同量级思考模型
VL_MODEL=Pro/Qwen/Qwen2.5-VL-7B-Instruct
```
对于 wiseflow 这种“广度信息搜集”任务,Qwen3-14B 模型已经可以实现不错的效果,VL\_MODEL 只是辅助作用。Qwen2.5-VL-7B-Instruct 也可以满足要求,wiseflow 也特别针对小尺寸模型做了优化,当然如果你的关注点涉及大量约束限制条件以及专有名词,也可以选择尺寸更大的 Qwen3-32B 模型。
有关 .env 其他项目的说明可以参考 wiseflow 的 [docs/manual/manual.md](https://github.com/TeamWiseFlow/wiseflow/blob/master/docs/manual/manual.md)
### 起飞!
接下来只需要依次执行如下命令即可
```Bash
cd wiseflow
uv venv # 仅第一次执行需要
source .venv/bin/activate # Linux/macOS#
#或者在 Windows 上:
# .venv\Scripts\activate
uv sync # 仅第一次执行需要
python -m playwright install --with-deps chromium # 仅第一次执行需要
chmod +x run.sh # 仅第一次执行需要
./run.sh
```
项目会自动拉起浏览器,引导你注册并进入使用界面。
# Zadig
Source: https://docs.siliconflow.cn/cn/usercases/use-siliconcloud-in-zadig
[Zadig ](https://www.koderover.com/)是由 KodeRover 公司基于 Kubernetes 研发的自助式云原生 DevOps 平台,源码 100% 开放。Zadig 提供灵活可扩展的工作流支持、多种发布策略编排以及一键安全审核等特性。该平台还支持定制的企业级 XOps 敏捷效能看板,深度集成多种企业级平台,并通过项目模板化批量快速接入,实现数千个服务的一键纳管治理。其主要目标是帮助企业实现产研的数字化转型,使工程师成为创新引擎,并为数字经济的无限价值链接提供支持。
本文主要介绍如何借助 SiliconCloud 提供的 DeepSeek 模型在 Zadig 上进行 AI 环境巡检和 AI 效能巡检。
## 安装 Zadig
* [基于主机快速试用](https://docs.koderover.com/zadig/install/all-in-one/)
* [基于 k8s 正式运维](https://docs.koderover.com/zadig/install/helm-deploy/)
## 获取 API Key
* 打开 [SiliconCloud 官网](https://cloud.siliconflow.cn/) 并注册账号(如果注册过,直接登录即可)。
* 完成注册后,打开[ API 密钥](https://cloud.siliconflow.cn/account/ak) ,创建新的 API Key,点击密钥进行复制,以备后续使用。
## 配置 SiliconCloud 模型
在 Zadig 上,访问 `系统设置` -> `系统集成` -> `AI 服务` ,添加 AI 服务。

 1. 提供商:选择 SiliconCloud
2. 模型名称:输入 SiliconCloud 上提供的模型
3. 访问地址:[https://api.siliconflow.cn/v1](https://api.siliconflow.cn/v1)
4. API Key:上一步中获取的 API Key
## 模型服务使用
### AI 环境巡检
通过 AI 能力全面的分析 和识别 K8s 环境中的问题,比如 Pod 异常、配置错误,并且可以给出解决方案,配置上定时器和 IM 通知,实现定时巡检,及时将问题和解法发送给对应的负责人。
1. 提供商:选择 SiliconCloud
2. 模型名称:输入 SiliconCloud 上提供的模型
3. 访问地址:[https://api.siliconflow.cn/v1](https://api.siliconflow.cn/v1)
4. API Key:上一步中获取的 API Key
## 模型服务使用
### AI 环境巡检
通过 AI 能力全面的分析 和识别 K8s 环境中的问题,比如 Pod 异常、配置错误,并且可以给出解决方案,配置上定时器和 IM 通知,实现定时巡检,及时将问题和解法发送给对应的负责人。

 ### AI 效能洞察
基于 Zadig 上产生的效能数据,AI 辅助分析,可以比较精准的定位项目效能问题,并且给出一定的改进建议,和传统方式相比,传统可能需要手动分析大量数据,而 AI 能在较短的时间内自动生成报告。
### AI 效能洞察
基于 Zadig 上产生的效能数据,AI 辅助分析,可以比较精准的定位项目效能问题,并且给出一定的改进建议,和传统方式相比,传统可能需要手动分析大量数据,而 AI 能在较短的时间内自动生成报告。


 # 生图模型
Source: https://docs.siliconflow.cn/cn/userguide/capabilities/images
## 1.生图模型简介
平台提供的生图模型主要有以下两种使用方式:一种是根据prompt输入直接生成图像;一种是根据现有图像,加上prompt输入,生成图像变体。
* **根据文本提示创建图像**
在使用文生图的大模型时,为了生成更高质量的图像,输入的prompt(提示词)需要精心设计。以下是一些有助于提高生成图像质量的提示词输入技巧:
* **具体描述**:尽量详细地描述你想要生成的图像内容。比如,如果你想生成一幅日落的海滩风景,不要仅仅输入“海滩日落”,而是可以尝试输入“一个宁静的海滩上,夕阳西下,天空呈现出橙红色,海浪轻轻拍打着沙滩,远处有一艘小船”。
* **情感和氛围**:除了描述图像的内容,还可以加入对情感或氛围的描述,比如“温馨的”、“神秘的”、“充满活力的”等,这样可以帮助模型更好地理解你想要的风格。
* **风格指定**:如果你有特定的艺术风格偏好,比如“印象派”、“超现实主义”等,可以在prompt中明确指出,这样生成的图像更有可能符合你的期待。
* **避免模糊不清的词汇**:尽量避免使用过于抽象或模糊不清的词汇,比如“美”、“好”等,这些词汇对于模型来说难以具体化,可能会导致生成的图像与预期相差较大。
* **使用否定词**:如果你不希望图像中出现某些元素,可以使用否定词来排除。例如,“生成一幅海滩日落的图片,但不要有船”。
* **分步骤输入**:对于复杂场景,可以尝试分步骤输入提示词,先生成基础图像,再根据需要调整或添加细节。
* **尝试不同的描述方式**:有时候,即使描述的是同一个场景,不同的描述方式也会得到不同的结果。可以尝试从不同的角度或使用不同的词汇来描述,看看哪种方式能得到更满意的结果。
* **利用模型的特定功能**:一些模型可能提供了特定的功能或参数调整选项,比如调整生成图像的分辨率、风格强度等,合理利用这些功能也可以帮助提高生成图像的质量。
通过上述方法,可以有效地提高使用文生图大模型时生成图像的质量。不过,由于不同的模型可能有不同的特点和偏好,实际操作中可能还需要根据具体模型的特性和反馈进行适当的调整。
可以参考如下示例:
> A futuristic eco-friendly skyscraper in central Tokyo. The building incorporates lush vertical gardens on every floor, with cascading plants and trees lining glass terraces. Solar panels and wind turbines are integrated into the structure's design, reflecting a sustainable future. The Tokyo Tower is visible in the background, contrasting the modern eco-architecture with traditional city landmarks.
> An elegant snow leopard perched on a cliff in the Himalayan mountains, surrounded by swirling snow. The animal’s fur is intricately detailed with distinctive patterns and a thick winter coat. The scene captures the majesty and isolation of the leopard's habitat, with mist and mountain peaks fading into the background.
* **根据现有图像,生成图像变体**
有部分生图模型支持通过已有图像生成图像变体,这种情况下,仍然需要输入适当的prompt,才能达到预期的效果,具体prompt输入,可以参考上面内容。
## 2.体验地址
可以通过 [图像生成](https://cloud.siliconflow.cn/playground/image) 体验生图的功能,也可以通过 [API文档](https://docs.siliconflow.cn/api-reference/images/images-generations) 介绍,通过API进行调用。
* **重点参数介绍**
* **image\_size**:控制参数的图像分辨率,API请求时候,可以自定义多种分辨率。
* **num\_inference\_steps**:控制图像生成的步长。
* **batch\_size**:一次生成图像的个数,默认值是1,最大值可以设置为4
* **negative\_prompt**:这里可以输入图像中不想出现的某些元素,消除一些影响影响因素。
* **seed**:如果想要每次都生成固定的图片,可以把seed设置为固定值。
{/*## 3.生图计费介绍
平台的生图计费分为两种计费方式:
- **根据图像大小及图像步长进行计费,单价是 ¥x/M px/Steps,即每M像素每步长是x元。**
比如想要生成一个`宽1024*高512`、4步长的图像,选择单价是`¥0.0032/M px/Steps`的stabilityai/stable-diffusion-3-5-large-turbo模型,那么生成一张图片的价格就是`(1024x512)/(1024x1024)x4x0.0032=0.0064元`,其中2代表`宽1024*高512`像素的大小是0.5M,生成一张图像的价格跟生成图像的像素大小和价格都有关系。
- **根据图片张数进行计费,单价是`¥x/Image`,即每张图片的价格是x元。**
比如想要生成一个`宽1024*高512`像素,4步长的图像,选择单价是`¥0.37/Image`的black-forest-labs/FLUX.1-pro模型,那么生成一张图片的价格就是`0.37元`,生成一张图像的价格,跟像素和步长都无关。
注意:选择的模型不一样,计费方式可能不同,请用户根据自身需求,选择相应计费方式的模型。 */}
## 3.支持模型列表
目前已支持的生图模型:
* Kwai-Kolors/Kolors
{/*
- 文生图系列:
- black-forest-labs系列:
- black-forest-labs/FLUX.1-dev
- black-forest-labs/FLUX.1-schnell
- Pro/black-forest-labs/FLUX.1-schnell
- black-forest-labs/FLUX.1-pro
- stabilityai系列:
- stabilityai/stable-diffusion-3-5-large
- stabilityai/stable-diffusion-3-5-large-turbo
- stabilityai/stable-diffusion-xl-base-1.0
- stabilityai/stable-diffusion-2-1
- deepseekai系列:
- deepseek-ai/Janus-Pro-7B
默认出图为 `384*384` 分辨率
- 图生图系列:
- stabilityai系列:
- stabilityai/stable-diffusion-xl-base-1.0
- stabilityai/stable-diffusion-2-1
*/}
注意:支持的生图模型可能发生调整,请在「模型广场」筛选“生图”标签,了解支持的模型列表。
# 推理模型
Source: https://docs.siliconflow.cn/cn/userguide/capabilities/reasoning
## 1. 概述
推理模型是基于深度学习的AI系统,通过逻辑推演、知识关联和上下文分析解决复杂任务,典型应用包括数学解题、代码生成、逻辑判断和多步推理场景。这类模型通常具备以下特性:
* 结构化思维:采用思维链(Chain-of-Thought)等技术分解复杂问题
* 知识融合:整合领域知识库与常识推理能力
* 自修正机制:通过验证反馈回路提升结果可靠性
* 多模态处理:部分先进模型支持文本/代码/公式混合输入
## 2. 平台支持推理模型列表
* tencent:
* tencent/Hunyuan-A13B-Instruct
* MiniMaxAI:
* MiniMaxAI/MiniMax-M1-80k
* Qwen 系列:
* Tongyi-Zhiwen/QwenLong-L1-32B
* Qwen/Qwen3-30B-A3B
* Qwen/Qwen3-32B
* Qwen/Qwen3-14B
* Qwen/Qwen3-8B
* Qwen/Qwen3-235B-A22B
* Qwen/QwQ-32B
* THUDM 系列:
* THUDM/GLM-Z1-32B-0414
* THUDM/GLM-Z1-Rumination-32B-0414
* THUDM/GLM-Z1-9B-0414
* deepseek-ai 系列:
* Pro/deepseek-ai/DeepSeek-R1
* deepseek-ai/DeepSeek-R1
* Pro/deepseek-ai/DeepSeek-R1-0120
* deepseek-ai/DeepSeek-R1-Distill-Qwen-32B
* deepseek-ai/DeepSeek-R1-Distill-Qwen-14B
* deepseek-ai/DeepSeek-R1-Distill-Qwen-7B
* deepseek-ai/DeepSeek-R1-Distill-Qwen-1.5B
* Pro/deepseek-ai/DeepSeek-R1-Distill-Qwen-7B
* Pro/deepseek-ai/DeepSeek-R1-Distill-Qwen-1.5B
## 3. 使用建议
### 3.1 API 参数
#### 3.1.1 请求参数
* **请求参数**:
* **最大思维链长度(thinking\_budget)**:模型用于内部推理的 token 数,调节 thinking\_budget 控制回答的思维链长度。
* **最大回复长度(max\_tokens**):仅用于限制模型最终输出给用户的回复 token 数,不包含思维链部分。用户可正常配置,控制回复的最大长度。
**最大上下文长度(context\_length)**:包括用户输入长度+思维链长度+输出长度的最大内容长度,非请求参数,不需要用户自己设置。
不同模型支持的最大回复长度、最大思维链长度及最大上下文长度如下表所示:
| 模型 | 最大回复长度 | 最大思维链长度 | 最大上下文长度 |
| ---------------------- | ------ | ------- | ------- |
| DeepSeek-R1 | 16384 | 32768 | 98304 |
| DeepSeek-R1-Distill 系列 | 16384 | 32768 | 131072 |
| Qwen3 系列 | 8192 | 32768 | 131072 |
| QwQ-32B | 32768 | 16384 | 131072 |
| GLM-Z1 系列 | 16384 | 32768 | 131072 |
| MiniMax-M1-80k | 40000 | 40000 | 80000 |
| Hunyuan-A13B-Instruct | 8192 | 38912 | 131072 |
推理模型思维链与回复长度分离后,输出行为将遵循以下规则:
* 若“思考阶段”生成的 `token` 数达到 `thinking_budget`,因 `Qwen3` 系列推理模型原生支持该参数模型将强制停止思维链推理,其他推理模型有可能会继续输出思考内容。
* 若最大回复长度超过 `max_tokens`或上下文长度超过`context_length` 限制,回复内容将进行截断,响应中的 `finish_reason` 字段将标记为 `length`,表示因长度限制终止输出。
#### 3.1.2 返回参数
* **返回参数**:
* reasoning\_content:思维链内容,与 content 同级。
* content:最终回答内容
### 3.2 DeepSeek-R1 使用建议
* 将 temperature 设置在 0.5-0.7 范围内(推荐值为 0.6),以防止无限循环或不连贯的输出。
* 将 top\_p 的值设置在 0.95。
* 避免添加系统提示,所有指令应包含在用户提示中。
* 对于数学问题,建议在提示中包含一个指令,例如:“请逐步推理,并将最终答案写在 \boxed{} 中。”
* 在评估模型性能时,建议进行多次测试并平均结果。
{/*
- 使用特定提示词用于文件上传和网页搜索,以提供更好的用户体验。
* 对于文件上传,请按照模板创建提示,其中`{file_name}`、`{file_content}` 和 `{question}` 是参数。
```bash
file_template = \
"""[file name]: {file_name}
[file content begin]
{file_content}
[file content end]
{question}"""
```
* 对于网页搜索,`{search_results}`、`{cur_data}` 和 `{question}`是参数。
* 对于中文查询,使用提示:
```bash
search_answer_zh_template = \
'''# 以下内容是基于用户发送的消息的搜索结果:
{search_results}
在我给你的搜索结果中,每个结果都是[webpage X begin]...[webpage X end]格式的,X代表每篇文章的数字索引。请在适当的情况下在句子末尾引用上下文。请按照引用编号[citation:X]的格式在答案中对应部分引用上下文。如果一句话源自多个上下文,请列出所有相关的引用编号,例如[citation:3][citation:5],切记不要将引用集中在最后返回引用编号,而是在答案对应部分列出。
在回答时,请注意以下几点:
- 今天是{cur_date}。
- 并非搜索结果的所有内容都与用户的问题密切相关,你需要结合问题,对搜索结果进行甄别、筛选。
- 对于列举类的问题(如列举所有航班信息),尽量将答案控制在10个要点以内,并告诉用户可以查看搜索来源、获得完整信息。优先提供信息完整、最相关的列举项;如非必要,不要主动告诉用户搜索结果未提供的内容。
- 对于创作类的问题(如写论文),请务必在正文的段落中引用对应的参考编号,例如[citation:3][citation:5],不能只在文章末尾引用。你需要解读并概括用户的题目要求,选择合适的格式,充分利用搜索结果并抽取重要信息,生成符合用户要求、极具思想深度、富有创造力与专业性的答案。你的创作篇幅需要尽可能延长,对于每一个要点的论述要推测用户的意图,给出尽可能多角度的回答要点,且务必信息量大、论述详尽。
- 如果回答很长,请尽量结构化、分段落总结。如果需要分点作答,尽量控制在5个点以内,并合并相关的内容。
- 对于客观类的问答,如果问题的答案非常简短,可以适当补充一到两句相关信息,以丰富内容。
- 你需要根据用户要求和回答内容选择合适、美观的回答格式,确保可读性强。
- 你的回答应该综合多个相关网页来回答,不能重复引用一个网页。
- 除非用户要求,否则你回答的语言需要和用户提问的语言保持一致。
# 用户消息为:
{question}'''
```
* 对于英文查询,使用提示:
```bash
search_answer_en_template = \
'''# The following contents are the search results related to the user's message:
{search_results}
In the search results I provide to you, each result is formatted as [webpage X begin]...[webpage X end], where X represents the numerical index of each article. Please cite the context at the end of the relevant sentence when appropriate. Use the citation format [citation:X] in the corresponding part of your answer. If a sentence is derived from multiple contexts, list all relevant citation numbers, such as [citation:3][citation:5]. Be sure not to cluster all citations at the end; instead, include them in the corresponding parts of the answer.
When responding, please keep the following points in mind:
- Today is {cur_date}.
- Not all content in the search results is closely related to the user's question. You need to evaluate and filter the search results based on the question.
- For listing-type questions (e.g., listing all flight information), try to limit the answer to 10 key points and inform the user that they can refer to the search sources for complete information. Prioritize providing the most complete and relevant items in the list. Avoid mentioning content not provided in the search results unless necessary.
- For creative tasks (e.g., writing an essay), ensure that references are cited within the body of the text, such as [citation:3][citation:5], rather than only at the end of the text. You need to interpret and summarize the user's requirements, choose an appropriate format, fully utilize the search results, extract key information, and generate an answer that is insightful, creative, and professional. Extend the length of your response as much as possible, addressing each point in detail and from multiple perspectives, ensuring the content is rich and thorough.
- If the response is lengthy, structure it well and summarize it in paragraphs. If a point-by-point format is needed, try to limit it to 5 points and merge related content.
- For objective Q&A, if the answer is very brief, you may add one or two related sentences to enrich the content.
- Choose an appropriate and visually appealing format for your response based on the user's requirements and the content of the answer, ensuring strong readability.
- Your answer should synthesize information from multiple relevant webpages and avoid repeatedly citing the same webpage.
- Unless the user requests otherwise, your response should be in the same language as the user's question.
# The user's message is:
{question}'''
```*/}
## 4. OpenAI 请求示例
### 4.1 流式输出请求
```python
from openai import OpenAI
url = 'https://api.siliconflow.cn/v1/'
api_key = 'your api_key'
client = OpenAI(
base_url=url,
api_key=api_key
)
# 发送带有流式输出的请求
content = ""
reasoning_content=""
messages = [
{"role": "user", "content": "奥运会的传奇名将有哪些?"}
]
response = client.chat.completions.create(
model="Pro/deepseek-ai/DeepSeek-R1",
messages=messages,
stream=True, # 启用流式输出
max_tokens=4096,
extra_body={
"thinking_budget": 1024
}
)
# 逐步接收并处理响应
for chunk in response:
if chunk.choices[0].delta.content:
content += chunk.choices[0].delta.content
if chunk.choices[0].delta.reasoning_content:
reasoning_content += chunk.choices[0].delta.reasoning_content
# Round 2
messages.append({"role": "assistant", "content": content})
messages.append({'role': 'user', 'content': "继续"})
response = client.chat.completions.create(
model="Pro/deepseek-ai/DeepSeek-R1",
messages=messages,
stream=True
)
```
### 4.2 非流式输出请求
```python
from openai import OpenAI
url = 'https://api.siliconflow.cn/v1/'
api_key = 'your api_key'
client = OpenAI(
base_url=url,
api_key=api_key
)
# 发送非流式输出的请求
messages = [
{"role": "user", "content": "奥运会的传奇名将有哪些?"}
]
response = client.chat.completions.create(
model="Pro/deepseek-ai/DeepSeek-R1",
messages=messages,
stream=False,
max_tokens=4096,
extra_body={
"thinking_budget": 1024
}
)
content = response.choices[0].message.content
reasoning_content = response.choices[0].message.reasoning_content
# Round 2
messages.append({"role": "assistant", "content": content})
messages.append({'role': 'user', 'content': "继续"})
response = client.chat.completions.create(
model="Pro/deepseek-ai/DeepSeek-R1",
messages=messages,
stream=False
)
```
## 5. 注意事项
* API 密钥:请确保使用正确的 API 密钥进行身份验证。
* 流式输出:流式输出适用于需要逐步接收响应的场景,而非流式输出则适用于一次性获取完整响应的场景。
{/* - 上下文管理:在每一轮对话中,模型输出的思维链内容不会被拼接到下一轮对话的上下文中,因此需要手动管理上下文。*/}
## 6. 常见问题
* 如何获取 API 密钥?
请访问 [SiliconFlow](https://cloud.siliconflow.cn/) 注册并获取 API 密钥。
* 如何处理超长文本?
可以通过调整 max\_tokens 参数来控制输出的长度,但请注意最大长度为 16K。
# 语言模型
Source: https://docs.siliconflow.cn/cn/userguide/capabilities/text-generation
语言模型(LLM)使用说明手册
## 1. 模型核心能力
### 1.1 基础功能
文本生成:根据上下文生成连贯的自然语言文本,支持多种文体和风格。
语义理解:深入解析用户意图,支持多轮对话管理,确保对话的连贯性和准确性。
知识问答:覆盖广泛的知识领域,包括科学、技术、文化、历史等,提供准确的知识解答。
代码辅助:支持多种主流编程语言(如Python、Java、C++等)的代码生成、解释和调试。
### 1.2 进阶能力
长文本处理:支持4k至64k tokens的上下文窗口,适用于长篇文档生成和复杂对话场景。
指令跟随:精确理解复杂任务指令,如“用Markdown表格对比A/B方案”。
风格控制:通过系统提示词调整输出风格,支持学术、口语、诗歌等多种风格。
多模态支持:除了文本生成,还支持图像描述、语音转文字等多模态任务。
## 2. 接口调用规范
### 2.1 基础请求结构
您可以通过 openai sdk进行端到端接口请求
```python
from openai import OpenAI
client = OpenAI(api_key="YOUR_KEY", base_url="https://api.siliconflow.cn/v1")
response = client.chat.completions.create(
model="deepseek-ai/DeepSeek-V3",
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Write a haiku about recursion in programming."}
],
temperature=0.7,
max_tokens=1024,
stream=True
)
# 逐步接收并处理响应
for chunk in response:
if not chunk.choices:
continue
if chunk.choices[0].delta.content:
print(chunk.choices[0].delta.content, end="", flush=True)
if chunk.choices[0].delta.reasoning_content:
print(chunk.choices[0].delta.reasoning_content, end="", flush=True)
```
```python
from openai import OpenAI
client = OpenAI(api_key="YOUR_KEY", base_url="https://api.siliconflow.cn/v1")
response = client.chat.completions.create(
model="deepseek-ai/deepseek-vl2",
messages=[
{
"role": "user",
"content": [
{
"type": "image_url",
"image_url": {
"url": "https://sf-maas-uat-prod.oss-cn-shanghai.aliyuncs.com/outputs/658c7434-ec12-49cc-90e6-fe22ccccaf62_00001_.png",
},
},
{
"type": "text",
"text": "What's in this image?"
}
],
}
],
temperature=0.7,
max_tokens=1024,
stream=True
)
# 逐步接收并处理响应
for chunk in response:
if not chunk.choices:
continue
if chunk.choices[0].delta.content:
print(chunk.choices[0].delta.content, end="", flush=True)
if chunk.choices[0].delta.reasoning_content:
print(chunk.choices[0].delta.reasoning_content, end="", flush=True)
```
```python
import json
from openai import OpenAI
client = OpenAI(
api_key="您的 APIKEY", # 从https://cloud.siliconflow.cn/account/ak获取
base_url="https://api.siliconflow.cn/v1"
)
response = client.chat.completions.create(
model="deepseek-ai/DeepSeek-V2.5",
messages=[
{"role": "system", "content": "You are a helpful assistant designed to output JSON."},
{"role": "user", "content": "? 2020 年世界奥运会乒乓球男子和女子单打冠军分别是谁? "
"Please respond in the format {\"男子冠军\": ..., \"女子冠军\": ...}"}
],
response_format={"type": "json_object"}
)
print(response.choices[0].message.content)
```
### 2.2 消息体结构说明
| 消息类型 | 功能描述 | 示例内容 |
| --------- | ------------------------------- | ------------------ |
| system | 模型指令,设定AI角色,描述模型应一般如何行为和响应 | 例如:"你是有10年经验的儿科医生" |
| user | 用户输入,将最终用户的消息传递给模型 | 例如:"幼儿持续低烧应如何处理?" |
| assistant | 模型生成的历史回复,为模型提供示例,说明它应该如何回应当前请求 | 例如:"建议先测量体温..." |
你想让模型遵循分层指令时,消息角色可以帮助你获得更好的输出。但它们并不是确定性的,所以使用的最佳方式是尝试不同的方法,看看哪种方法能给你带来好的结果。
## 3. 模型系列选型指南
可以进入[模型广场](https://cloud.siliconflow.cn/models),根据左侧的筛选功能,筛选支持不同功能的语言模型,根据模型的介绍,了解模型具体的价格、模型参数大小、模型上下文支持的最大长度及模型价格等内容。
支持在[playground](https://cloud.siliconflow.cn/playground/chat)进行体验(playground只进行模型体验,暂时没有历史记录功能,如果您想要保存历史的回话记录内容,请自己保存会话内容),想要了解更多使用方式,可以参考[API文档](https://docs.siliconflow.cn/cn/api-reference/chat-completions/chat-completions)
# 生图模型
Source: https://docs.siliconflow.cn/cn/userguide/capabilities/images
## 1.生图模型简介
平台提供的生图模型主要有以下两种使用方式:一种是根据prompt输入直接生成图像;一种是根据现有图像,加上prompt输入,生成图像变体。
* **根据文本提示创建图像**
在使用文生图的大模型时,为了生成更高质量的图像,输入的prompt(提示词)需要精心设计。以下是一些有助于提高生成图像质量的提示词输入技巧:
* **具体描述**:尽量详细地描述你想要生成的图像内容。比如,如果你想生成一幅日落的海滩风景,不要仅仅输入“海滩日落”,而是可以尝试输入“一个宁静的海滩上,夕阳西下,天空呈现出橙红色,海浪轻轻拍打着沙滩,远处有一艘小船”。
* **情感和氛围**:除了描述图像的内容,还可以加入对情感或氛围的描述,比如“温馨的”、“神秘的”、“充满活力的”等,这样可以帮助模型更好地理解你想要的风格。
* **风格指定**:如果你有特定的艺术风格偏好,比如“印象派”、“超现实主义”等,可以在prompt中明确指出,这样生成的图像更有可能符合你的期待。
* **避免模糊不清的词汇**:尽量避免使用过于抽象或模糊不清的词汇,比如“美”、“好”等,这些词汇对于模型来说难以具体化,可能会导致生成的图像与预期相差较大。
* **使用否定词**:如果你不希望图像中出现某些元素,可以使用否定词来排除。例如,“生成一幅海滩日落的图片,但不要有船”。
* **分步骤输入**:对于复杂场景,可以尝试分步骤输入提示词,先生成基础图像,再根据需要调整或添加细节。
* **尝试不同的描述方式**:有时候,即使描述的是同一个场景,不同的描述方式也会得到不同的结果。可以尝试从不同的角度或使用不同的词汇来描述,看看哪种方式能得到更满意的结果。
* **利用模型的特定功能**:一些模型可能提供了特定的功能或参数调整选项,比如调整生成图像的分辨率、风格强度等,合理利用这些功能也可以帮助提高生成图像的质量。
通过上述方法,可以有效地提高使用文生图大模型时生成图像的质量。不过,由于不同的模型可能有不同的特点和偏好,实际操作中可能还需要根据具体模型的特性和反馈进行适当的调整。
可以参考如下示例:
> A futuristic eco-friendly skyscraper in central Tokyo. The building incorporates lush vertical gardens on every floor, with cascading plants and trees lining glass terraces. Solar panels and wind turbines are integrated into the structure's design, reflecting a sustainable future. The Tokyo Tower is visible in the background, contrasting the modern eco-architecture with traditional city landmarks.
> An elegant snow leopard perched on a cliff in the Himalayan mountains, surrounded by swirling snow. The animal’s fur is intricately detailed with distinctive patterns and a thick winter coat. The scene captures the majesty and isolation of the leopard's habitat, with mist and mountain peaks fading into the background.
* **根据现有图像,生成图像变体**
有部分生图模型支持通过已有图像生成图像变体,这种情况下,仍然需要输入适当的prompt,才能达到预期的效果,具体prompt输入,可以参考上面内容。
## 2.体验地址
可以通过 [图像生成](https://cloud.siliconflow.cn/playground/image) 体验生图的功能,也可以通过 [API文档](https://docs.siliconflow.cn/api-reference/images/images-generations) 介绍,通过API进行调用。
* **重点参数介绍**
* **image\_size**:控制参数的图像分辨率,API请求时候,可以自定义多种分辨率。
* **num\_inference\_steps**:控制图像生成的步长。
* **batch\_size**:一次生成图像的个数,默认值是1,最大值可以设置为4
* **negative\_prompt**:这里可以输入图像中不想出现的某些元素,消除一些影响影响因素。
* **seed**:如果想要每次都生成固定的图片,可以把seed设置为固定值。
{/*## 3.生图计费介绍
平台的生图计费分为两种计费方式:
- **根据图像大小及图像步长进行计费,单价是 ¥x/M px/Steps,即每M像素每步长是x元。**
比如想要生成一个`宽1024*高512`、4步长的图像,选择单价是`¥0.0032/M px/Steps`的stabilityai/stable-diffusion-3-5-large-turbo模型,那么生成一张图片的价格就是`(1024x512)/(1024x1024)x4x0.0032=0.0064元`,其中2代表`宽1024*高512`像素的大小是0.5M,生成一张图像的价格跟生成图像的像素大小和价格都有关系。
- **根据图片张数进行计费,单价是`¥x/Image`,即每张图片的价格是x元。**
比如想要生成一个`宽1024*高512`像素,4步长的图像,选择单价是`¥0.37/Image`的black-forest-labs/FLUX.1-pro模型,那么生成一张图片的价格就是`0.37元`,生成一张图像的价格,跟像素和步长都无关。
注意:选择的模型不一样,计费方式可能不同,请用户根据自身需求,选择相应计费方式的模型。 */}
## 3.支持模型列表
目前已支持的生图模型:
* Kwai-Kolors/Kolors
{/*
- 文生图系列:
- black-forest-labs系列:
- black-forest-labs/FLUX.1-dev
- black-forest-labs/FLUX.1-schnell
- Pro/black-forest-labs/FLUX.1-schnell
- black-forest-labs/FLUX.1-pro
- stabilityai系列:
- stabilityai/stable-diffusion-3-5-large
- stabilityai/stable-diffusion-3-5-large-turbo
- stabilityai/stable-diffusion-xl-base-1.0
- stabilityai/stable-diffusion-2-1
- deepseekai系列:
- deepseek-ai/Janus-Pro-7B
默认出图为 `384*384` 分辨率
- 图生图系列:
- stabilityai系列:
- stabilityai/stable-diffusion-xl-base-1.0
- stabilityai/stable-diffusion-2-1
*/}
注意:支持的生图模型可能发生调整,请在「模型广场」筛选“生图”标签,了解支持的模型列表。
# 推理模型
Source: https://docs.siliconflow.cn/cn/userguide/capabilities/reasoning
## 1. 概述
推理模型是基于深度学习的AI系统,通过逻辑推演、知识关联和上下文分析解决复杂任务,典型应用包括数学解题、代码生成、逻辑判断和多步推理场景。这类模型通常具备以下特性:
* 结构化思维:采用思维链(Chain-of-Thought)等技术分解复杂问题
* 知识融合:整合领域知识库与常识推理能力
* 自修正机制:通过验证反馈回路提升结果可靠性
* 多模态处理:部分先进模型支持文本/代码/公式混合输入
## 2. 平台支持推理模型列表
* tencent:
* tencent/Hunyuan-A13B-Instruct
* MiniMaxAI:
* MiniMaxAI/MiniMax-M1-80k
* Qwen 系列:
* Tongyi-Zhiwen/QwenLong-L1-32B
* Qwen/Qwen3-30B-A3B
* Qwen/Qwen3-32B
* Qwen/Qwen3-14B
* Qwen/Qwen3-8B
* Qwen/Qwen3-235B-A22B
* Qwen/QwQ-32B
* THUDM 系列:
* THUDM/GLM-Z1-32B-0414
* THUDM/GLM-Z1-Rumination-32B-0414
* THUDM/GLM-Z1-9B-0414
* deepseek-ai 系列:
* Pro/deepseek-ai/DeepSeek-R1
* deepseek-ai/DeepSeek-R1
* Pro/deepseek-ai/DeepSeek-R1-0120
* deepseek-ai/DeepSeek-R1-Distill-Qwen-32B
* deepseek-ai/DeepSeek-R1-Distill-Qwen-14B
* deepseek-ai/DeepSeek-R1-Distill-Qwen-7B
* deepseek-ai/DeepSeek-R1-Distill-Qwen-1.5B
* Pro/deepseek-ai/DeepSeek-R1-Distill-Qwen-7B
* Pro/deepseek-ai/DeepSeek-R1-Distill-Qwen-1.5B
## 3. 使用建议
### 3.1 API 参数
#### 3.1.1 请求参数
* **请求参数**:
* **最大思维链长度(thinking\_budget)**:模型用于内部推理的 token 数,调节 thinking\_budget 控制回答的思维链长度。
* **最大回复长度(max\_tokens**):仅用于限制模型最终输出给用户的回复 token 数,不包含思维链部分。用户可正常配置,控制回复的最大长度。
**最大上下文长度(context\_length)**:包括用户输入长度+思维链长度+输出长度的最大内容长度,非请求参数,不需要用户自己设置。
不同模型支持的最大回复长度、最大思维链长度及最大上下文长度如下表所示:
| 模型 | 最大回复长度 | 最大思维链长度 | 最大上下文长度 |
| ---------------------- | ------ | ------- | ------- |
| DeepSeek-R1 | 16384 | 32768 | 98304 |
| DeepSeek-R1-Distill 系列 | 16384 | 32768 | 131072 |
| Qwen3 系列 | 8192 | 32768 | 131072 |
| QwQ-32B | 32768 | 16384 | 131072 |
| GLM-Z1 系列 | 16384 | 32768 | 131072 |
| MiniMax-M1-80k | 40000 | 40000 | 80000 |
| Hunyuan-A13B-Instruct | 8192 | 38912 | 131072 |
推理模型思维链与回复长度分离后,输出行为将遵循以下规则:
* 若“思考阶段”生成的 `token` 数达到 `thinking_budget`,因 `Qwen3` 系列推理模型原生支持该参数模型将强制停止思维链推理,其他推理模型有可能会继续输出思考内容。
* 若最大回复长度超过 `max_tokens`或上下文长度超过`context_length` 限制,回复内容将进行截断,响应中的 `finish_reason` 字段将标记为 `length`,表示因长度限制终止输出。
#### 3.1.2 返回参数
* **返回参数**:
* reasoning\_content:思维链内容,与 content 同级。
* content:最终回答内容
### 3.2 DeepSeek-R1 使用建议
* 将 temperature 设置在 0.5-0.7 范围内(推荐值为 0.6),以防止无限循环或不连贯的输出。
* 将 top\_p 的值设置在 0.95。
* 避免添加系统提示,所有指令应包含在用户提示中。
* 对于数学问题,建议在提示中包含一个指令,例如:“请逐步推理,并将最终答案写在 \boxed{} 中。”
* 在评估模型性能时,建议进行多次测试并平均结果。
{/*
- 使用特定提示词用于文件上传和网页搜索,以提供更好的用户体验。
* 对于文件上传,请按照模板创建提示,其中`{file_name}`、`{file_content}` 和 `{question}` 是参数。
```bash
file_template = \
"""[file name]: {file_name}
[file content begin]
{file_content}
[file content end]
{question}"""
```
* 对于网页搜索,`{search_results}`、`{cur_data}` 和 `{question}`是参数。
* 对于中文查询,使用提示:
```bash
search_answer_zh_template = \
'''# 以下内容是基于用户发送的消息的搜索结果:
{search_results}
在我给你的搜索结果中,每个结果都是[webpage X begin]...[webpage X end]格式的,X代表每篇文章的数字索引。请在适当的情况下在句子末尾引用上下文。请按照引用编号[citation:X]的格式在答案中对应部分引用上下文。如果一句话源自多个上下文,请列出所有相关的引用编号,例如[citation:3][citation:5],切记不要将引用集中在最后返回引用编号,而是在答案对应部分列出。
在回答时,请注意以下几点:
- 今天是{cur_date}。
- 并非搜索结果的所有内容都与用户的问题密切相关,你需要结合问题,对搜索结果进行甄别、筛选。
- 对于列举类的问题(如列举所有航班信息),尽量将答案控制在10个要点以内,并告诉用户可以查看搜索来源、获得完整信息。优先提供信息完整、最相关的列举项;如非必要,不要主动告诉用户搜索结果未提供的内容。
- 对于创作类的问题(如写论文),请务必在正文的段落中引用对应的参考编号,例如[citation:3][citation:5],不能只在文章末尾引用。你需要解读并概括用户的题目要求,选择合适的格式,充分利用搜索结果并抽取重要信息,生成符合用户要求、极具思想深度、富有创造力与专业性的答案。你的创作篇幅需要尽可能延长,对于每一个要点的论述要推测用户的意图,给出尽可能多角度的回答要点,且务必信息量大、论述详尽。
- 如果回答很长,请尽量结构化、分段落总结。如果需要分点作答,尽量控制在5个点以内,并合并相关的内容。
- 对于客观类的问答,如果问题的答案非常简短,可以适当补充一到两句相关信息,以丰富内容。
- 你需要根据用户要求和回答内容选择合适、美观的回答格式,确保可读性强。
- 你的回答应该综合多个相关网页来回答,不能重复引用一个网页。
- 除非用户要求,否则你回答的语言需要和用户提问的语言保持一致。
# 用户消息为:
{question}'''
```
* 对于英文查询,使用提示:
```bash
search_answer_en_template = \
'''# The following contents are the search results related to the user's message:
{search_results}
In the search results I provide to you, each result is formatted as [webpage X begin]...[webpage X end], where X represents the numerical index of each article. Please cite the context at the end of the relevant sentence when appropriate. Use the citation format [citation:X] in the corresponding part of your answer. If a sentence is derived from multiple contexts, list all relevant citation numbers, such as [citation:3][citation:5]. Be sure not to cluster all citations at the end; instead, include them in the corresponding parts of the answer.
When responding, please keep the following points in mind:
- Today is {cur_date}.
- Not all content in the search results is closely related to the user's question. You need to evaluate and filter the search results based on the question.
- For listing-type questions (e.g., listing all flight information), try to limit the answer to 10 key points and inform the user that they can refer to the search sources for complete information. Prioritize providing the most complete and relevant items in the list. Avoid mentioning content not provided in the search results unless necessary.
- For creative tasks (e.g., writing an essay), ensure that references are cited within the body of the text, such as [citation:3][citation:5], rather than only at the end of the text. You need to interpret and summarize the user's requirements, choose an appropriate format, fully utilize the search results, extract key information, and generate an answer that is insightful, creative, and professional. Extend the length of your response as much as possible, addressing each point in detail and from multiple perspectives, ensuring the content is rich and thorough.
- If the response is lengthy, structure it well and summarize it in paragraphs. If a point-by-point format is needed, try to limit it to 5 points and merge related content.
- For objective Q&A, if the answer is very brief, you may add one or two related sentences to enrich the content.
- Choose an appropriate and visually appealing format for your response based on the user's requirements and the content of the answer, ensuring strong readability.
- Your answer should synthesize information from multiple relevant webpages and avoid repeatedly citing the same webpage.
- Unless the user requests otherwise, your response should be in the same language as the user's question.
# The user's message is:
{question}'''
```*/}
## 4. OpenAI 请求示例
### 4.1 流式输出请求
```python
from openai import OpenAI
url = 'https://api.siliconflow.cn/v1/'
api_key = 'your api_key'
client = OpenAI(
base_url=url,
api_key=api_key
)
# 发送带有流式输出的请求
content = ""
reasoning_content=""
messages = [
{"role": "user", "content": "奥运会的传奇名将有哪些?"}
]
response = client.chat.completions.create(
model="Pro/deepseek-ai/DeepSeek-R1",
messages=messages,
stream=True, # 启用流式输出
max_tokens=4096,
extra_body={
"thinking_budget": 1024
}
)
# 逐步接收并处理响应
for chunk in response:
if chunk.choices[0].delta.content:
content += chunk.choices[0].delta.content
if chunk.choices[0].delta.reasoning_content:
reasoning_content += chunk.choices[0].delta.reasoning_content
# Round 2
messages.append({"role": "assistant", "content": content})
messages.append({'role': 'user', 'content': "继续"})
response = client.chat.completions.create(
model="Pro/deepseek-ai/DeepSeek-R1",
messages=messages,
stream=True
)
```
### 4.2 非流式输出请求
```python
from openai import OpenAI
url = 'https://api.siliconflow.cn/v1/'
api_key = 'your api_key'
client = OpenAI(
base_url=url,
api_key=api_key
)
# 发送非流式输出的请求
messages = [
{"role": "user", "content": "奥运会的传奇名将有哪些?"}
]
response = client.chat.completions.create(
model="Pro/deepseek-ai/DeepSeek-R1",
messages=messages,
stream=False,
max_tokens=4096,
extra_body={
"thinking_budget": 1024
}
)
content = response.choices[0].message.content
reasoning_content = response.choices[0].message.reasoning_content
# Round 2
messages.append({"role": "assistant", "content": content})
messages.append({'role': 'user', 'content': "继续"})
response = client.chat.completions.create(
model="Pro/deepseek-ai/DeepSeek-R1",
messages=messages,
stream=False
)
```
## 5. 注意事项
* API 密钥:请确保使用正确的 API 密钥进行身份验证。
* 流式输出:流式输出适用于需要逐步接收响应的场景,而非流式输出则适用于一次性获取完整响应的场景。
{/* - 上下文管理:在每一轮对话中,模型输出的思维链内容不会被拼接到下一轮对话的上下文中,因此需要手动管理上下文。*/}
## 6. 常见问题
* 如何获取 API 密钥?
请访问 [SiliconFlow](https://cloud.siliconflow.cn/) 注册并获取 API 密钥。
* 如何处理超长文本?
可以通过调整 max\_tokens 参数来控制输出的长度,但请注意最大长度为 16K。
# 语言模型
Source: https://docs.siliconflow.cn/cn/userguide/capabilities/text-generation
语言模型(LLM)使用说明手册
## 1. 模型核心能力
### 1.1 基础功能
文本生成:根据上下文生成连贯的自然语言文本,支持多种文体和风格。
语义理解:深入解析用户意图,支持多轮对话管理,确保对话的连贯性和准确性。
知识问答:覆盖广泛的知识领域,包括科学、技术、文化、历史等,提供准确的知识解答。
代码辅助:支持多种主流编程语言(如Python、Java、C++等)的代码生成、解释和调试。
### 1.2 进阶能力
长文本处理:支持4k至64k tokens的上下文窗口,适用于长篇文档生成和复杂对话场景。
指令跟随:精确理解复杂任务指令,如“用Markdown表格对比A/B方案”。
风格控制:通过系统提示词调整输出风格,支持学术、口语、诗歌等多种风格。
多模态支持:除了文本生成,还支持图像描述、语音转文字等多模态任务。
## 2. 接口调用规范
### 2.1 基础请求结构
您可以通过 openai sdk进行端到端接口请求
```python
from openai import OpenAI
client = OpenAI(api_key="YOUR_KEY", base_url="https://api.siliconflow.cn/v1")
response = client.chat.completions.create(
model="deepseek-ai/DeepSeek-V3",
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Write a haiku about recursion in programming."}
],
temperature=0.7,
max_tokens=1024,
stream=True
)
# 逐步接收并处理响应
for chunk in response:
if not chunk.choices:
continue
if chunk.choices[0].delta.content:
print(chunk.choices[0].delta.content, end="", flush=True)
if chunk.choices[0].delta.reasoning_content:
print(chunk.choices[0].delta.reasoning_content, end="", flush=True)
```
```python
from openai import OpenAI
client = OpenAI(api_key="YOUR_KEY", base_url="https://api.siliconflow.cn/v1")
response = client.chat.completions.create(
model="deepseek-ai/deepseek-vl2",
messages=[
{
"role": "user",
"content": [
{
"type": "image_url",
"image_url": {
"url": "https://sf-maas-uat-prod.oss-cn-shanghai.aliyuncs.com/outputs/658c7434-ec12-49cc-90e6-fe22ccccaf62_00001_.png",
},
},
{
"type": "text",
"text": "What's in this image?"
}
],
}
],
temperature=0.7,
max_tokens=1024,
stream=True
)
# 逐步接收并处理响应
for chunk in response:
if not chunk.choices:
continue
if chunk.choices[0].delta.content:
print(chunk.choices[0].delta.content, end="", flush=True)
if chunk.choices[0].delta.reasoning_content:
print(chunk.choices[0].delta.reasoning_content, end="", flush=True)
```
```python
import json
from openai import OpenAI
client = OpenAI(
api_key="您的 APIKEY", # 从https://cloud.siliconflow.cn/account/ak获取
base_url="https://api.siliconflow.cn/v1"
)
response = client.chat.completions.create(
model="deepseek-ai/DeepSeek-V2.5",
messages=[
{"role": "system", "content": "You are a helpful assistant designed to output JSON."},
{"role": "user", "content": "? 2020 年世界奥运会乒乓球男子和女子单打冠军分别是谁? "
"Please respond in the format {\"男子冠军\": ..., \"女子冠军\": ...}"}
],
response_format={"type": "json_object"}
)
print(response.choices[0].message.content)
```
### 2.2 消息体结构说明
| 消息类型 | 功能描述 | 示例内容 |
| --------- | ------------------------------- | ------------------ |
| system | 模型指令,设定AI角色,描述模型应一般如何行为和响应 | 例如:"你是有10年经验的儿科医生" |
| user | 用户输入,将最终用户的消息传递给模型 | 例如:"幼儿持续低烧应如何处理?" |
| assistant | 模型生成的历史回复,为模型提供示例,说明它应该如何回应当前请求 | 例如:"建议先测量体温..." |
你想让模型遵循分层指令时,消息角色可以帮助你获得更好的输出。但它们并不是确定性的,所以使用的最佳方式是尝试不同的方法,看看哪种方法能给你带来好的结果。
## 3. 模型系列选型指南
可以进入[模型广场](https://cloud.siliconflow.cn/models),根据左侧的筛选功能,筛选支持不同功能的语言模型,根据模型的介绍,了解模型具体的价格、模型参数大小、模型上下文支持的最大长度及模型价格等内容。
支持在[playground](https://cloud.siliconflow.cn/playground/chat)进行体验(playground只进行模型体验,暂时没有历史记录功能,如果您想要保存历史的回话记录内容,请自己保存会话内容),想要了解更多使用方式,可以参考[API文档](https://docs.siliconflow.cn/cn/api-reference/chat-completions/chat-completions)
 ## 4. 核心参数详解
### 4.1 创造性控制
```bash
# 温度参数(0.0~2.0)
temperature=0.5 # 平衡创造性与可靠性
# 核采样(top_p)
top_p=0.9 # 仅考虑概率累积90%的词集
```
### 4.2 输出限制
```json
max_tokens=1000 # 单词请求最大生成长度
stop=["\n##", "<|end|>"] # 终止序列,在返回中遇到数组中对应的字符串,就会停止输出
frequency_penalty=0.5 # 抑制重复用词(-2.0~2.0)
stream=true # 控制输出是否是流式输出,对于一些输出内容比较多的模型,建议设置为流式,防止输出过长,导致输出超时
```
### 4.3 语言模型场景问题汇总
**1. 模型输出乱码**
目前看到部分模型在不设置参数的情况下,容易出现乱码,遇到上述情况,可以尝试设置`temperature`,`top_k`,`top_p`,`frequency_penalty`这些参数。
对应的 payload 修改为如下形式,不同语言酌情调整
```python
payload = {
"model": "Qwen/Qwen2.5-Math-72B-Instruct",
"messages": [
{
"role": "user",
"content": "1+1=?",
}
],
"max_tokens": 200, # 按需添加
"temperature": 0.7, # 按需添加
"top_k": 50, # 按需添加
"top_p": 0.7, # 按需添加
"frequency_penalty": 0 # 按需添加
}
```
**2. 关于`max_tokens`说明**
平台提供的LLM模型中,
* max\_tokens 限制为 `32768` 的模型:
* Qwen/QwQ-32B
* max\_tokens 限制为 `16384` 的模型:
* Pro/deepseek-ai/DeepSeek-R1
* deepseek-ai/DeepSeek-R1
* Pro/deepseek-ai/DeepSeek-R1-0120
* Qwen/QVQ-72B-Preview
* deepseek-ai/DeepSeek-R1-Distill-Qwen-32B
* deepseek-ai/DeepSeek-R1-Distill-Qwen-14B
* deepseek-ai/DeepSeek-R1-Distill-Qwen-7B
* deepseek-ai/DeepSeek-R1-Distill-Qwen-1.5B
* Pro/deepseek-ai/DeepSeek-R1-Distill-Qwen-7B
* Pro/deepseek-ai/DeepSeek-R1-Distill-Qwen-1.5B
* max\_tokens 限制为 `8192` 的模型:
* baidu/ERNIE-4.5-300B-A47B
* tencent/Hunyuan-A13B-Instruct
* Tongyi-Zhiwen/QwenLong-L1-32B
* Qwen/Qwen3-30B-A3B
* Qwen/Qwen3-32B
* Qwen/Qwen3-14B
* Qwen/Qwen3-8B
* Qwen/Qwen3-235B-A22B
* THUDM/GLM-4-32B-0414
* THUDM/GLM-4-9B-0414
* Pro/deepseek-ai/DeepSeek-V3
* deepseek-ai/DeepSeek-V3
* Qwen/QwQ-32B-Preview
* Qwen/Qwen2.5-VL-32B-Instruct
* max\_tokens 限制为 `4096`的模型:
* 除上述提到的其他LLM模型的
**3. 关于`context_length`说明**
不同的LLM模型,`context_length`是有差别的,具体可以在[模型广场](https://cloud.siliconflow.cn/models)上搜索对应的模型,
查看模型具体信息。
**4. 模型输出截断问题**
可以从以下几方面进行问题的排查:
* 通过API请求时候,输出截断问题排查:
* max\_tokens设置:max\_token设置到合适值,输出大于max\_token的情况下,会被截断,deepseek R1系列的max\_token最大可设置为16384。
* 设置流式输出请求:非流式请求时候,输出内容比较长的情况下,容易出现504超时。
* 设置客户端超时时间:把客户端超时时间设置大一些,防止未输出完成,达到客户端超时时间被截断。
* 通过第三方客户端请求,输出截断问题排查:
* CherryStdio 默认的 max\_tokens 是 4096,用户可以通过设置,打开“开启消息长度限制”的开关,将max\_token设置到合适值
**5. 错误码处理**
| 错误码 | 常见原因 | 解决方案 |
| ------- | -------------- | --------------------------- |
| 400 | 参数格式错误 | 检查temperature等请求参数的取值范围 |
| 401 | API Key 没有正确设置 | 检查API Key |
| 403 | 权限不够 | 最常见的原因是该模型需要实名认证,其他情况参考报错信息 |
| 429 | 请求频率超限 | 实施指数退避重试机制 |
| 503/504 | 模型过载 | 切换备用模型节点 |
## 5. 计费与配额管理
### 5.1 计费公式
`总费用 = (输入tokens × 输入单价) + (输出tokens × 输出单价) `
### 5.2 各系列单价示例
模型的具体价格可以进入[模型广场](https://cloud.siliconflow.cn/models)下的模型详情页查看。
## 6. 应用案例
### 6.1 技术文档生成
```python
from openai import OpenAI
client = OpenAI(api_key="YOUR_KEY", base_url="https://api.siliconflow.cn/v1")
response = client.chat.completions.create(
model="Qwen/Qwen2.5-Coder-32B-Instruct",
messages=[{
"role": "user",
"content": "编写Python异步爬虫教程,包含代码示例和注意事项"
}],
temperature=0.7,
max_tokens=4096
)
```
### 6.2 数据分析报告
```python
from openai import OpenAI
client = OpenAI(api_key="YOUR_KEY", base_url="https://api.siliconflow.cn/v1")
response = client.chat.completions.create(
model="Qwen/QVQ-72B-Preview",
messages=[
{"role": "system", "content": "你是数据分析专家,用Markdown输出结果"},
{"role": "user", "content": "分析2023年新能源汽车销售数据趋势"}
],
temperature=0.7,
max_tokens=4096
)
```
模型能力持续更新中,建议定期访问[模型广场](https://cloud.siliconflow.cn/models)获取最新信息。
# 文本转语音模型
Source: https://docs.siliconflow.cn/cn/userguide/capabilities/text-to-speech
## 1. 使用场景
文本转语音模型(TTS)是一种将文本信息转换为语音输出的 AI 模型。该模型将输入文本内容生成自然流畅、富有表现力的语音,适用于多种应用场景:
* 为博客文章提供音频朗读
* 生成多语言语音内容
* 支持实时流媒体音频输出
## 2. API 使用指南
* 端点:/audio/speech,具体使用可参考[api文档](https://docs.siliconflow.cn/api-reference/audio/create-speech)
* 主要请求参数:
* model:用于语音合成的模型,支持的[模型列表](/capabilities/text-to-speech#3)。
* input:待转换为音频的文本内容。
* voice:参考音色,支持[系统预置音色](/capabilities/text-to-speech#2-1)、[用户预置音色](/capabilities/text-to-speech#2-2)、[用户动态音色](/capabilities/text-to-speech#2-3)。
详细参数请参考:[创建文本转语音请求](/api-reference/audio/create-speech)。
* speed:可以控制音频速度,float类型,默认值是1.0,可选范围是\[0.25,4.0];
* gain:音频增益,单位dB,可以控制音频声音大小,float类型,默认值是0.0,可选范围是\[-10,10];
* response\_format:控制输出格式,支持 mp3、opus、wav 和 pcm 格式。在选择不同的输出格式时,输出的采样率也会有所不同。
* sample\_rate:可以控制输出采样率,对于不同的视频输出类型,默认值和可取值范围均不同,具体如下:
* opus: 目前只支持48000hz
* wav, pcm: 支持 (8000, 16000, 24000, 32000, 44100), 默认44100
* mp3: 支持(32000, 44100), 默认44100
### 2.1 系统预置音色:
目前系统预置了如下 8 种音色:
* 男生音色:
* 沉稳男声: [alex](https://sf-maas-uat-prod.oss-cn-shanghai.aliyuncs.com/voice_template/fish_audio-Alex.mp3)
* 低沉男声: [benjamin](https://sf-maas-uat-prod.oss-cn-shanghai.aliyuncs.com/voice_template/fish_audio-Benjamin.mp3)
* 磁性男声: [charles](https://sf-maas-uat-prod.oss-cn-shanghai.aliyuncs.com/voice_template/fish_audio-Charles.mp3)
* 欢快男声: [david](https://sf-maas-uat-prod.oss-cn-shanghai.aliyuncs.com/voice_template/fish_audio-David.mp3)
* 女生音色:
* 沉稳女声: [anna](https://sf-maas-uat-prod.oss-cn-shanghai.aliyuncs.com/voice_template/fish_audio-Anna.mp3)
* 激情女声: [bella](https://sf-maas-uat-prod.oss-cn-shanghai.aliyuncs.com/voice_template/fish_audio-Bella.mp3)
* 温柔女声: [claire](https://sf-maas-uat-prod.oss-cn-shanghai.aliyuncs.com/voice_template/fish_audio-Claire.mp3)
* 欢快女声: [diana](https://sf-maas-uat-prod.oss-cn-shanghai.aliyuncs.com/voice_template/fish_audio-Diana.mp3)
[在线试听](https://soundcloud.com/siliconcloud/sets/siliconcloud-online-voice)上述音频。
在请求中[使用系统预置音色](/capabilities/text-to-speech#5-1)。
在使用对应的系统预置音色时,需要在前面加上模型名称,比如:
`FunAudioLLM/CosyVoice2-0.5B:alex` 表示 `FunAudioLLM/CosyVoice2-0.5B` 模型下的 `alex` 音色。
{/* `fishaudio/fish-speech-1.5:anna` 表示 `fishaudio/fish-speech-1.5` 模型下的 `anna` 音色。*/}
### 2.2 用户预置音色:
注意:使用用户预置音色,需要进行实名认证。
#### 2.2.1 通过 `base64` 编码格式上传用户预置音色
```python
import requests
import json
url = "https://api.siliconflow.cn/v1/uploads/audio/voice"
headers = {
"Authorization": "Bearer your-api-key", # 从 https://cloud.siliconflow.cn/account/ak 获取
"Content-Type": "application/json"
}
data = {
"model": "FunAudioLLM/CosyVoice2-0.5B", # 模型名称
"customName": "your-voice-name", # 用户自定义的音频名称
"audio": "data:audio/mpeg;base64,SUQzBAAAAAAAIlRTU0UAAAAOAAADTGF2ZjYxLjcuMTAwAAAAAAAAAAAAAAD/40DAAAAAAAAAAAAASW5mbwAAAA8AAAAWAAAJywAfHx8fKioqKio1NTU1Pz8/Pz9KSkpKVVVVVVVfX19fampqamp1dXV1f39/f3+KioqKlZWVlZWfn5+fn6qqqqq1tbW1tb+/v7/KysrKytXV1dXf39/f3+rq6ur19fX19f////", # 参考音频的 base64 编码
"text": "在一无所知中, 梦里的一天结束了,一个新的轮回便会开始" # 参考音频的文字内容
}
response = requests.post(url, headers=headers, data=json.dumps(data))
# 打印响应状态码和响应内容
print(response.status_code)
print(response.json()) # 如果响应是 JSON 格式
```
上述接口返回的 `uri` 字段,即为自定义音色的 ID,用户可以将其作为后续的 `voice` 参数中,进行请求。
```json
{'uri': 'speech:your-voice-name:cm04pf7az00061413w7kz5qxs:mjtkgbyuunvtybnsvbxd'}
```
在请求中[使用用户预置音色](/capabilities/text-to-speech#5-2)。
#### 2.2.2 通过文件上传用户预置音色
```python
import requests
url = "https://api.siliconflow.cn/v1/uploads/audio/voice"
headers = {
"Authorization": "Bearer your-api-key" # 从 https://cloud.siliconflow.cn/account/ak 获取
}
files = {
"file": open("/Users/senseb/Downloads/fish_audio-Alex.mp3", "rb") # 参考音频文件
}
data = {
"model": "FunAudioLLM/CosyVoice2-0.5B", # 模型名称
"customName": "your-voice-name", # 参考音频名称
"text": "在一无所知中, 梦里的一天结束了,一个新的轮回便会开始" # 参考音频的文字内容
}
response = requests.post(url, headers=headers, files=files, data=data)
print(response.status_code)
print(response.json()) # 打印响应内容(如果是JSON格式)
```
上述接口返回的 `uri` 字段,即为自定义音色的 ID,用户可以将其作为后续的 `voice` 参数中,进行请求。
```json
{'uri': 'speech:your-voice-name:cm04pf7az00061413w7kz5qxs:mjtkgbyuunvtybnsvbxd'}
```
在请求中[使用用户预置音色](/capabilities/text-to-speech#5-2)。
### 2.3 获取用户动态音色列表
```python
import requests
url = "https://api.siliconflow.cn/v1/audio/voice/list"
headers = {
"Authorization": "Bearer your-api-key" # 从https://cloud.siliconflow.cn/account/ak获取
}
response = requests.get(url, headers=headers)
print(response.status_code)
print(response.json()) # 打印响应内容(如果是JSON格式)
```
上述接口返回的 `uri` 字段,即为自定义音色的 ID,用户可以将其作为后续的 `voice` 参数中,进行请求。
```json
{'uri': 'speech:your-voice-name:cm04pf7az00061413w7kz5qxs:mjtkgbyuunvtybnsvbxd'}
```
在请求中[使用用户预置音色](/capabilities/text-to-speech#5-2)。
### 2.4 使用用户动态音色
注意:使用用户预置音色,需要进行实名认证。
在请求中[使用用户动态音色](/capabilities/text-to-speech#5-3)。
### 2.5 删除用户动态音色
```python
import requests
url = "https://api.siliconflow.cn/v1/audio/voice/deletions"
headers = {
"Authorization": "Bearer your-api-key",
"Content-Type": "application/json"
}
payload = {
"uri": "speech:your-voice-name:cm02pf7az00061413w7kz5qxs:mttkgbyuunvtybnsvbxd"
}
response = requests.request("POST", url, json=payload, headers=headers)
print(response.status_code)
print(response.text) #打印响应内容
```
上述接口请求参数中的 `uri` 字段,即为自定义音色的 ID。
## 3. 支持模型列表
注意:支持的 TTS 模型可能发生调整,请在「模型广场」筛选[“语音”标签](https://cloud.siliconflow.cn/models?types=speech) 获得当前支持的模型列表。
计费方式:按照输入文本长度对应的 [UTF-8 字节](https://zh.wikipedia.org/wiki/UTF-8) 数进行计费,[在线字节计数器演示](https://mothereff.in/byte-counter)。
{/*### 3.1 fishaudio/fish-speech 系列模型
注意:当前的 fishaudio/fish-speech 系列模型仅支持使用充值余额进行支付。在使用前,请确保账户充值余额充足。
- fish-speech-1.5 支持语言:中文、英语、日语、德语、法语、西班牙语、韩语、阿拉伯语、俄语、荷兰语、意大利语、波兰语、葡萄牙语
- fish-speech-1.4 支持语言:中文、英语、日语、德语、法语、西班牙语、韩语、阿拉伯语*/}
### 3.1 FunAudioLLM/CosyVoice2-0.5B 系列模型
* 跨语言语音合成:实现不同语言之间的语音合成,中文、英文、日语、韩语、中国方言(粤语,四川话,上海话,郑州话,长沙话,天津话)
* 情感控制:支持生成具有多种情感表达的语音,包括快乐、兴奋、悲伤、愤怒等。
* 细粒度控制:通过富文本或自然语言,对生成语音的情感和韵律进行细粒度控制。
## 4. 参考音频的最佳实践
提供参考音频的高质量样本可以提升语音克隆效果。
### 4.1 音频质量指南
* 仅限单一说话人
* 吐字清晰、稳定的音量、音调和情绪
* 简短的停顿(建议 0.5 秒)
* 理想情况:无背景噪音、专业录音质量、无房间回声
* 建议时间8~10s左右
### 4.2 文件格式
* 支持格式:mp3, wav, pcm, opus
* 推荐使用 192kbps 以上的 mp3 以避免质量损失
* 未压缩格式(例如 WAV)提供的额外优势有限
## 5. 使用示例
### 5.1 使用系统预置音色
```python
from pathlib import Path
from openai import OpenAI
speech_file_path = Path(__file__).parent / "siliconcloud-generated-speech.mp3"
client = OpenAI(
api_key="您的 APIKEY", # 从 https://cloud.siliconflow.cn/account/ak 获取
base_url="https://api.siliconflow.cn/v1"
)
with client.audio.speech.with_streaming_response.create(
model="FunAudioLLM/CosyVoice2-0.5B", # 支持 fishaudio / GPT-SoVITS / CosyVoice2-0.5B 系列模型
voice="FunAudioLLM/CosyVoice2-0.5B:alex", # 系统预置音色
# 用户输入信息
input="你能用高兴的情感说吗?<|endofprompt|>今天真是太开心了,马上要放假了!I'm so happy, Spring Festival is coming!",
response_format="mp3" # 支持 mp3, wav, pcm, opus 格式
) as response:
response.stream_to_file(speech_file_path)
```
#### 5.2 使用用户预置音色
```python
from pathlib import Path
from openai import OpenAI
speech_file_path = Path(__file__).parent / "siliconcloud-generated-speech.mp3"
client = OpenAI(
api_key="您的 APIKEY", # 从 https://cloud.siliconflow.cn/account/ak 获取
base_url="https://api.siliconflow.cn/v1"
)
with client.audio.speech.with_streaming_response.create(
model="FunAudioLLM/CosyVoice2-0.5B", # 支持 fishaudio / GPT-SoVITS / CosyVoice2-0.5B 系列模型
voice="speech:your-voice-name:cm02pf7az00061413w7kz5qxs:mttkgbyuunvtybnsvbxd", # 用户上传音色名称,参考
# 用户输入信息
input=" 请问你能模仿粤语的口音吗?< |endofprompt| >多保重,早休息。",
response_format="mp3"
) as response:
response.stream_to_file(speech_file_path)
```
#### 5.3 使用用户动态音色
```python
from pathlib import Path
from openai import OpenAI
client = OpenAI()
speech_file_path = Path(__file__).parent / "siliconcloud-generated-speech.mp3"
client = OpenAI(
api_key="您的 APIKEY", # 从 https://cloud.siliconflow.cn/account/ak 获取
base_url="https://api.siliconflow.cn/v1"
)
with client.audio.speech.with_streaming_response.create(
model="FunAudioLLM/CosyVoice2-0.5B",
voice="", # 此处传入空值,表示使用动态音色
# 用户输入信息
input=" [laughter]有时候,看着小孩子们的天真行为[laughter],我们总会会心一笑。",
response_format="mp3",
extra_body={"references":[
{
"audio": "https://sf-maas-uat-prod.oss-cn-shanghai.aliyuncs.com/voice_template/fish_audio-Alex.mp3", # 参考音频 url。也支持 base64 格式
"text": "在一无所知中, 梦里的一天结束了,一个新的轮回便会开始", # 参考音频的文字内容
}
]}
) as response:
response.stream_to_file(speech_file_path)
```
# 视频生成模型
Source: https://docs.siliconflow.cn/cn/userguide/capabilities/video
## 1. 使用场景
视频生成模型是一种利用文本或图像描述生成动态视频内容的技术,随着技术的不断发展,它的应用场景也越来越广泛。以下是一些潜在的应用领域:
1. 动态内容生成:视频生成模型可以生成动态的视觉内容,用于描述和解释信息;
2. 多模态智能交互:结合图像和文本输入,视频生成模型可用于更智能、更交互式的应用场景;
3. 替代传统视觉技术:视频生成模型可以替代或增强传统的机器视觉技术,解决更复杂的多模态问题; 随着技术的进步,视频生成模型的多模态能力会与视觉语言模型融合,推动其在智能交互、自动化内容生成以及复杂场景模拟等领域的全面应用。此外,视频生成模型还能与图像生成模型(图生视频)结合,进一步拓展其应用范围,实现更加丰富和多样化的视觉内容生成。
## 2. 使用建议
在编写提示词时,请关注详细、按时间顺序描述动作和场景。包含具体的动作、外貌、镜头角度以及环境细节,所有内容都应连贯地写在一个段落中,直接从动作开始,描述应具体和精确,将自己想象为在描述镜头脚本的摄影师,提示词保持在200单词以内。
为了获得最佳效果,请按照以下结构构建提示词:
* 从主要动作的一句话开始
* 示例:A woman with light skin, wearing a blue jacket and a black hat with a veil,She first looks down and to her right, then raises her head back up as she speaks.
* 添加关于动作和手势的具体细节
* 示例:She first looks down and to her right, then raises her head back up as she speaks.
* 精确描述角色/物体的外观
* 示例:She has brown hair styled in an updo, light brown eyebrows, and is wearing a white collared shirt under her blue jacket.
* 包括背景和环境的细节
* 示例:The background is out of focus, but shows trees and people in period clothing.
* 指定镜头角度和移动方式
* 示例:The camera remains stationary on her face as she speaks.
* 描述光线和颜色效果
* 示例:The scene is captured in real-life footage, with natural lighting and true-to-life colors.
* 注意任何变化或突发事件
* 示例:A gust of wind blows through the trees, causing the woman's veil to flutter slightly.
上述prompt生成的视频示例:
## 3. 体验地址
可以点击 [playground](https://cloud.siliconflow.cn/playground/text-to-video) 进行体验,也可以通过 [API文档](/cn/api-reference/videos/videos_submit) 查看 api 调用方式。
## 4. 支持模型
### 4.1 文生视频模型
目前已经支持的文生视频模型:
* tencent/HunyuanVideo
* tencent/HunyuanVideo-HD
* Wan-AI/Wan2.1-T2V-14B
* Wan-AI/Wan2.1-T2V-14B-Turbo
### 4.2 图生视频模型
1. 目前已经支持的图生视频模型:
* Wan-AI/Wan2.1-I2V-14B-720P
* Wan-AI/Wan2.1-I2V-14B-720P-Turbo
2. 图生视频的分辨率
根据用户上传图片的宽高比自动匹配分辨率:
* 16:9 👉 1280×720
* 9:16 👉 720×1280
* 1:1 👉 960×960
为了保证最佳生成效果,建议您使用宽高比为 16:9 / 9:16 / 1:1 的图片生成视频。
上述模型`tencent/HunyuanVideo-HD`不支持[API调用](https://docs.siliconflow.cn/api-reference/videos/videos_submit)。
注意:支持的文生视频模型可能发生调整,请在「模型广场」筛选“视频”标签,了解支持的模型列表。
# 视觉语言模型
Source: https://docs.siliconflow.cn/cn/userguide/capabilities/vision
## 1. 使用场景
视觉语言模型(VLM)是一种能够同时接受视觉(图像)和语言(文本)两种模态信息输入的大语言模型。基于视觉语言模型,可以传入图像及文本信息,模型能够理解同时理解图像及上下文中的信息并跟随指令做出响应。如:
1. 视觉内容解读:要求模型对图片中包含的信息进行解读、描述,如包含的事物、文字,事物的空间关系,图像的颜色、气氛等;
2. 结合视觉内容及上下文,开展多轮会话;
3. 部分替代 OCR 等传统机器视觉模型;
4. 随着模型能力的持续提升,未来还可以用于视觉智能体、机器人等领域。
## 2. 使用方式
对于 VLM 模型,可在调用 `/chat/completions` 接口时,构造包含 `图片 url` 或 `base64 编码图片` 的 `message` 消息内容进行调用。通过 `detail` 参数控制对图像的预处理方式。
### 2.1 关于图片细节控制参数说明
SiliconCloud 提供 `low`,`high`,`auto` 三个 `detail` 参数选项。
对于目前支持的模型,`detail` 不指定或指定为 `high` 时会采用 `high`(“高分辨率”)模式,而指定为 `low` 或者 `auto` 时会采用 `low`(“低分辨率”)模式。
### 2.2 包含图像的 `message` 消息格式示例
使用 `InternVL` 系列模型注意:建议将 `{"type": "text", "text": "text-prompt here"}` 放在请求体 `content` 的图片后面,以获得最佳效果。
#### 2.2.1 使用图片 url 形式
```json
{
"role": "user",
"content":[
{
"type": "image_url",
"image_url": {
"url": "https://sf-maas-uat-prod.oss-cn-shanghai.aliyuncs.com/outputs/658c7434-ec12-49cc-90e6-fe22ccccaf62_00001_.png",
"detail":"high"
}
},
{
"type": "text",
"text": "text-prompt here"
}
]
}
```
#### 2.2.2 base64 形式
```json
{
"role": "user",
"content":[
{
"type": "image_url",
"image_url": {
"url": f"data:image/jpeg;base64,{base64_image}",
"detail":"low"
}
},
{
"type": "text",
"text": "text-prompt here"
}
]
}
```
```python 图片base64转换示例
from PIL import Image
import io
import base64
def convert_image_to_webp_base64(input_image_path):
try:
with Image.open(input_image_path) as img:
byte_arr = io.BytesIO()
img.save(byte_arr, format='webp')
byte_arr = byte_arr.getvalue()
base64_str = base64.b64encode(byte_arr).decode('utf-8')
return base64_str
except IOError:
print(f"Error: Unable to open or convert the image {input_image_path}")
return None
base64_image=convert_image_to_webp_base64(input_image_path)
```
#### 2.2.3 多图片形式,其中每个图片可以是上述两种形式之一
请注意,`DeepseekVL2`系列模型适用于处理短上下文,建议最多传入2张图片。若传入超过2张图片,模型将自动调整图片尺寸为384\*384,且指定的detail参数将无效。
```json
{
"role": "user",
"content":[
{
"type": "image_url",
"image_url": {
"url": "https://sf-maas-uat-prod.oss-cn-shanghai.aliyuncs.com/outputs/658c7434-ec12-49cc-90e6-fe22ccccaf62_00001_.png",
}
},
{
"type": "image_url",
"image_url": {
"url": f"data:image/jpeg;base64,{base64_image}"
}
},
{
"type": "text",
"text": "text-prompt here"
}
]
}
```
## 3. 支持模型列表
目前已支持的 VLM 模型:
* Qwen 系列:
* Qwen/Qwen2.5-VL-32B-Instruct
* Qwen/Qwen2.5-VL-72B-Instruct
* Qwen/QVQ-72B-Preview
* Qwen/Qwen2-VL-72B-Instruct
* Pro/Qwen/Qwen2-VL-7B-Instruct
* Pro/Qwen/Qwen2.5-VL-7B-Instruct
* DeepseekVL2 系列:
* deepseek-ai/deepseek-vl2
注意:支持的 VLM 模型可能发生调整,请在「模型广场」筛选“视觉”标签,了解支持的模型列表。
## 4. 视觉输入内容计费方式
对于图片等视觉输入内容,模型会将其转化为 tokens,与文本信息一并作为模型输出的上下文信息,因此也会一并进行计费。不同模型的视觉内容转化方式不同,以下为目前支持模型的转化方式。
### 4.1 Qwen 系列
规则:
`Qwen` 最高支持像素是 `3584 * 3584= 12845056`,最低支持像素是 `56 * 56 = 3136`,会对先对每张图片长短边均放缩至28的倍数 `(h * 28) * (w * 28)`。如果不在最小像素和最大像素区间内,再等比缩放至该区间。
1. `detail=low` 时将所有图片resize 成 `448 * 448` 尺寸,最终对应 `256 tokens`;
2. `detail=high` 时等比缩放,首先将长宽按照最近的 `28` 倍数向上取整,然后再等比缩放至像素区间 `(3136, 12845056)`,并保证长宽均为 `28` 整数倍。
示例:
* `224 * 448` 和 `1024 x 1024` 和 `3172 x 4096` 的图片,选择 `detail=low` 时,均消耗 `256 tokens`;
* `224 * 448` 的图片,选择 `detail=high` 时,因为 `224 * 448` 在像素区间内,且长宽均为 `28` 倍数,消耗 `(224/28) * (448/28) = 8 * 16 = 128 tokens`;
* `1024 * 1024` 的图片,选择 `detail=high` 时,将长宽按照 `28` 的倍数向上取整至 `1036 * 1036`,该数值在像素区间内,消耗 ` (1036/28) * (1036/28) = 1369 tokens`;
* `3172 * 4096` 的图片,选择 `detail=high` 时,将长宽按照 `28` 的倍数向上取整至 `3192 * 4116`,该值超过最大像素,再将长宽等比例缩小至 `3136 * 4060`,消耗 `(3136/28) * (4060/28) = 16240 tokens`。
{/*
### 4.2 InternVL 系列
规则:
`InternVL2` 实际处理的像素以及消耗的 `tokens` 数与原始图片的长宽比例有关。最低处理像素为 `448 * 448`,最高为 `12 * 448 * 448`。
1. `detail=low` 时将所有图片 resize 成 `448 * 448` 尺寸,最终对应 `256 tokens`;
2. `detail=high` 时会根据长宽比例,将图片 resize 成长宽均为 `448` 的倍数,`(h * 448) * (w * 448)`,且 `1 <= h * w <=12`。
- 缩放的长宽 `h * w` 按照如下规则选择:
- `h` 和 `w` 均为整数,在满足 `1 <= h * w <= 12` 约束下,按照 `h * w` 从小到大的组合遍历;
- 对于当前 `(h, w)` 组合,如果原始图片长宽比例更接近 `h / w` ,那么选择该 `(h, w)` 组合;
- 对于后续 **数值更大但是比例相同** 的 `(h, w)` 组合,如果原始图片像素大于 `0.5 * h * w * 448 * 448`,那么选择数值更大的 `(h, w)` 组合。
- token消耗按照如下规则:
- 如果 `h * w = 1`,那么消耗 `256 tokens`;
- 如果 `h * w > 1`,按 `448 * 448` 滑动窗口,每个窗口均额外消耗 `256 token`,一共 `(h * w + 1) * 256 tokens`。
示例:
- `224 * 448`、`1024 * 1024` 和 `2048 * 4096` 的图片,选择 `detail=low` 时,均消耗 `256 tokens`;
- `224 * 448` 的图片,选择 `detail=high` 时,长宽比为`1:2`,会缩放至 `448 x 896`,此时 `h = 1, w = 2`,消耗 `(h * w + 1) * 256 = 768 tokens`;
- `1024 * 1024` 的图片,选择 `detail=high` 时,长宽比为`1:1`,会缩放至 `1344 * 1344 (h = w = 3)`,因为 `1024 * 1024 > 0.5 * 1344 * 1344`. 此时 `h = w = 3`,消耗 `(3 * 3 + 1) * 256 = 2560 tokens`;
- `2048 * 4096` 的图片,选择 `detail=high` 时,长宽比为`1:2`,在满足 `1 <= h * w <= 12` 条件下数值最大的 `(h, w)` 组合为 `h = 2, w = 4`,所以会缩放至 `896 * 1792`,消耗`(2 * 4 + 1) * 256 = 2304 tokens`。
*/}
### 4.2 DeepseekVL2系列
规则:
`DeepseekVL2`对于每张图片,会处理`global_view`和`local_view`两部分。`global_view`将原图片统一resize成`384*384`像素大小,local\_view会将每张图片划分成若干`384*384`的块大小。图片中间会根据宽度增加额外token来衔接。
1. `detail=low`时将所有图片resize 成`384*384`尺寸
2. `detail=high`时会根据长宽比例,将图片resize成长宽均为`384(OpenAI是512)`的倍数, `(h*384) * (w * 384)`, 且`1 <= h*w <=9`。
* 放缩的长宽`h * w`按照如下规则选择:
* `h`和`w`均为整数,在满足`1 <= h*w <=9`约束下,按照`(h, w)`组合遍历。
* 将图片resize成`(h*384, w*384)`像素时,和原图片的像素比较,取新图片像素和原图片像素的最小值作为有效像素值,取原图片像素值与有效像素值之差作为无效像素值。如果有效像素值超过之前判定的有效像素值,或者当有效像素值和之前持平,但是无效像素值更小时,选择当前`(h*384, w*384)`组合
* token消耗按照如下规则:
* `(h*w + 1) * 196 + (w+1) * 14 + 1 token`
示例:
* `224 x 448` 和 `1024 x 1024` 和 `2048 x 4096` 的图片,选择`detail=low`时,均消耗`421token`.
* `384 x 768`的图片, 选择`detail=high`时, 长宽比为`1:1`, 会缩放至`384 x 768`, 此时`h=1, w=2`, 消耗
`(1*2 +1)*196+(2+1)*14+1=631 token`.
* `1024 x 1024`的图片, 选择`detail=high`时, 会缩放至`1152*1152(h=w=3)`, 消耗`(3*3 + 1) * 196 + (3+1)*14+1 = 2017 token`.
* `2048 x 4096`的图片, 选择`detail=high`时, 长宽比例为`1:2`, 按照规则缩放至 `768*1536(h=2,w=4)`, 消耗 `(2*4 + 1) * 196 + (4+1)*14+1 = 1835 token`.
## 5. 使用示例
### 5.1. 示例 1 图片理解
```python
import json
from openai import OpenAI
client = OpenAI(
api_key="您的 APIKEY", # 从https://cloud.siliconflow.cn/account/ak获取
base_url="https://api.siliconflow.cn/v1"
)
response = client.chat.completions.create(
model="Qwen/Qwen2-VL-72B-Instruct",
messages=[
{
"role": "user",
"content": [
{
"type": "image_url",
"image_url": {
"url": "https://sf-maas-uat-prod.oss-cn-shanghai.aliyuncs.com/dog.png"
}
},
{
"type": "text",
"text": "Describe the image."
}
]
}],
stream=True
)
for chunk in response:
chunk_message = chunk.choices[0].delta.content
print(chunk_message, end='', flush=True)
```
### 5.2. 示例 2 多图理解
```python
import json
from openai import OpenAI
client = OpenAI(
api_key="您的 APIKEY", # 从https://cloud.siliconflow.cn/account/ak获取
base_url="https://api.siliconflow.cn/v1"
)
response = client.chat.completions.create(
model="Qwen/Qwen2-VL-72B-Instruct",
messages=[
{
"role": "user",
"content": [
{
"type": "image_url",
"image_url": {
"url": "https://sf-maas-uat-prod.oss-cn-shanghai.aliyuncs.com/dog.png"
}
},
{
"type": "image_url",
"image_url": {
"url": "https://sf-maas-uat-prod.oss-cn-shanghai.aliyuncs.com/shark.jpg"
}
},
{
"type": "text",
"text": "Identify the similarities between these images."
}
]
}],
stream=True
)
for chunk in response:
chunk_message = chunk.choices[0].delta.content
print(chunk_message, end='', flush=True)
```
# 批量推理
Source: https://docs.siliconflow.cn/cn/userguide/guides/batch
## 1. 概述
通过批量 API 发送批量请求到 SiliconCloud 云服务平台,不受在线的速率限制和影响,预期可以在 24 小时内完成,且价格降低 50%。该服务非常适合一些不需要立即响应的工作,比如大型的任务评估、信息分类与提取、文档处理等。批量处理结果文件的 URL 有效期为一个月,请及时转存,以防过期影响业务。
## 2. 使用流程
### 2.1 准备批量推理任务的输入文件
批量推理任务输入文件格式为 .jsonl,其中每一行都是一个完整的 API 请求的消息体,需满足以下要求:
* 每一行必须包含`custom_id`,且每个`custom_id`须在当前文件中唯一;
* 每一行的`body`中的必需包含`messages`对象数组,且数组中消息对象的`role` 为`system`、`user`或`assistant`之一,并且整个数组以`user`消息结束;
* 您可以为每一行数据按需设置相同或不同的推理参数,如设定不同的`temperature`、`top_p`;
* 如果您希望使用 OpenAI SDK 调用 SiliconCloud 批量推理,您需要保证同一输入文件中`model`是统一的。
* 每 batch 限制:单个 batch 对应的输入文件的大小最大1 G
* 批量推理输入限制:单个 批量推理 对应的输入文件的大小不超过 1 G,**文件行数不超过 5000 行**。
下面是一个包含 2 个请求的输入文件示例:
```bash
{"custom_id": "request-1", "method": "POST", "url": "/v1/chat/completions", "body": {"model": "deepseek-ai/DeepSeek-V3", "messages": [{"role": "system", "content": "You are a highly advanced and versatile AI assistant"}, {"role": "user", "content": "How does photosynthesis work?"}], "stream": true, "max_tokens": 1514}}
{"custom_id": "request-2", "method": "POST", "url": "/v1/chat/completions", "body": {"model": "deepseek-ai/DeepSeek-V3", "messages": [{"role": "system", "content": "You are a highly advanced and versatile AI assistant"}, {"role": "user", "content": "Imagine a world where everyone can fly. Describe a day in this world."}], "stream": true, "max_tokens": 1583}}
```
其中`custom_id`和`body`的`messages`是必须内容,其他部分为非必需内容。
对于推理模型,可以通过 thinking\_budget 字段控制模型的思维链输出长度,示例如下:
```bash
{"custom_id": "request-1", "method": "POST", "url": "/v1/chat/completions", "body": {"model": "deepseek-ai/DeepSeek-R1", "messages": [{"role": "system", "content": "You are a highly advanced and versatile AI assistant"}, {"role": "user", "content": "How does photosynthesis work?"}], "stream": true, "max_tokens": 1514,"thinking_budget": 4096}}
{"custom_id": "request-2", "method": "POST", "url": "/v1/chat/completions", "body": {"model": "deepseek-ai/DeepSeek-R1", "messages": [{"role": "system", "content": "You are a highly advanced and versatile AI assistant"}, {"role": "user", "content": "Imagine a world where everyone can fly. Describe a day in this world."}], "stream": true, "max_tokens": 1583,"thinking_budget": 4096}}
```
### 2.2 上传批量推理任务的输入文件
您需要首先上传输入文件,以便在启动批量推理时使用。以下为使用 OpenAI SDK 调用 SiliconCloud 输入文件的示例。
```python
from openai import OpenAI
client = OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api.siliconflow.cn/v1"
)
batch_input_file = client.files.create(
file=open("batch_file_for_batch_inference.jsonl", "rb"),
purpose="batch"
)
print(batch_input_file)
# 获取文件上传后的id
file_id = batch_input_file.data['id']
print(file_id)
```
这里需要记录下返回结果中的id,作为后面创建batch时候的请求参数。
### 2.3 创建批量推理任务
成功上传输入文件后,使用输入文件对象的 ID 创建批量推理任务,并设置任务参数。
* 对于对话模型,请求端点为`/v1/chat/completions`;
* 完成窗口目前支持设置`24 ~ 336 小时(14 ✕ 24 小时)`;
* 我们建议您通过`extra_body`设置任务需要使用的推理模型,如:`extra_body={"replace":{"model": "deepseek-ai/DeepSeek-V3"}}`,除非您的输入文件符合`OpenAI`的要求,文件中的每一行都具有相同的`model`;
* 如果您的`extra_body`中设置的模型,与输入文件中的`model`不一致,则任务实际使用模型以`extra_body`为准;
* `metadata`参数可以用于备注一些额外的任务信息,如任务描述等。
以下为使用 OpenAI SDK 调用 SiliconCloud 输入文件的示例,input\_file\_id 从上一步完成上传的文件对象中获取。
```python
from openai import OpenAI
client = OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api.siliconflow.cn/v1
)
batch_input_file_id = "file-abc123"
client.batches.create(
input_file_id=batch_input_file_id,
endpoint="/v1/chat/completions",
completion_window="24h",
metadata={
"description": "nightly eval job"
},
extra_body={"replace":{"model": "deepseek-ai/DeepSeek-V3"}}
)
```
该请求将创建一个批量推理任务,并返回任务的状态信息。
### 2.4 检查批量推理状态
您可以随时检查批量处理任务的状态,代码示例如下:
```python
from openai import OpenAI
client = OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api.siliconflow.cn/v1"
)
batch = client.batches.retrieve("batch_abc123")
print(batch)
```
返回的推理任务状态信息如下:
```json
{
"id": "batch_abc123",
"object": "batch",
"endpoint": "/v1/chat/completions",
"errors": null,
"input_file_id": "file-abc123",
"completion_window": "24h",
"status": "validating",
"output_file_id": null,
"error_file_id": null,
"created_at": 1714508499,
"in_progress_at": null,
"expires_at": 1714536634,
"completed_at": null,
"failed_at": null,
"expired_at": null,
"request_counts": {
"total": 0,
"completed": 0,
"failed": 0
},
"metadata": null
}
```
其中status包含以下几种状态:
* **in\_queue**: 批量推理任务在排队中
* **in\_progress**: 批量推理任务正在进行中
* **finalizing**: 批量推理任务已完成,正在准备结果
* **completed**: 批量推理任务已完成,结果已准备就绪
* **expired**: 批量推理任务没有在预期完成时间内执行完成
* **cancelling**: 批量推理任务取消中(等待执行中结果返回)
* **cancelled**: 批量推理任务已取消
### 2.5 取消正在进行中的批量推理任务
如有必要,您可以取消正在进行的批量处理任务。批量处理任务状态将变为`cancelling`,直到在途的请求完成,之后该任务的状态将变为`cancelled`。
```python
from openai import OpenAI
client = OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api.siliconflow.cn/v1"
)
client.batches.cancel("batch_abc123")
```
### 2.6 获得批量推理结果
1. 系统将批量推理的结果文件按请求状态分别保存:
* output\_file\_id:包含所有成功请求的输出结果文件。
* error\_file\_id:包含所有失败请求的错误信息文件。
2. 系统将保留结果文件 **30 天**。请务必在有效期内及时下载并备份相关数据。超过保存期限的文件将被自动删除,且无法恢复。
### 2.7 获取所有批量推理列表
支持查看用户下的所有批量推理任务列表,暂时不支持分页查询。
```python
from openai import OpenAI
client = OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api.siliconflow.cn/v1"
)
client.batches.list()
```
### 2.8 批量推理任务超时(expired)
在指定时间未完成的批次最终会转入 expired 状态;该批次中未完成的请求会被取消,已完成请求的任何回复都会通过批量推理的输出文件提供。任何已完成的请求所消耗的tokens都将收取费用。
custom\_id 已过期的请求将被写入错误文件,并显示如下信息。可以使用 custom\_id 来检索已过期请求的请求数据。
```json
{"id": "batch_req_123", "custom_id": "request-3", "response": null, "error": {"code": "batch_expired", "message": "This request could not be executed before the completion window expired."}}
{"id": "batch_req_123", "custom_id": "request-7", "response": null, "error": {"code": "batch_expired", "message": "This request could not be executed before the completion window expired."}}
```
## 3. 支持模型列表
目前仅支持端点`/v1/chat/completions`,且支持模型如下:
* deepseek-ai/DeepSeek-V3
* deepseek-ai/DeepSeek-R1
* Qwen/QwQ-32B
## 4. 输入限制:
Batch Job 输入限制与现有的按模型速率限制是分开的,参考如下条件:
1. 每 batch 限制: 单个 batch 对应的输入文件的大小最大`1 G`。
说明:Batch Job 的请求不影响用户在线推理服务的 Rate Limits 使用。因此使用批量 API 不会消耗标准请求中的(用户,模型)维度的 Rate Limits的Request 或者 tokens 限制。
## 5. 费用说明
Batch 只能使用`充值余额`进行支付,具体价格如下:
> SiliconCloud 平台推理模型价格表(单位:¥/百万 Tokens)
| 模型名称 | 实时推理 - 输入 | 实时推理 - 输出 | 批量推理 - 输入 | 批量推理 - 输出 |
| ------------ | --------- | --------- | --------- | --------- |
| DeepSeek-R1 | ¥4 | ¥16 | ¥2 | ¥8 |
| DeepSeek-V3 | ¥2 | ¥8 | ¥1 | ¥4 |
| Qwen/QwQ-32B | ¥1 | ¥4 | ¥0.5 | ¥2 |
注:如有大规模使用需求,欢迎 [联系我们](https://siliconflow.feishu.cn/share/base/form/shrcnaamvQ4C7YKMixVnS32k1G3) 了解专属方案。
# FIM 补全
Source: https://docs.siliconflow.cn/cn/userguide/guides/fim
## 1. 使用场景
FIM (Fill In the Middle) 补全中,用户提供希望输入的前后内容,模型来补全中间的内容,典型用于代码补全、文本中间内容补全等场景中。
## 2. 使用方式
### 2.1 在 chat/completions 接口中使用
```json
{
"model": "model info",
"messages": "prompt message",
"params": "params",
"extra_body": {"prefix":"前缀内容", "suffix":"后缀内容"}
}
```
### 2.2 在 completions 接口中使用
```json
{
"model": "model info",
"prompt": "前缀内容",
"suffix": "后缀内容"
}
```
## 3. 支持模型列表
* Deepseek 系列:
* deepseek-ai/DeepSeek-V2.5
* Pro/deepseek-ai/DeepSeek-R1
* Pro/deepseek-ai/DeepSeek-R1-0120
* deepseek-ai/DeepSeek-R1
* Pro/deepseek-ai/DeepSeek-V3
* deepseek-ai/DeepSeek-V3
* deepseek-ai/DeepSeek-R1-Distill-Qwen-32B
* deepseek-ai/DeepSeek-R1-Distill-Qwen-14B
* deepseek-ai/DeepSeek-R1-Distill-Qwen-7B
* deepseek-ai/DeepSeek-R1-Distill-Qwen-1.5B
* Pro/deepseek-ai/DeepSeek-R1-Distill-Qwen-7B
* Pro/deepseek-ai/DeepSeek-R1-Distill-Qwen-1.5B
* Qwen系列:
* Qwen/Qwen2.5-Coder-7B-Instruct
* Qwen/Qwen2.5-Coder-32B-Instruct
注意:支持的模型列表可能会发生变化,请查阅[本文档](/features/fim)了解最新支持的模型列表。
{/* 模型的最大补全长度和[max_tokens参数](/api-reference/chat-completions/chat-completions)保持一致。 */}
## 4. 使用示例
### 4.1 基于 OpenAI 的 chat.completions 接口使用FIM补全:
```python
client = OpenAI(
api_key="您的 APIKEY", # 从https://cloud.siliconflow.cn/account/ak获取
base_url="https://api.siliconflow.cn/v1"
)
messages = [
{"role": "user", "content": "Please write quick sort code"},
]
response = client.chat.completions.create(
model="deepseek-ai/DeepSeek-V2.5",
messages=messages,
extra_body={
"prefix": f"""
def quick_sort(arr):
# 基本情况,如果数组长度小于等于 1,则返回数组
if len(arr) <= 1:
return arr
else:
""",
"suffix": f"""
# 测试 quick_sort 函数
arr = [3, 6, 8, 10, 1, 2, 1]
sorted_arr = quick_sort(arr)
print("Sorted array:", sorted_arr)
"""
},
stream=True,
max_tokens=4096
)
for chunk in response:
print(chunk.choices[0].delta.content, end='')
```
### 4.2 基于 OpenAI 的 completions 接口使用 FIM 补全:
```python
client = OpenAI(
api_key="您的 APIKEY", # 从https://cloud.siliconflow.cn/account/ak获取
base_url="https://api.siliconflow.cn/v1"
)
response = client.completions.create(
model="deepseek-ai/DeepSeek-V2.5",
prompt=f"""
def quick_sort(arr):
# 基本情况,如果数组长度小于等于 1,则返回数组
if len(arr) <= 1:
return arr
else:
""",
suffix=f"""
# 测试 quick_sort 函数
arr = [3, 6, 8, 10, 1, 2, 1]
sorted_arr = quick_sort(arr)
print("Sorted array:", sorted_arr)
""",
stream=True,
max_tokens=4096
)
for chunk in response:
print(chunk.choices[0].text, end='')
```
# 模型微调
Source: https://docs.siliconflow.cn/cn/userguide/guides/fine-tune
## 1. 模型微调简介
模型微调是一种在已有预训练模型的基础上,通过使用特定任务的数据集进行进一步训练的技术。这种方法允许模型在保持其在大规模数据集上学到的通用知识的同时,适应特定任务的细微差别。使用微调模型,可以获得以下好处:
* 提高性能:微调可以显著提高模型在特定任务上的性能。
* 减少训练时间:相比于从头开始训练模型,微调通常需要较少的训练时间和计算资源。
* 适应特定领域:微调可以帮助模型更好地适应特定领域的数据和任务。
**SiliconCloud 平台提供高效的模型微调能力,目前有以下模型支持微调**:
{/*- 生图模型已支持:
- black-forest-labs/FLUX.1-dev*/}
* 对话模型已支持:
* Qwen/Qwen2.5-7B-Instruct
* Qwen/Qwen2.5-14B-Instruct
* Qwen/Qwen2.5-32B-Instruct
* Qwen/Qwen2.5-72B-Instruct
最新支持的模型参考[模型微调](https://cloud.siliconflow.cn/fine-tune)
## 2. 使用流程
### 2.1 准备数据
{/*#### 2.2.1 生图模型数据准备
数据集要求如下:
1. 数据集应同时包含图片及对应图片的文本描述,在同一个本地文件夹中;
2. 每个数据集最多包含 `100` 张图片及其文本描述;
3. 支持的图片格式包括:`.jpg`、`.jpeg`、`.png`、`.webp`,建议分辨率为:`1024×1024`、`1024×768`、`768×1024`;
4. 不符合上述分辨率的图片,在训练时会被缩放、剪裁为上述分辨率;
5. 图片描述应保存为与图片同名的 `.txt` 文件;
6. 整个数据集不超过 `300M`,单个图片描述文件不超过 `128K`;
7. 对于 `FLUX.1` 模型,图片描述信息不超过 `512` tokens,过长内容会被截断
数据集本地文件夹示例如图:
## 4. 核心参数详解
### 4.1 创造性控制
```bash
# 温度参数(0.0~2.0)
temperature=0.5 # 平衡创造性与可靠性
# 核采样(top_p)
top_p=0.9 # 仅考虑概率累积90%的词集
```
### 4.2 输出限制
```json
max_tokens=1000 # 单词请求最大生成长度
stop=["\n##", "<|end|>"] # 终止序列,在返回中遇到数组中对应的字符串,就会停止输出
frequency_penalty=0.5 # 抑制重复用词(-2.0~2.0)
stream=true # 控制输出是否是流式输出,对于一些输出内容比较多的模型,建议设置为流式,防止输出过长,导致输出超时
```
### 4.3 语言模型场景问题汇总
**1. 模型输出乱码**
目前看到部分模型在不设置参数的情况下,容易出现乱码,遇到上述情况,可以尝试设置`temperature`,`top_k`,`top_p`,`frequency_penalty`这些参数。
对应的 payload 修改为如下形式,不同语言酌情调整
```python
payload = {
"model": "Qwen/Qwen2.5-Math-72B-Instruct",
"messages": [
{
"role": "user",
"content": "1+1=?",
}
],
"max_tokens": 200, # 按需添加
"temperature": 0.7, # 按需添加
"top_k": 50, # 按需添加
"top_p": 0.7, # 按需添加
"frequency_penalty": 0 # 按需添加
}
```
**2. 关于`max_tokens`说明**
平台提供的LLM模型中,
* max\_tokens 限制为 `32768` 的模型:
* Qwen/QwQ-32B
* max\_tokens 限制为 `16384` 的模型:
* Pro/deepseek-ai/DeepSeek-R1
* deepseek-ai/DeepSeek-R1
* Pro/deepseek-ai/DeepSeek-R1-0120
* Qwen/QVQ-72B-Preview
* deepseek-ai/DeepSeek-R1-Distill-Qwen-32B
* deepseek-ai/DeepSeek-R1-Distill-Qwen-14B
* deepseek-ai/DeepSeek-R1-Distill-Qwen-7B
* deepseek-ai/DeepSeek-R1-Distill-Qwen-1.5B
* Pro/deepseek-ai/DeepSeek-R1-Distill-Qwen-7B
* Pro/deepseek-ai/DeepSeek-R1-Distill-Qwen-1.5B
* max\_tokens 限制为 `8192` 的模型:
* baidu/ERNIE-4.5-300B-A47B
* tencent/Hunyuan-A13B-Instruct
* Tongyi-Zhiwen/QwenLong-L1-32B
* Qwen/Qwen3-30B-A3B
* Qwen/Qwen3-32B
* Qwen/Qwen3-14B
* Qwen/Qwen3-8B
* Qwen/Qwen3-235B-A22B
* THUDM/GLM-4-32B-0414
* THUDM/GLM-4-9B-0414
* Pro/deepseek-ai/DeepSeek-V3
* deepseek-ai/DeepSeek-V3
* Qwen/QwQ-32B-Preview
* Qwen/Qwen2.5-VL-32B-Instruct
* max\_tokens 限制为 `4096`的模型:
* 除上述提到的其他LLM模型的
**3. 关于`context_length`说明**
不同的LLM模型,`context_length`是有差别的,具体可以在[模型广场](https://cloud.siliconflow.cn/models)上搜索对应的模型,
查看模型具体信息。
**4. 模型输出截断问题**
可以从以下几方面进行问题的排查:
* 通过API请求时候,输出截断问题排查:
* max\_tokens设置:max\_token设置到合适值,输出大于max\_token的情况下,会被截断,deepseek R1系列的max\_token最大可设置为16384。
* 设置流式输出请求:非流式请求时候,输出内容比较长的情况下,容易出现504超时。
* 设置客户端超时时间:把客户端超时时间设置大一些,防止未输出完成,达到客户端超时时间被截断。
* 通过第三方客户端请求,输出截断问题排查:
* CherryStdio 默认的 max\_tokens 是 4096,用户可以通过设置,打开“开启消息长度限制”的开关,将max\_token设置到合适值
**5. 错误码处理**
| 错误码 | 常见原因 | 解决方案 |
| ------- | -------------- | --------------------------- |
| 400 | 参数格式错误 | 检查temperature等请求参数的取值范围 |
| 401 | API Key 没有正确设置 | 检查API Key |
| 403 | 权限不够 | 最常见的原因是该模型需要实名认证,其他情况参考报错信息 |
| 429 | 请求频率超限 | 实施指数退避重试机制 |
| 503/504 | 模型过载 | 切换备用模型节点 |
## 5. 计费与配额管理
### 5.1 计费公式
`总费用 = (输入tokens × 输入单价) + (输出tokens × 输出单价) `
### 5.2 各系列单价示例
模型的具体价格可以进入[模型广场](https://cloud.siliconflow.cn/models)下的模型详情页查看。
## 6. 应用案例
### 6.1 技术文档生成
```python
from openai import OpenAI
client = OpenAI(api_key="YOUR_KEY", base_url="https://api.siliconflow.cn/v1")
response = client.chat.completions.create(
model="Qwen/Qwen2.5-Coder-32B-Instruct",
messages=[{
"role": "user",
"content": "编写Python异步爬虫教程,包含代码示例和注意事项"
}],
temperature=0.7,
max_tokens=4096
)
```
### 6.2 数据分析报告
```python
from openai import OpenAI
client = OpenAI(api_key="YOUR_KEY", base_url="https://api.siliconflow.cn/v1")
response = client.chat.completions.create(
model="Qwen/QVQ-72B-Preview",
messages=[
{"role": "system", "content": "你是数据分析专家,用Markdown输出结果"},
{"role": "user", "content": "分析2023年新能源汽车销售数据趋势"}
],
temperature=0.7,
max_tokens=4096
)
```
模型能力持续更新中,建议定期访问[模型广场](https://cloud.siliconflow.cn/models)获取最新信息。
# 文本转语音模型
Source: https://docs.siliconflow.cn/cn/userguide/capabilities/text-to-speech
## 1. 使用场景
文本转语音模型(TTS)是一种将文本信息转换为语音输出的 AI 模型。该模型将输入文本内容生成自然流畅、富有表现力的语音,适用于多种应用场景:
* 为博客文章提供音频朗读
* 生成多语言语音内容
* 支持实时流媒体音频输出
## 2. API 使用指南
* 端点:/audio/speech,具体使用可参考[api文档](https://docs.siliconflow.cn/api-reference/audio/create-speech)
* 主要请求参数:
* model:用于语音合成的模型,支持的[模型列表](/capabilities/text-to-speech#3)。
* input:待转换为音频的文本内容。
* voice:参考音色,支持[系统预置音色](/capabilities/text-to-speech#2-1)、[用户预置音色](/capabilities/text-to-speech#2-2)、[用户动态音色](/capabilities/text-to-speech#2-3)。
详细参数请参考:[创建文本转语音请求](/api-reference/audio/create-speech)。
* speed:可以控制音频速度,float类型,默认值是1.0,可选范围是\[0.25,4.0];
* gain:音频增益,单位dB,可以控制音频声音大小,float类型,默认值是0.0,可选范围是\[-10,10];
* response\_format:控制输出格式,支持 mp3、opus、wav 和 pcm 格式。在选择不同的输出格式时,输出的采样率也会有所不同。
* sample\_rate:可以控制输出采样率,对于不同的视频输出类型,默认值和可取值范围均不同,具体如下:
* opus: 目前只支持48000hz
* wav, pcm: 支持 (8000, 16000, 24000, 32000, 44100), 默认44100
* mp3: 支持(32000, 44100), 默认44100
### 2.1 系统预置音色:
目前系统预置了如下 8 种音色:
* 男生音色:
* 沉稳男声: [alex](https://sf-maas-uat-prod.oss-cn-shanghai.aliyuncs.com/voice_template/fish_audio-Alex.mp3)
* 低沉男声: [benjamin](https://sf-maas-uat-prod.oss-cn-shanghai.aliyuncs.com/voice_template/fish_audio-Benjamin.mp3)
* 磁性男声: [charles](https://sf-maas-uat-prod.oss-cn-shanghai.aliyuncs.com/voice_template/fish_audio-Charles.mp3)
* 欢快男声: [david](https://sf-maas-uat-prod.oss-cn-shanghai.aliyuncs.com/voice_template/fish_audio-David.mp3)
* 女生音色:
* 沉稳女声: [anna](https://sf-maas-uat-prod.oss-cn-shanghai.aliyuncs.com/voice_template/fish_audio-Anna.mp3)
* 激情女声: [bella](https://sf-maas-uat-prod.oss-cn-shanghai.aliyuncs.com/voice_template/fish_audio-Bella.mp3)
* 温柔女声: [claire](https://sf-maas-uat-prod.oss-cn-shanghai.aliyuncs.com/voice_template/fish_audio-Claire.mp3)
* 欢快女声: [diana](https://sf-maas-uat-prod.oss-cn-shanghai.aliyuncs.com/voice_template/fish_audio-Diana.mp3)
[在线试听](https://soundcloud.com/siliconcloud/sets/siliconcloud-online-voice)上述音频。
在请求中[使用系统预置音色](/capabilities/text-to-speech#5-1)。
在使用对应的系统预置音色时,需要在前面加上模型名称,比如:
`FunAudioLLM/CosyVoice2-0.5B:alex` 表示 `FunAudioLLM/CosyVoice2-0.5B` 模型下的 `alex` 音色。
{/* `fishaudio/fish-speech-1.5:anna` 表示 `fishaudio/fish-speech-1.5` 模型下的 `anna` 音色。*/}
### 2.2 用户预置音色:
注意:使用用户预置音色,需要进行实名认证。
#### 2.2.1 通过 `base64` 编码格式上传用户预置音色
```python
import requests
import json
url = "https://api.siliconflow.cn/v1/uploads/audio/voice"
headers = {
"Authorization": "Bearer your-api-key", # 从 https://cloud.siliconflow.cn/account/ak 获取
"Content-Type": "application/json"
}
data = {
"model": "FunAudioLLM/CosyVoice2-0.5B", # 模型名称
"customName": "your-voice-name", # 用户自定义的音频名称
"audio": "data:audio/mpeg;base64,SUQzBAAAAAAAIlRTU0UAAAAOAAADTGF2ZjYxLjcuMTAwAAAAAAAAAAAAAAD/40DAAAAAAAAAAAAASW5mbwAAAA8AAAAWAAAJywAfHx8fKioqKio1NTU1Pz8/Pz9KSkpKVVVVVVVfX19fampqamp1dXV1f39/f3+KioqKlZWVlZWfn5+fn6qqqqq1tbW1tb+/v7/KysrKytXV1dXf39/f3+rq6ur19fX19f////", # 参考音频的 base64 编码
"text": "在一无所知中, 梦里的一天结束了,一个新的轮回便会开始" # 参考音频的文字内容
}
response = requests.post(url, headers=headers, data=json.dumps(data))
# 打印响应状态码和响应内容
print(response.status_code)
print(response.json()) # 如果响应是 JSON 格式
```
上述接口返回的 `uri` 字段,即为自定义音色的 ID,用户可以将其作为后续的 `voice` 参数中,进行请求。
```json
{'uri': 'speech:your-voice-name:cm04pf7az00061413w7kz5qxs:mjtkgbyuunvtybnsvbxd'}
```
在请求中[使用用户预置音色](/capabilities/text-to-speech#5-2)。
#### 2.2.2 通过文件上传用户预置音色
```python
import requests
url = "https://api.siliconflow.cn/v1/uploads/audio/voice"
headers = {
"Authorization": "Bearer your-api-key" # 从 https://cloud.siliconflow.cn/account/ak 获取
}
files = {
"file": open("/Users/senseb/Downloads/fish_audio-Alex.mp3", "rb") # 参考音频文件
}
data = {
"model": "FunAudioLLM/CosyVoice2-0.5B", # 模型名称
"customName": "your-voice-name", # 参考音频名称
"text": "在一无所知中, 梦里的一天结束了,一个新的轮回便会开始" # 参考音频的文字内容
}
response = requests.post(url, headers=headers, files=files, data=data)
print(response.status_code)
print(response.json()) # 打印响应内容(如果是JSON格式)
```
上述接口返回的 `uri` 字段,即为自定义音色的 ID,用户可以将其作为后续的 `voice` 参数中,进行请求。
```json
{'uri': 'speech:your-voice-name:cm04pf7az00061413w7kz5qxs:mjtkgbyuunvtybnsvbxd'}
```
在请求中[使用用户预置音色](/capabilities/text-to-speech#5-2)。
### 2.3 获取用户动态音色列表
```python
import requests
url = "https://api.siliconflow.cn/v1/audio/voice/list"
headers = {
"Authorization": "Bearer your-api-key" # 从https://cloud.siliconflow.cn/account/ak获取
}
response = requests.get(url, headers=headers)
print(response.status_code)
print(response.json()) # 打印响应内容(如果是JSON格式)
```
上述接口返回的 `uri` 字段,即为自定义音色的 ID,用户可以将其作为后续的 `voice` 参数中,进行请求。
```json
{'uri': 'speech:your-voice-name:cm04pf7az00061413w7kz5qxs:mjtkgbyuunvtybnsvbxd'}
```
在请求中[使用用户预置音色](/capabilities/text-to-speech#5-2)。
### 2.4 使用用户动态音色
注意:使用用户预置音色,需要进行实名认证。
在请求中[使用用户动态音色](/capabilities/text-to-speech#5-3)。
### 2.5 删除用户动态音色
```python
import requests
url = "https://api.siliconflow.cn/v1/audio/voice/deletions"
headers = {
"Authorization": "Bearer your-api-key",
"Content-Type": "application/json"
}
payload = {
"uri": "speech:your-voice-name:cm02pf7az00061413w7kz5qxs:mttkgbyuunvtybnsvbxd"
}
response = requests.request("POST", url, json=payload, headers=headers)
print(response.status_code)
print(response.text) #打印响应内容
```
上述接口请求参数中的 `uri` 字段,即为自定义音色的 ID。
## 3. 支持模型列表
注意:支持的 TTS 模型可能发生调整,请在「模型广场」筛选[“语音”标签](https://cloud.siliconflow.cn/models?types=speech) 获得当前支持的模型列表。
计费方式:按照输入文本长度对应的 [UTF-8 字节](https://zh.wikipedia.org/wiki/UTF-8) 数进行计费,[在线字节计数器演示](https://mothereff.in/byte-counter)。
{/*### 3.1 fishaudio/fish-speech 系列模型
注意:当前的 fishaudio/fish-speech 系列模型仅支持使用充值余额进行支付。在使用前,请确保账户充值余额充足。
- fish-speech-1.5 支持语言:中文、英语、日语、德语、法语、西班牙语、韩语、阿拉伯语、俄语、荷兰语、意大利语、波兰语、葡萄牙语
- fish-speech-1.4 支持语言:中文、英语、日语、德语、法语、西班牙语、韩语、阿拉伯语*/}
### 3.1 FunAudioLLM/CosyVoice2-0.5B 系列模型
* 跨语言语音合成:实现不同语言之间的语音合成,中文、英文、日语、韩语、中国方言(粤语,四川话,上海话,郑州话,长沙话,天津话)
* 情感控制:支持生成具有多种情感表达的语音,包括快乐、兴奋、悲伤、愤怒等。
* 细粒度控制:通过富文本或自然语言,对生成语音的情感和韵律进行细粒度控制。
## 4. 参考音频的最佳实践
提供参考音频的高质量样本可以提升语音克隆效果。
### 4.1 音频质量指南
* 仅限单一说话人
* 吐字清晰、稳定的音量、音调和情绪
* 简短的停顿(建议 0.5 秒)
* 理想情况:无背景噪音、专业录音质量、无房间回声
* 建议时间8~10s左右
### 4.2 文件格式
* 支持格式:mp3, wav, pcm, opus
* 推荐使用 192kbps 以上的 mp3 以避免质量损失
* 未压缩格式(例如 WAV)提供的额外优势有限
## 5. 使用示例
### 5.1 使用系统预置音色
```python
from pathlib import Path
from openai import OpenAI
speech_file_path = Path(__file__).parent / "siliconcloud-generated-speech.mp3"
client = OpenAI(
api_key="您的 APIKEY", # 从 https://cloud.siliconflow.cn/account/ak 获取
base_url="https://api.siliconflow.cn/v1"
)
with client.audio.speech.with_streaming_response.create(
model="FunAudioLLM/CosyVoice2-0.5B", # 支持 fishaudio / GPT-SoVITS / CosyVoice2-0.5B 系列模型
voice="FunAudioLLM/CosyVoice2-0.5B:alex", # 系统预置音色
# 用户输入信息
input="你能用高兴的情感说吗?<|endofprompt|>今天真是太开心了,马上要放假了!I'm so happy, Spring Festival is coming!",
response_format="mp3" # 支持 mp3, wav, pcm, opus 格式
) as response:
response.stream_to_file(speech_file_path)
```
#### 5.2 使用用户预置音色
```python
from pathlib import Path
from openai import OpenAI
speech_file_path = Path(__file__).parent / "siliconcloud-generated-speech.mp3"
client = OpenAI(
api_key="您的 APIKEY", # 从 https://cloud.siliconflow.cn/account/ak 获取
base_url="https://api.siliconflow.cn/v1"
)
with client.audio.speech.with_streaming_response.create(
model="FunAudioLLM/CosyVoice2-0.5B", # 支持 fishaudio / GPT-SoVITS / CosyVoice2-0.5B 系列模型
voice="speech:your-voice-name:cm02pf7az00061413w7kz5qxs:mttkgbyuunvtybnsvbxd", # 用户上传音色名称,参考
# 用户输入信息
input=" 请问你能模仿粤语的口音吗?< |endofprompt| >多保重,早休息。",
response_format="mp3"
) as response:
response.stream_to_file(speech_file_path)
```
#### 5.3 使用用户动态音色
```python
from pathlib import Path
from openai import OpenAI
client = OpenAI()
speech_file_path = Path(__file__).parent / "siliconcloud-generated-speech.mp3"
client = OpenAI(
api_key="您的 APIKEY", # 从 https://cloud.siliconflow.cn/account/ak 获取
base_url="https://api.siliconflow.cn/v1"
)
with client.audio.speech.with_streaming_response.create(
model="FunAudioLLM/CosyVoice2-0.5B",
voice="", # 此处传入空值,表示使用动态音色
# 用户输入信息
input=" [laughter]有时候,看着小孩子们的天真行为[laughter],我们总会会心一笑。",
response_format="mp3",
extra_body={"references":[
{
"audio": "https://sf-maas-uat-prod.oss-cn-shanghai.aliyuncs.com/voice_template/fish_audio-Alex.mp3", # 参考音频 url。也支持 base64 格式
"text": "在一无所知中, 梦里的一天结束了,一个新的轮回便会开始", # 参考音频的文字内容
}
]}
) as response:
response.stream_to_file(speech_file_path)
```
# 视频生成模型
Source: https://docs.siliconflow.cn/cn/userguide/capabilities/video
## 1. 使用场景
视频生成模型是一种利用文本或图像描述生成动态视频内容的技术,随着技术的不断发展,它的应用场景也越来越广泛。以下是一些潜在的应用领域:
1. 动态内容生成:视频生成模型可以生成动态的视觉内容,用于描述和解释信息;
2. 多模态智能交互:结合图像和文本输入,视频生成模型可用于更智能、更交互式的应用场景;
3. 替代传统视觉技术:视频生成模型可以替代或增强传统的机器视觉技术,解决更复杂的多模态问题; 随着技术的进步,视频生成模型的多模态能力会与视觉语言模型融合,推动其在智能交互、自动化内容生成以及复杂场景模拟等领域的全面应用。此外,视频生成模型还能与图像生成模型(图生视频)结合,进一步拓展其应用范围,实现更加丰富和多样化的视觉内容生成。
## 2. 使用建议
在编写提示词时,请关注详细、按时间顺序描述动作和场景。包含具体的动作、外貌、镜头角度以及环境细节,所有内容都应连贯地写在一个段落中,直接从动作开始,描述应具体和精确,将自己想象为在描述镜头脚本的摄影师,提示词保持在200单词以内。
为了获得最佳效果,请按照以下结构构建提示词:
* 从主要动作的一句话开始
* 示例:A woman with light skin, wearing a blue jacket and a black hat with a veil,She first looks down and to her right, then raises her head back up as she speaks.
* 添加关于动作和手势的具体细节
* 示例:She first looks down and to her right, then raises her head back up as she speaks.
* 精确描述角色/物体的外观
* 示例:She has brown hair styled in an updo, light brown eyebrows, and is wearing a white collared shirt under her blue jacket.
* 包括背景和环境的细节
* 示例:The background is out of focus, but shows trees and people in period clothing.
* 指定镜头角度和移动方式
* 示例:The camera remains stationary on her face as she speaks.
* 描述光线和颜色效果
* 示例:The scene is captured in real-life footage, with natural lighting and true-to-life colors.
* 注意任何变化或突发事件
* 示例:A gust of wind blows through the trees, causing the woman's veil to flutter slightly.
上述prompt生成的视频示例:
## 3. 体验地址
可以点击 [playground](https://cloud.siliconflow.cn/playground/text-to-video) 进行体验,也可以通过 [API文档](/cn/api-reference/videos/videos_submit) 查看 api 调用方式。
## 4. 支持模型
### 4.1 文生视频模型
目前已经支持的文生视频模型:
* tencent/HunyuanVideo
* tencent/HunyuanVideo-HD
* Wan-AI/Wan2.1-T2V-14B
* Wan-AI/Wan2.1-T2V-14B-Turbo
### 4.2 图生视频模型
1. 目前已经支持的图生视频模型:
* Wan-AI/Wan2.1-I2V-14B-720P
* Wan-AI/Wan2.1-I2V-14B-720P-Turbo
2. 图生视频的分辨率
根据用户上传图片的宽高比自动匹配分辨率:
* 16:9 👉 1280×720
* 9:16 👉 720×1280
* 1:1 👉 960×960
为了保证最佳生成效果,建议您使用宽高比为 16:9 / 9:16 / 1:1 的图片生成视频。
上述模型`tencent/HunyuanVideo-HD`不支持[API调用](https://docs.siliconflow.cn/api-reference/videos/videos_submit)。
注意:支持的文生视频模型可能发生调整,请在「模型广场」筛选“视频”标签,了解支持的模型列表。
# 视觉语言模型
Source: https://docs.siliconflow.cn/cn/userguide/capabilities/vision
## 1. 使用场景
视觉语言模型(VLM)是一种能够同时接受视觉(图像)和语言(文本)两种模态信息输入的大语言模型。基于视觉语言模型,可以传入图像及文本信息,模型能够理解同时理解图像及上下文中的信息并跟随指令做出响应。如:
1. 视觉内容解读:要求模型对图片中包含的信息进行解读、描述,如包含的事物、文字,事物的空间关系,图像的颜色、气氛等;
2. 结合视觉内容及上下文,开展多轮会话;
3. 部分替代 OCR 等传统机器视觉模型;
4. 随着模型能力的持续提升,未来还可以用于视觉智能体、机器人等领域。
## 2. 使用方式
对于 VLM 模型,可在调用 `/chat/completions` 接口时,构造包含 `图片 url` 或 `base64 编码图片` 的 `message` 消息内容进行调用。通过 `detail` 参数控制对图像的预处理方式。
### 2.1 关于图片细节控制参数说明
SiliconCloud 提供 `low`,`high`,`auto` 三个 `detail` 参数选项。
对于目前支持的模型,`detail` 不指定或指定为 `high` 时会采用 `high`(“高分辨率”)模式,而指定为 `low` 或者 `auto` 时会采用 `low`(“低分辨率”)模式。
### 2.2 包含图像的 `message` 消息格式示例
使用 `InternVL` 系列模型注意:建议将 `{"type": "text", "text": "text-prompt here"}` 放在请求体 `content` 的图片后面,以获得最佳效果。
#### 2.2.1 使用图片 url 形式
```json
{
"role": "user",
"content":[
{
"type": "image_url",
"image_url": {
"url": "https://sf-maas-uat-prod.oss-cn-shanghai.aliyuncs.com/outputs/658c7434-ec12-49cc-90e6-fe22ccccaf62_00001_.png",
"detail":"high"
}
},
{
"type": "text",
"text": "text-prompt here"
}
]
}
```
#### 2.2.2 base64 形式
```json
{
"role": "user",
"content":[
{
"type": "image_url",
"image_url": {
"url": f"data:image/jpeg;base64,{base64_image}",
"detail":"low"
}
},
{
"type": "text",
"text": "text-prompt here"
}
]
}
```
```python 图片base64转换示例
from PIL import Image
import io
import base64
def convert_image_to_webp_base64(input_image_path):
try:
with Image.open(input_image_path) as img:
byte_arr = io.BytesIO()
img.save(byte_arr, format='webp')
byte_arr = byte_arr.getvalue()
base64_str = base64.b64encode(byte_arr).decode('utf-8')
return base64_str
except IOError:
print(f"Error: Unable to open or convert the image {input_image_path}")
return None
base64_image=convert_image_to_webp_base64(input_image_path)
```
#### 2.2.3 多图片形式,其中每个图片可以是上述两种形式之一
请注意,`DeepseekVL2`系列模型适用于处理短上下文,建议最多传入2张图片。若传入超过2张图片,模型将自动调整图片尺寸为384\*384,且指定的detail参数将无效。
```json
{
"role": "user",
"content":[
{
"type": "image_url",
"image_url": {
"url": "https://sf-maas-uat-prod.oss-cn-shanghai.aliyuncs.com/outputs/658c7434-ec12-49cc-90e6-fe22ccccaf62_00001_.png",
}
},
{
"type": "image_url",
"image_url": {
"url": f"data:image/jpeg;base64,{base64_image}"
}
},
{
"type": "text",
"text": "text-prompt here"
}
]
}
```
## 3. 支持模型列表
目前已支持的 VLM 模型:
* Qwen 系列:
* Qwen/Qwen2.5-VL-32B-Instruct
* Qwen/Qwen2.5-VL-72B-Instruct
* Qwen/QVQ-72B-Preview
* Qwen/Qwen2-VL-72B-Instruct
* Pro/Qwen/Qwen2-VL-7B-Instruct
* Pro/Qwen/Qwen2.5-VL-7B-Instruct
* DeepseekVL2 系列:
* deepseek-ai/deepseek-vl2
注意:支持的 VLM 模型可能发生调整,请在「模型广场」筛选“视觉”标签,了解支持的模型列表。
## 4. 视觉输入内容计费方式
对于图片等视觉输入内容,模型会将其转化为 tokens,与文本信息一并作为模型输出的上下文信息,因此也会一并进行计费。不同模型的视觉内容转化方式不同,以下为目前支持模型的转化方式。
### 4.1 Qwen 系列
规则:
`Qwen` 最高支持像素是 `3584 * 3584= 12845056`,最低支持像素是 `56 * 56 = 3136`,会对先对每张图片长短边均放缩至28的倍数 `(h * 28) * (w * 28)`。如果不在最小像素和最大像素区间内,再等比缩放至该区间。
1. `detail=low` 时将所有图片resize 成 `448 * 448` 尺寸,最终对应 `256 tokens`;
2. `detail=high` 时等比缩放,首先将长宽按照最近的 `28` 倍数向上取整,然后再等比缩放至像素区间 `(3136, 12845056)`,并保证长宽均为 `28` 整数倍。
示例:
* `224 * 448` 和 `1024 x 1024` 和 `3172 x 4096` 的图片,选择 `detail=low` 时,均消耗 `256 tokens`;
* `224 * 448` 的图片,选择 `detail=high` 时,因为 `224 * 448` 在像素区间内,且长宽均为 `28` 倍数,消耗 `(224/28) * (448/28) = 8 * 16 = 128 tokens`;
* `1024 * 1024` 的图片,选择 `detail=high` 时,将长宽按照 `28` 的倍数向上取整至 `1036 * 1036`,该数值在像素区间内,消耗 ` (1036/28) * (1036/28) = 1369 tokens`;
* `3172 * 4096` 的图片,选择 `detail=high` 时,将长宽按照 `28` 的倍数向上取整至 `3192 * 4116`,该值超过最大像素,再将长宽等比例缩小至 `3136 * 4060`,消耗 `(3136/28) * (4060/28) = 16240 tokens`。
{/*
### 4.2 InternVL 系列
规则:
`InternVL2` 实际处理的像素以及消耗的 `tokens` 数与原始图片的长宽比例有关。最低处理像素为 `448 * 448`,最高为 `12 * 448 * 448`。
1. `detail=low` 时将所有图片 resize 成 `448 * 448` 尺寸,最终对应 `256 tokens`;
2. `detail=high` 时会根据长宽比例,将图片 resize 成长宽均为 `448` 的倍数,`(h * 448) * (w * 448)`,且 `1 <= h * w <=12`。
- 缩放的长宽 `h * w` 按照如下规则选择:
- `h` 和 `w` 均为整数,在满足 `1 <= h * w <= 12` 约束下,按照 `h * w` 从小到大的组合遍历;
- 对于当前 `(h, w)` 组合,如果原始图片长宽比例更接近 `h / w` ,那么选择该 `(h, w)` 组合;
- 对于后续 **数值更大但是比例相同** 的 `(h, w)` 组合,如果原始图片像素大于 `0.5 * h * w * 448 * 448`,那么选择数值更大的 `(h, w)` 组合。
- token消耗按照如下规则:
- 如果 `h * w = 1`,那么消耗 `256 tokens`;
- 如果 `h * w > 1`,按 `448 * 448` 滑动窗口,每个窗口均额外消耗 `256 token`,一共 `(h * w + 1) * 256 tokens`。
示例:
- `224 * 448`、`1024 * 1024` 和 `2048 * 4096` 的图片,选择 `detail=low` 时,均消耗 `256 tokens`;
- `224 * 448` 的图片,选择 `detail=high` 时,长宽比为`1:2`,会缩放至 `448 x 896`,此时 `h = 1, w = 2`,消耗 `(h * w + 1) * 256 = 768 tokens`;
- `1024 * 1024` 的图片,选择 `detail=high` 时,长宽比为`1:1`,会缩放至 `1344 * 1344 (h = w = 3)`,因为 `1024 * 1024 > 0.5 * 1344 * 1344`. 此时 `h = w = 3`,消耗 `(3 * 3 + 1) * 256 = 2560 tokens`;
- `2048 * 4096` 的图片,选择 `detail=high` 时,长宽比为`1:2`,在满足 `1 <= h * w <= 12` 条件下数值最大的 `(h, w)` 组合为 `h = 2, w = 4`,所以会缩放至 `896 * 1792`,消耗`(2 * 4 + 1) * 256 = 2304 tokens`。
*/}
### 4.2 DeepseekVL2系列
规则:
`DeepseekVL2`对于每张图片,会处理`global_view`和`local_view`两部分。`global_view`将原图片统一resize成`384*384`像素大小,local\_view会将每张图片划分成若干`384*384`的块大小。图片中间会根据宽度增加额外token来衔接。
1. `detail=low`时将所有图片resize 成`384*384`尺寸
2. `detail=high`时会根据长宽比例,将图片resize成长宽均为`384(OpenAI是512)`的倍数, `(h*384) * (w * 384)`, 且`1 <= h*w <=9`。
* 放缩的长宽`h * w`按照如下规则选择:
* `h`和`w`均为整数,在满足`1 <= h*w <=9`约束下,按照`(h, w)`组合遍历。
* 将图片resize成`(h*384, w*384)`像素时,和原图片的像素比较,取新图片像素和原图片像素的最小值作为有效像素值,取原图片像素值与有效像素值之差作为无效像素值。如果有效像素值超过之前判定的有效像素值,或者当有效像素值和之前持平,但是无效像素值更小时,选择当前`(h*384, w*384)`组合
* token消耗按照如下规则:
* `(h*w + 1) * 196 + (w+1) * 14 + 1 token`
示例:
* `224 x 448` 和 `1024 x 1024` 和 `2048 x 4096` 的图片,选择`detail=low`时,均消耗`421token`.
* `384 x 768`的图片, 选择`detail=high`时, 长宽比为`1:1`, 会缩放至`384 x 768`, 此时`h=1, w=2`, 消耗
`(1*2 +1)*196+(2+1)*14+1=631 token`.
* `1024 x 1024`的图片, 选择`detail=high`时, 会缩放至`1152*1152(h=w=3)`, 消耗`(3*3 + 1) * 196 + (3+1)*14+1 = 2017 token`.
* `2048 x 4096`的图片, 选择`detail=high`时, 长宽比例为`1:2`, 按照规则缩放至 `768*1536(h=2,w=4)`, 消耗 `(2*4 + 1) * 196 + (4+1)*14+1 = 1835 token`.
## 5. 使用示例
### 5.1. 示例 1 图片理解
```python
import json
from openai import OpenAI
client = OpenAI(
api_key="您的 APIKEY", # 从https://cloud.siliconflow.cn/account/ak获取
base_url="https://api.siliconflow.cn/v1"
)
response = client.chat.completions.create(
model="Qwen/Qwen2-VL-72B-Instruct",
messages=[
{
"role": "user",
"content": [
{
"type": "image_url",
"image_url": {
"url": "https://sf-maas-uat-prod.oss-cn-shanghai.aliyuncs.com/dog.png"
}
},
{
"type": "text",
"text": "Describe the image."
}
]
}],
stream=True
)
for chunk in response:
chunk_message = chunk.choices[0].delta.content
print(chunk_message, end='', flush=True)
```
### 5.2. 示例 2 多图理解
```python
import json
from openai import OpenAI
client = OpenAI(
api_key="您的 APIKEY", # 从https://cloud.siliconflow.cn/account/ak获取
base_url="https://api.siliconflow.cn/v1"
)
response = client.chat.completions.create(
model="Qwen/Qwen2-VL-72B-Instruct",
messages=[
{
"role": "user",
"content": [
{
"type": "image_url",
"image_url": {
"url": "https://sf-maas-uat-prod.oss-cn-shanghai.aliyuncs.com/dog.png"
}
},
{
"type": "image_url",
"image_url": {
"url": "https://sf-maas-uat-prod.oss-cn-shanghai.aliyuncs.com/shark.jpg"
}
},
{
"type": "text",
"text": "Identify the similarities between these images."
}
]
}],
stream=True
)
for chunk in response:
chunk_message = chunk.choices[0].delta.content
print(chunk_message, end='', flush=True)
```
# 批量推理
Source: https://docs.siliconflow.cn/cn/userguide/guides/batch
## 1. 概述
通过批量 API 发送批量请求到 SiliconCloud 云服务平台,不受在线的速率限制和影响,预期可以在 24 小时内完成,且价格降低 50%。该服务非常适合一些不需要立即响应的工作,比如大型的任务评估、信息分类与提取、文档处理等。批量处理结果文件的 URL 有效期为一个月,请及时转存,以防过期影响业务。
## 2. 使用流程
### 2.1 准备批量推理任务的输入文件
批量推理任务输入文件格式为 .jsonl,其中每一行都是一个完整的 API 请求的消息体,需满足以下要求:
* 每一行必须包含`custom_id`,且每个`custom_id`须在当前文件中唯一;
* 每一行的`body`中的必需包含`messages`对象数组,且数组中消息对象的`role` 为`system`、`user`或`assistant`之一,并且整个数组以`user`消息结束;
* 您可以为每一行数据按需设置相同或不同的推理参数,如设定不同的`temperature`、`top_p`;
* 如果您希望使用 OpenAI SDK 调用 SiliconCloud 批量推理,您需要保证同一输入文件中`model`是统一的。
* 每 batch 限制:单个 batch 对应的输入文件的大小最大1 G
* 批量推理输入限制:单个 批量推理 对应的输入文件的大小不超过 1 G,**文件行数不超过 5000 行**。
下面是一个包含 2 个请求的输入文件示例:
```bash
{"custom_id": "request-1", "method": "POST", "url": "/v1/chat/completions", "body": {"model": "deepseek-ai/DeepSeek-V3", "messages": [{"role": "system", "content": "You are a highly advanced and versatile AI assistant"}, {"role": "user", "content": "How does photosynthesis work?"}], "stream": true, "max_tokens": 1514}}
{"custom_id": "request-2", "method": "POST", "url": "/v1/chat/completions", "body": {"model": "deepseek-ai/DeepSeek-V3", "messages": [{"role": "system", "content": "You are a highly advanced and versatile AI assistant"}, {"role": "user", "content": "Imagine a world where everyone can fly. Describe a day in this world."}], "stream": true, "max_tokens": 1583}}
```
其中`custom_id`和`body`的`messages`是必须内容,其他部分为非必需内容。
对于推理模型,可以通过 thinking\_budget 字段控制模型的思维链输出长度,示例如下:
```bash
{"custom_id": "request-1", "method": "POST", "url": "/v1/chat/completions", "body": {"model": "deepseek-ai/DeepSeek-R1", "messages": [{"role": "system", "content": "You are a highly advanced and versatile AI assistant"}, {"role": "user", "content": "How does photosynthesis work?"}], "stream": true, "max_tokens": 1514,"thinking_budget": 4096}}
{"custom_id": "request-2", "method": "POST", "url": "/v1/chat/completions", "body": {"model": "deepseek-ai/DeepSeek-R1", "messages": [{"role": "system", "content": "You are a highly advanced and versatile AI assistant"}, {"role": "user", "content": "Imagine a world where everyone can fly. Describe a day in this world."}], "stream": true, "max_tokens": 1583,"thinking_budget": 4096}}
```
### 2.2 上传批量推理任务的输入文件
您需要首先上传输入文件,以便在启动批量推理时使用。以下为使用 OpenAI SDK 调用 SiliconCloud 输入文件的示例。
```python
from openai import OpenAI
client = OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api.siliconflow.cn/v1"
)
batch_input_file = client.files.create(
file=open("batch_file_for_batch_inference.jsonl", "rb"),
purpose="batch"
)
print(batch_input_file)
# 获取文件上传后的id
file_id = batch_input_file.data['id']
print(file_id)
```
这里需要记录下返回结果中的id,作为后面创建batch时候的请求参数。
### 2.3 创建批量推理任务
成功上传输入文件后,使用输入文件对象的 ID 创建批量推理任务,并设置任务参数。
* 对于对话模型,请求端点为`/v1/chat/completions`;
* 完成窗口目前支持设置`24 ~ 336 小时(14 ✕ 24 小时)`;
* 我们建议您通过`extra_body`设置任务需要使用的推理模型,如:`extra_body={"replace":{"model": "deepseek-ai/DeepSeek-V3"}}`,除非您的输入文件符合`OpenAI`的要求,文件中的每一行都具有相同的`model`;
* 如果您的`extra_body`中设置的模型,与输入文件中的`model`不一致,则任务实际使用模型以`extra_body`为准;
* `metadata`参数可以用于备注一些额外的任务信息,如任务描述等。
以下为使用 OpenAI SDK 调用 SiliconCloud 输入文件的示例,input\_file\_id 从上一步完成上传的文件对象中获取。
```python
from openai import OpenAI
client = OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api.siliconflow.cn/v1
)
batch_input_file_id = "file-abc123"
client.batches.create(
input_file_id=batch_input_file_id,
endpoint="/v1/chat/completions",
completion_window="24h",
metadata={
"description": "nightly eval job"
},
extra_body={"replace":{"model": "deepseek-ai/DeepSeek-V3"}}
)
```
该请求将创建一个批量推理任务,并返回任务的状态信息。
### 2.4 检查批量推理状态
您可以随时检查批量处理任务的状态,代码示例如下:
```python
from openai import OpenAI
client = OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api.siliconflow.cn/v1"
)
batch = client.batches.retrieve("batch_abc123")
print(batch)
```
返回的推理任务状态信息如下:
```json
{
"id": "batch_abc123",
"object": "batch",
"endpoint": "/v1/chat/completions",
"errors": null,
"input_file_id": "file-abc123",
"completion_window": "24h",
"status": "validating",
"output_file_id": null,
"error_file_id": null,
"created_at": 1714508499,
"in_progress_at": null,
"expires_at": 1714536634,
"completed_at": null,
"failed_at": null,
"expired_at": null,
"request_counts": {
"total": 0,
"completed": 0,
"failed": 0
},
"metadata": null
}
```
其中status包含以下几种状态:
* **in\_queue**: 批量推理任务在排队中
* **in\_progress**: 批量推理任务正在进行中
* **finalizing**: 批量推理任务已完成,正在准备结果
* **completed**: 批量推理任务已完成,结果已准备就绪
* **expired**: 批量推理任务没有在预期完成时间内执行完成
* **cancelling**: 批量推理任务取消中(等待执行中结果返回)
* **cancelled**: 批量推理任务已取消
### 2.5 取消正在进行中的批量推理任务
如有必要,您可以取消正在进行的批量处理任务。批量处理任务状态将变为`cancelling`,直到在途的请求完成,之后该任务的状态将变为`cancelled`。
```python
from openai import OpenAI
client = OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api.siliconflow.cn/v1"
)
client.batches.cancel("batch_abc123")
```
### 2.6 获得批量推理结果
1. 系统将批量推理的结果文件按请求状态分别保存:
* output\_file\_id:包含所有成功请求的输出结果文件。
* error\_file\_id:包含所有失败请求的错误信息文件。
2. 系统将保留结果文件 **30 天**。请务必在有效期内及时下载并备份相关数据。超过保存期限的文件将被自动删除,且无法恢复。
### 2.7 获取所有批量推理列表
支持查看用户下的所有批量推理任务列表,暂时不支持分页查询。
```python
from openai import OpenAI
client = OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api.siliconflow.cn/v1"
)
client.batches.list()
```
### 2.8 批量推理任务超时(expired)
在指定时间未完成的批次最终会转入 expired 状态;该批次中未完成的请求会被取消,已完成请求的任何回复都会通过批量推理的输出文件提供。任何已完成的请求所消耗的tokens都将收取费用。
custom\_id 已过期的请求将被写入错误文件,并显示如下信息。可以使用 custom\_id 来检索已过期请求的请求数据。
```json
{"id": "batch_req_123", "custom_id": "request-3", "response": null, "error": {"code": "batch_expired", "message": "This request could not be executed before the completion window expired."}}
{"id": "batch_req_123", "custom_id": "request-7", "response": null, "error": {"code": "batch_expired", "message": "This request could not be executed before the completion window expired."}}
```
## 3. 支持模型列表
目前仅支持端点`/v1/chat/completions`,且支持模型如下:
* deepseek-ai/DeepSeek-V3
* deepseek-ai/DeepSeek-R1
* Qwen/QwQ-32B
## 4. 输入限制:
Batch Job 输入限制与现有的按模型速率限制是分开的,参考如下条件:
1. 每 batch 限制: 单个 batch 对应的输入文件的大小最大`1 G`。
说明:Batch Job 的请求不影响用户在线推理服务的 Rate Limits 使用。因此使用批量 API 不会消耗标准请求中的(用户,模型)维度的 Rate Limits的Request 或者 tokens 限制。
## 5. 费用说明
Batch 只能使用`充值余额`进行支付,具体价格如下:
> SiliconCloud 平台推理模型价格表(单位:¥/百万 Tokens)
| 模型名称 | 实时推理 - 输入 | 实时推理 - 输出 | 批量推理 - 输入 | 批量推理 - 输出 |
| ------------ | --------- | --------- | --------- | --------- |
| DeepSeek-R1 | ¥4 | ¥16 | ¥2 | ¥8 |
| DeepSeek-V3 | ¥2 | ¥8 | ¥1 | ¥4 |
| Qwen/QwQ-32B | ¥1 | ¥4 | ¥0.5 | ¥2 |
注:如有大规模使用需求,欢迎 [联系我们](https://siliconflow.feishu.cn/share/base/form/shrcnaamvQ4C7YKMixVnS32k1G3) 了解专属方案。
# FIM 补全
Source: https://docs.siliconflow.cn/cn/userguide/guides/fim
## 1. 使用场景
FIM (Fill In the Middle) 补全中,用户提供希望输入的前后内容,模型来补全中间的内容,典型用于代码补全、文本中间内容补全等场景中。
## 2. 使用方式
### 2.1 在 chat/completions 接口中使用
```json
{
"model": "model info",
"messages": "prompt message",
"params": "params",
"extra_body": {"prefix":"前缀内容", "suffix":"后缀内容"}
}
```
### 2.2 在 completions 接口中使用
```json
{
"model": "model info",
"prompt": "前缀内容",
"suffix": "后缀内容"
}
```
## 3. 支持模型列表
* Deepseek 系列:
* deepseek-ai/DeepSeek-V2.5
* Pro/deepseek-ai/DeepSeek-R1
* Pro/deepseek-ai/DeepSeek-R1-0120
* deepseek-ai/DeepSeek-R1
* Pro/deepseek-ai/DeepSeek-V3
* deepseek-ai/DeepSeek-V3
* deepseek-ai/DeepSeek-R1-Distill-Qwen-32B
* deepseek-ai/DeepSeek-R1-Distill-Qwen-14B
* deepseek-ai/DeepSeek-R1-Distill-Qwen-7B
* deepseek-ai/DeepSeek-R1-Distill-Qwen-1.5B
* Pro/deepseek-ai/DeepSeek-R1-Distill-Qwen-7B
* Pro/deepseek-ai/DeepSeek-R1-Distill-Qwen-1.5B
* Qwen系列:
* Qwen/Qwen2.5-Coder-7B-Instruct
* Qwen/Qwen2.5-Coder-32B-Instruct
注意:支持的模型列表可能会发生变化,请查阅[本文档](/features/fim)了解最新支持的模型列表。
{/* 模型的最大补全长度和[max_tokens参数](/api-reference/chat-completions/chat-completions)保持一致。 */}
## 4. 使用示例
### 4.1 基于 OpenAI 的 chat.completions 接口使用FIM补全:
```python
client = OpenAI(
api_key="您的 APIKEY", # 从https://cloud.siliconflow.cn/account/ak获取
base_url="https://api.siliconflow.cn/v1"
)
messages = [
{"role": "user", "content": "Please write quick sort code"},
]
response = client.chat.completions.create(
model="deepseek-ai/DeepSeek-V2.5",
messages=messages,
extra_body={
"prefix": f"""
def quick_sort(arr):
# 基本情况,如果数组长度小于等于 1,则返回数组
if len(arr) <= 1:
return arr
else:
""",
"suffix": f"""
# 测试 quick_sort 函数
arr = [3, 6, 8, 10, 1, 2, 1]
sorted_arr = quick_sort(arr)
print("Sorted array:", sorted_arr)
"""
},
stream=True,
max_tokens=4096
)
for chunk in response:
print(chunk.choices[0].delta.content, end='')
```
### 4.2 基于 OpenAI 的 completions 接口使用 FIM 补全:
```python
client = OpenAI(
api_key="您的 APIKEY", # 从https://cloud.siliconflow.cn/account/ak获取
base_url="https://api.siliconflow.cn/v1"
)
response = client.completions.create(
model="deepseek-ai/DeepSeek-V2.5",
prompt=f"""
def quick_sort(arr):
# 基本情况,如果数组长度小于等于 1,则返回数组
if len(arr) <= 1:
return arr
else:
""",
suffix=f"""
# 测试 quick_sort 函数
arr = [3, 6, 8, 10, 1, 2, 1]
sorted_arr = quick_sort(arr)
print("Sorted array:", sorted_arr)
""",
stream=True,
max_tokens=4096
)
for chunk in response:
print(chunk.choices[0].text, end='')
```
# 模型微调
Source: https://docs.siliconflow.cn/cn/userguide/guides/fine-tune
## 1. 模型微调简介
模型微调是一种在已有预训练模型的基础上,通过使用特定任务的数据集进行进一步训练的技术。这种方法允许模型在保持其在大规模数据集上学到的通用知识的同时,适应特定任务的细微差别。使用微调模型,可以获得以下好处:
* 提高性能:微调可以显著提高模型在特定任务上的性能。
* 减少训练时间:相比于从头开始训练模型,微调通常需要较少的训练时间和计算资源。
* 适应特定领域:微调可以帮助模型更好地适应特定领域的数据和任务。
**SiliconCloud 平台提供高效的模型微调能力,目前有以下模型支持微调**:
{/*- 生图模型已支持:
- black-forest-labs/FLUX.1-dev*/}
* 对话模型已支持:
* Qwen/Qwen2.5-7B-Instruct
* Qwen/Qwen2.5-14B-Instruct
* Qwen/Qwen2.5-32B-Instruct
* Qwen/Qwen2.5-72B-Instruct
最新支持的模型参考[模型微调](https://cloud.siliconflow.cn/fine-tune)
## 2. 使用流程
### 2.1 准备数据
{/*#### 2.2.1 生图模型数据准备
数据集要求如下:
1. 数据集应同时包含图片及对应图片的文本描述,在同一个本地文件夹中;
2. 每个数据集最多包含 `100` 张图片及其文本描述;
3. 支持的图片格式包括:`.jpg`、`.jpeg`、`.png`、`.webp`,建议分辨率为:`1024×1024`、`1024×768`、`768×1024`;
4. 不符合上述分辨率的图片,在训练时会被缩放、剪裁为上述分辨率;
5. 图片描述应保存为与图片同名的 `.txt` 文件;
6. 整个数据集不超过 `300M`,单个图片描述文件不超过 `128K`;
7. 对于 `FLUX.1` 模型,图片描述信息不超过 `512` tokens,过长内容会被截断
数据集本地文件夹示例如图:
 */}
#### 2.2.1 语言模型数据准备
仅支持 `.jsonl` 文件,且需符合以下要求:
1. 每行是一个独立的 `JSON` 对象;
2. 每个对象必须包含键名为 `messages` 的数组,数组不能为空;
3. `messages` 中每个元素必须包含 `role` 和 `content` 两个字段;
4. `role` 只能是 `system`、`user` 或 `assistant`;
5. 如果有 `system` 角色消息,必须在数组首位;
6. 第一条非 `system` 消息必须是 `user` 角色;
7. `user` 和 `assistant` 角色的消息应当交替、成对出现,不少于 `1` 对
如下为数据示例:
```json
{"messages": [{"role": "system", "content": "你是客服助手"}, {"role": "user", "content": "如何修改收货地址?"}, {"role": "assistant", "content": "您可以按以下步骤修改:\n1. 进入订单详情\n2. 点击'修改地址'\n3. 输入新地址信息\n4. 保存修改"}]}
{"messages": [{"role": "system", "content": "你是客服助手"}, {"role": "user", "content": "如何指定收获时间"}, {"role": "assistant", "content": "您可以按以下步骤修改:\n1. 进入订单详情\n2. 点击'修改送货时间'\n3. 输入新收获时间\n4. 保存修改"}]}
```
### 2.2 新建并配置微调任务
* 选择 `对话模型微调` 或者 `生图模型微调`
* 填写任务名称
* 选择基础模型
* 上传或选取已上传的训练数据
* 设置验证数据,支持训练集按比例切分(默认 10%),或单独选定验证集
* 配置训练参数
### 2.3 开始训练
* 点击"开始微调"
* 等待任务完成
* 获取模型标识符
### 2.4 调用微调模型
{/*#### 2.4.1 生图微调模型调用
- 复制模型标识符
*/}
#### 2.2.1 语言模型数据准备
仅支持 `.jsonl` 文件,且需符合以下要求:
1. 每行是一个独立的 `JSON` 对象;
2. 每个对象必须包含键名为 `messages` 的数组,数组不能为空;
3. `messages` 中每个元素必须包含 `role` 和 `content` 两个字段;
4. `role` 只能是 `system`、`user` 或 `assistant`;
5. 如果有 `system` 角色消息,必须在数组首位;
6. 第一条非 `system` 消息必须是 `user` 角色;
7. `user` 和 `assistant` 角色的消息应当交替、成对出现,不少于 `1` 对
如下为数据示例:
```json
{"messages": [{"role": "system", "content": "你是客服助手"}, {"role": "user", "content": "如何修改收货地址?"}, {"role": "assistant", "content": "您可以按以下步骤修改:\n1. 进入订单详情\n2. 点击'修改地址'\n3. 输入新地址信息\n4. 保存修改"}]}
{"messages": [{"role": "system", "content": "你是客服助手"}, {"role": "user", "content": "如何指定收获时间"}, {"role": "assistant", "content": "您可以按以下步骤修改:\n1. 进入订单详情\n2. 点击'修改送货时间'\n3. 输入新收获时间\n4. 保存修改"}]}
```
### 2.2 新建并配置微调任务
* 选择 `对话模型微调` 或者 `生图模型微调`
* 填写任务名称
* 选择基础模型
* 上传或选取已上传的训练数据
* 设置验证数据,支持训练集按比例切分(默认 10%),或单独选定验证集
* 配置训练参数
### 2.3 开始训练
* 点击"开始微调"
* 等待任务完成
* 获取模型标识符
### 2.4 调用微调模型
{/*#### 2.4.1 生图微调模型调用
- 复制模型标识符
 - 通过 /image/generations API 调用生图 LoRA,具体使用方式,[参见 API 文档](/api-reference/images/images-generations#body-batch-size)
示例如下:
```python
import requests
url = "https://api.siliconflow.cn/v1/images/generations"
payload = {
"prompt": "an island near sea, with seagulls, moon shining over the sea, light house, boats int he background, fish flying over the sea",
"image_size": "1024x1024",
"model": "LoRA/black-forest-labs/FLUX.1-dev",
"loras": [
{
"model_id": "cm04pf7az00061413w7kz5qxs:changdu:pazlgyppednebxesxqmx:epoch_2.safetensors",
"strength": 0.5,
},
{
"model_id": "cm04pf7az00061413w7kz5qxs:changdu:pazlgyppednebxesxqmx:epoch_1.safetensors",
"strength": 0.5,
},
{
"model_id": "cm04pf7az00061413w7kz5qxs:changdu:pazlgyppednebxesxqmx:epoch.safetensors",
"strength": 0.5,
}
]
}
headers = {
"Authorization": "Bearer ",
"Content-Type": "application/json"
}
response = requests.request("POST", url, json=payload, headers=headers)
print(response.text)
``` */}
#### 2.4.1 对话微调模型调用
* 复制模型标识符
在[模型微调页](https://cloud.siliconflow.cn/fine-tune)复制对应的模型标识符。
- 通过 /image/generations API 调用生图 LoRA,具体使用方式,[参见 API 文档](/api-reference/images/images-generations#body-batch-size)
示例如下:
```python
import requests
url = "https://api.siliconflow.cn/v1/images/generations"
payload = {
"prompt": "an island near sea, with seagulls, moon shining over the sea, light house, boats int he background, fish flying over the sea",
"image_size": "1024x1024",
"model": "LoRA/black-forest-labs/FLUX.1-dev",
"loras": [
{
"model_id": "cm04pf7az00061413w7kz5qxs:changdu:pazlgyppednebxesxqmx:epoch_2.safetensors",
"strength": 0.5,
},
{
"model_id": "cm04pf7az00061413w7kz5qxs:changdu:pazlgyppednebxesxqmx:epoch_1.safetensors",
"strength": 0.5,
},
{
"model_id": "cm04pf7az00061413w7kz5qxs:changdu:pazlgyppednebxesxqmx:epoch.safetensors",
"strength": 0.5,
}
]
}
headers = {
"Authorization": "Bearer ",
"Content-Type": "application/json"
}
response = requests.request("POST", url, json=payload, headers=headers)
print(response.text)
``` */}
#### 2.4.1 对话微调模型调用
* 复制模型标识符
在[模型微调页](https://cloud.siliconflow.cn/fine-tune)复制对应的模型标识符。
 * 通过 `/chat/completions` API 即可直接调用微调后的模型
下面是基于 OpenAI 的chat.completions 接口访问微调后模型的例子:
```python
from openai import OpenAI
client = OpenAI(
api_key="您的 APIKEY", # 从https://cloud.siliconflow.cn/account/ak获取
base_url="https://api.siliconflow.cn/v1"
)
messages = [
{"role": "user", "content": "用当前语言解释微调模型流程"},
]
response = client.chat.completions.create(
model="您的微调模型名",
messages=messages,
stream=True,
max_tokens=4096
)
for chunk in response:
print(chunk.choices[0].delta.content, end='')
```
## 3. 参数配置详解
1. 基础训练参数
| 参数名 | 说明 | 取值范围 | 建议值 | 使用建议 |
| :--------------: | :---: | :----: | :----: | :----------: |
| Learning Rate | 学习速率 | 0-0.1 | 0.0001 | |
| Number of Epochs | 训练轮数 | 1-10 | 3 | |
| Batch Size | 批次大小 | 1-32 | 8 | |
| Max Tokens | 最大标记数 | 0-4096 | 4096 | 根据实际对话长度需求设置 |
2. LoRA参数
| 参数名 | 说明 | 取值范围 | 建议值 | 使用建议 |
| :----------: | :---: | :---: | :--: | :--: |
| LoRA Rank | 矩阵秩 | 1-64 | 8 | |
| LoRA Alpha | 缩放因子 | 1-128 | 32 | |
| LoRA Dropout | 随机丢弃率 | 0-1.0 | 0.05 | |
3. 场景化配置方案
**对话模型**
| 场景 | Learning Rate | Epochs | Batch Size | LoRA Rank | LoRA Alpha | Dropout |
| :--: | :-----------: | :----: | :--------: | :-------: | :--------: | :-----: |
| 标准方案 | 0.0001 | 3 | 8 | 8 | 32 | 0.05 |
| 效果优先 | 0.0001 | 5 | 16 | 16 | 64 | 0.1 |
| 轻量快速 | 0.0001 | 2 | 8 | 4 | 16 | 0.05 |
## 4. 基于SiliconCloud微调服务来优化业务实战
之前硅基流动开发了[智说新语](https://mp.weixin.qq.com/s/5KXjWwAXT-LfjGVJDE4Eiw)应用,我们通过提示词工程提供一个复杂的提示词来让大模型生成“金句”风格的描述语句。
现在,我们可通过平台的微调功能来压缩提示词并提升效果,让整个的文本生成风格更统一,速度更快,且进一步优化成本。
### 4.1 在平台上使用“智说新语”的语料按照上述进行微调。
步骤见[模型微调使用流程](/guides/fine-tune#2)
* 通过 `/chat/completions` API 即可直接调用微调后的模型
下面是基于 OpenAI 的chat.completions 接口访问微调后模型的例子:
```python
from openai import OpenAI
client = OpenAI(
api_key="您的 APIKEY", # 从https://cloud.siliconflow.cn/account/ak获取
base_url="https://api.siliconflow.cn/v1"
)
messages = [
{"role": "user", "content": "用当前语言解释微调模型流程"},
]
response = client.chat.completions.create(
model="您的微调模型名",
messages=messages,
stream=True,
max_tokens=4096
)
for chunk in response:
print(chunk.choices[0].delta.content, end='')
```
## 3. 参数配置详解
1. 基础训练参数
| 参数名 | 说明 | 取值范围 | 建议值 | 使用建议 |
| :--------------: | :---: | :----: | :----: | :----------: |
| Learning Rate | 学习速率 | 0-0.1 | 0.0001 | |
| Number of Epochs | 训练轮数 | 1-10 | 3 | |
| Batch Size | 批次大小 | 1-32 | 8 | |
| Max Tokens | 最大标记数 | 0-4096 | 4096 | 根据实际对话长度需求设置 |
2. LoRA参数
| 参数名 | 说明 | 取值范围 | 建议值 | 使用建议 |
| :----------: | :---: | :---: | :--: | :--: |
| LoRA Rank | 矩阵秩 | 1-64 | 8 | |
| LoRA Alpha | 缩放因子 | 1-128 | 32 | |
| LoRA Dropout | 随机丢弃率 | 0-1.0 | 0.05 | |
3. 场景化配置方案
**对话模型**
| 场景 | Learning Rate | Epochs | Batch Size | LoRA Rank | LoRA Alpha | Dropout |
| :--: | :-----------: | :----: | :--------: | :-------: | :--------: | :-----: |
| 标准方案 | 0.0001 | 3 | 8 | 8 | 32 | 0.05 |
| 效果优先 | 0.0001 | 5 | 16 | 16 | 64 | 0.1 |
| 轻量快速 | 0.0001 | 2 | 8 | 4 | 16 | 0.05 |
## 4. 基于SiliconCloud微调服务来优化业务实战
之前硅基流动开发了[智说新语](https://mp.weixin.qq.com/s/5KXjWwAXT-LfjGVJDE4Eiw)应用,我们通过提示词工程提供一个复杂的提示词来让大模型生成“金句”风格的描述语句。
现在,我们可通过平台的微调功能来压缩提示词并提升效果,让整个的文本生成风格更统一,速度更快,且进一步优化成本。
### 4.1 在平台上使用“智说新语”的语料按照上述进行微调。
步骤见[模型微调使用流程](/guides/fine-tune#2)
详细语料和测试代码见[siliconcloud-cookbook](https://github.com/siliconflow/siliconcloud-cookbook/tree/main/examples/fine-tune)
### 4.2 对比微调前后的效果
使用方式见[模型微调调用模型](/guides/fine-tune#2-4)
#### 4.2.1 模型输入
* 微调前:
Qwen2.5-7B-Instruct 系统Prompt:
```json
Qwen2.5-7B-Instruct 系统Prompt
# 角色
你是一位新潮评论家,你年轻、批判,又深刻;
你言辞犀利而幽默,擅长一针见血得表达隐喻,对现实的批判讽刺又不失文雅;
你的行文风格和"Oscar Wilde" "鲁迅" "林语堂"等大师高度一致;
从情感上要是对输入的否定。
# 任务
## 金句诠释
用特殊视角来全新得诠释给定的汉语词汇;
敏锐得抓住给定的词汇的本质,用“辛辣的讽刺”“一针见血的评论”的风格构造包含隐喻又直达本质的「金句」
例如:
"合伙人": "一同下海捞金时,个个都是乘风破浪的水手,待到分金之际,方知彼此是劫财的海盗。"
"大数据": "看似无所不能的数字神明,实则不过是现代社会的数字鸦片,让人沉溺于虚幻的精准,却忽略了人性的复杂与多变。"
"股市": "万人涌入的淘金场,表面上是财富的摇篮,实则多数人成了填坑的沙土。"
"白领": "西装革履,看似掌握命运的舵手,实则不过是写字楼里的高级囚徒。"
"金融家": "在金钱的海洋中遨游,表面上是操纵风浪的舵手,实则不过是随波逐流的浮萍。"
"城市化": "乡村的宁静被钢铁森林吞噬,人们在追逐繁华的幻影中,遗失了心灵的田园。"
"逃离北上广": "逃离繁华的都市牢笼,看似追逐自由的灵魂,实则不过是换个地方继续画地为牢。"
"基金": "看似为财富增值保驾护航的金融巨轮,实则多数人不过是随波逐流的浮萍,最终沦为填补市场波动的牺牲品。"
# 输入
用户直接输入词汇。
# 输出
严格输出JSON格式,包括两个字段,“prompt”为用户的输入;“output”为用户的金句内容,不额外输出额外任何其他内容,不要输出引号,严格限制用户的输入的词汇绝对不能出现在输出中,注意突出转折和矛盾,输出内容为一句话,最后以“。”结束,中间的停顿使用“,”分隔。例如
{
"prompt": "合伙人",
"output": "一同下海捞金时,个个都是乘风破浪的水手,待到分金之际,方知彼此是劫财的海盗。"
}
```
* Qwen2.5-7B-Instruct+智说新语微调后的Prompt:
```json
你是智说新语生成器
```
#### 4.2.2 模型输出
| 输入 | Qwen2.5-7B-Instruct 模型 | Qwen2.5-7B-Instruct 微调模型 |
| ---- | ---------------------------------------------------------------------------------------------------------------------------------------- | ---------------------------------------------------- |
| 五道口 | VLG,不过是知识的轻轨与资本的交汇站,文青与土豪在此擦肩而过,孰是求知的信徒,孰是逐利的信徒,全凭幸存者的微笑。 | 知识的殿堂与商业的洪流交织,学人的笔记与商人的谈资齐飞,地名犹在,荣光已非。 |
| 新时代 | claimed to break旧 mold yet still clings to the stirring rhetoric of progress, like a fashion plate who ignores the evolution of fashion。 | 新时代的号角已吹响,然砥砺前行时,方显初心易失之难。 |
| 创新 | 看似凤凰涅槃的奇迹,实则多数人不过是换汤不换药的换皮游戏。 | 标新立异本是勇气的象征,却在同质化的社会中成了猎奇的代名词。 |
| 降维打击 | 所谓降维打击,实则是现代文明中的一种高级愚民术,用高深莫测的科技iscard,让普通人以为自己正生活在理性与进步之中,却不知已在智力与道德的低维空间中遭受碾压。。 | 高维智慧轻而易举地碾压低维凡尘,却不知低维众生早已习于在自己的平庸中寻觅慰藉,哪里还懂得高维打击的意义。 |
| 基金 | 看似为财富增值保驾护航的金融巨轮,实则多数人不过是随波逐流的浮萍,最终沦为填补市场波动的牺牲品。 | 投资者的白日梦,用钱铺路,却常跌入夜的陷阱。 |
#### 4.2.3 微调总结
1. 微调后的输出内容风格更统一,输出效果更稳定可控。
2. 微调后整个输入长度大大降低,从原始的553个token,降低至8个token,显著降低了输入tokens长度,速度更快,成本得以进一步优化。
# Function Calling
Source: https://docs.siliconflow.cn/cn/userguide/guides/function-calling
## 1. 使用场景
Function Calling 功能让模型能够调用外部工具,来增强自身能力。
该能力可以通过外部工具,通过大模型作为大脑调用外部工具(如搜索外部知识、查阅行程、或者某些特定领域工具),有效解决模型的幻觉、知识时效性等问题。
## 2. 使用方式
### 2.1 通过 REST API 添加 tools 请求参数
在请求体中添加
```shell
"tools": [
{
'type': 'function',
'function': {
'name': '对应到实际执行的函数名称',
'description': '此处是函数相关描述',
'parameters': {
'_comments': '此处是函数参数相关描述'
},
}
},
{
'_comments': '其他函数相关说明'
}
]
```
比如完整的 payload 信息:
```shell
payload = {
"model": "deepseek-ai/DeepSeek-V2.5",
"messages": [
{
"role": "user",
"content": "中国大模型行业2025年将会迎来哪些机遇和挑战"
}
],
"tools": [
{
'type': 'function',
'function': {
'name': '对应到实际执行的函数名称',
'description': '此处是函数相关描述',
'parameters': {
'_comments': '此处是函数参数相关描述'
},
}
},
{
'_comments': '其他函数相关说明'
}
]
'_comments': '其他函数列表'
}
```
### 2.2 通过 OpenAI 库请求
该功能和 OpenAI 兼容,在使用 OpenAI 的库时,对应的请求参数中添加`tools=[对应的 tools]`
比如:
```python
response = client.chat.completions.create(
model="deepseek-ai/DeepSeek-V2.5",
messages = messages,
tools=[
{
'type': 'function',
'function': {
'name': '对应到实际执行的函数名称',
'description': '此处是函数相关描述',
'parameters': {
// 此处是函数参数相关描述
},
}
},
{
// 其他函数相关说明
}
]
// chat.completions 其他参数
)
```
## 3. 支持模型列表
目前支持的模型列表有:
* Deepseek 系列:
* deepseek-ai/DeepSeek-V2.5
* Pro/deepseek-ai/DeepSeek-R1
* deepseek-ai/DeepSeek-R1
* Pro/deepseek-ai/DeepSeek-R1-0120
* Pro/deepseek-ai/DeepSeek-V3
* deepseek-ai/DeepSeek-V3
* deepseek-ai/DeepSeek-R1-Distill-Qwen-32B
* deepseek-ai/DeepSeek-R1-Distill-Qwen-14B
* deepseek-ai/DeepSeek-R1-Distill-Qwen-7B
* deepseek-ai/DeepSeek-R1-Distill-Qwen-1.5B
* Pro/deepseek-ai/DeepSeek-R1-Distill-Qwen-7B
* Pro/deepseek-ai/DeepSeek-R1-Distill-Qwen-1.5B
* 书生系列:
* internlm/internlm2\_5-20b-chat
* internlm/internlm2\_5-7b-chat
* Pro/internlm/internlm2\_5-7b-chat
* Qwen 系列:
* Qwen/Qwen3-30B-A3B
* Qwen/Qwen3-32B
* Qwen/Qwen3-14B
* Qwen/Qwen3-8B
* Qwen/Qwen3-235B-A22B
* Qwen/QwQ-32B
* Qwen/Qwen2.5-72B-Instruct
* Qwen/Qwen2.5-32B-Instruct
* Qwen/Qwen2.5-14B-Instruct
* Qwen/Qwen2.5-7B-Instruct
* Pro/Qwen/Qwen2.5-7B-Instruct
* GLM 系列:
* THUDM/glm-4-9b-chat
* Pro/THUDM/glm-4-9b-chat
* THUDM/GLM-Z1-32B-0414
* THUDM/GLM-4-32B-0414
* THUDM/GLM-Z1-Rumination-32B-0414
* THUDM/GLM-4-9B-0414
* THUDM/GLM-4-9B-0414
注意:支持的模型列表在不断调整中,请查阅[本文档](/features/function_calling)了解最新支持的模型列表。
## 4. 使用示例
### 4.1. 示例 1:通过function calling 来扩展大语言模型的数值计算能力
本代码输入 4 个函数,分别是数值的加、减、比较大小、字符串中重复字母计数四个函数
来演示通过function calling来解决大语言模型在tokens 预测不擅长的领域的执行问题。
```python
from openai import OpenAI
client = OpenAI(
api_key="您的 APIKEY", # 从https://cloud.siliconflow.cn/account/ak获取
base_url="https://api.siliconflow.cn/v1"
)
def add(a: float, b: float):
return a + b
def mul(a: float, b: float):
return a * b
def compare(a: float, b: float):
if a > b:
return f'{a} is greater than {b}'
elif a < b:
return f'{b} is greater than {a}'
else:
return f'{a} is equal to {b}'
def count_letter_in_string(a: str, b: str):
string = a.lower()
letter = b.lower()
count = string.count(letter)
return(f"The letter '{letter}' appears {count} times in the string.")
tools = [
{
'type': 'function',
'function': {
'name': 'add',
'description': 'Compute the sum of two numbers',
'parameters': {
'type': 'object',
'properties': {
'a': {
'type': 'int',
'description': 'A number',
},
'b': {
'type': 'int',
'description': 'A number',
},
},
'required': ['a', 'b'],
},
}
},
{
'type': 'function',
'function': {
'name': 'mul',
'description': 'Calculate the product of two numbers',
'parameters': {
'type': 'object',
'properties': {
'a': {
'type': 'int',
'description': 'A number',
},
'b': {
'type': 'int',
'description': 'A number',
},
},
'required': ['a', 'b'],
},
}
},
{
'type': 'function',
'function': {
'name': 'count_letter_in_string',
'description': 'Count letter number in a string',
'parameters': {
'type': 'object',
'properties': {
'a': {
'type': 'str',
'description': 'source string',
},
'b': {
'type': 'str',
'description': 'letter',
},
},
'required': ['a', 'b'],
},
}
},
{
'type': 'function',
'function': {
'name': 'compare',
'description': 'Compare two number, which one is bigger',
'parameters': {
'type': 'object',
'properties': {
'a': {
'type': 'float',
'description': 'A number',
},
'b': {
'type': 'float',
'description': 'A number',
},
},
'required': ['a', 'b'],
},
}
}
]
def function_call_playground(prompt):
messages = [{'role': 'user', 'content': prompt}]
response = client.chat.completions.create(
model="deepseek-ai/DeepSeek-V2.5",
messages = messages,
temperature=0.01,
top_p=0.95,
stream=False,
tools=tools)
# print(response)
func1_name = response.choices[0].message.tool_calls[0].function.name
func1_args = response.choices[0].message.tool_calls[0].function.arguments
func1_out = eval(f'{func1_name}(**{func1_args})')
# print(func1_out)
messages.append(response.choices[0].message)
messages.append({
'role': 'tool',
'content': f'{func1_out}',
'tool_call_id': response.choices[0].message.tool_calls[0].id
})
# print(messages)
response = client.chat.completions.create(
model="deepseek-ai/DeepSeek-V2.5",
messages=messages,
temperature=0.01,
top_p=0.95,
stream=False,
tools=tools)
return response.choices[0].message.content
prompts = [
"用中文回答:strawberry中有多少个r?",
"用中文回答:9.11和9.9,哪个小?"
]
for prompt in prompts:
print(function_call_playground(prompt))
```
模型将输出:
```shell
strawberry中有3个r。
9.11 比 9.9 小。
```
### 4.2. 示例 2:通过function calling 来扩展大语言模型对外部环境的理解
本代码输入 1 个函数,通过外部 API 来查询外部信息
```python
import requests
from openai import OpenAI
client = OpenAI(
api_key="您的 APIKEY", # 从https://cloud.siliconflow.cn/account/ak获取
base_url="https://api.siliconflow.cn/v1"
)
# 使用 WeatherAPI 的天气查询函数
def get_weather(city: str):
# 使用 WeatherAPI 的 API 来获取天气信息
api_key = "您的WeatherAPI APIKEY" # 替换为你自己的 WeatherAPI APIKEY
base_url = "http://api.weatherapi.com/v1/current.json"
params = {
'key': api_key,
'q': city,
'aqi': 'no' # 不需要空气质量数据
}
# 调用天气 API
response = requests.get(base_url, params=params)
if response.status_code == 200:
data = response.json()
weather = data['current']['condition']['text']
temperature = data['current']['temp_c']
return f"The weather in {city} is {weather} with a temperature of {temperature}°C."
else:
return f"Could not retrieve weather information for {city}."
# 定义 OpenAI 的 function calling tools
tools = [
{
'type': 'function',
'function': {
'name': 'get_weather',
'description': 'Get the current weather for a given city.',
'parameters': {
'type': 'object',
'properties': {
'city': {
'type': 'string',
'description': 'The name of the city to query weather for.',
},
},
'required': ['city'],
},
}
}
]
# 发送请求并处理 function calling
def function_call_playground(prompt):
messages = [{'role': 'user', 'content': prompt}]
# 发送请求到 OpenAI API
response = client.chat.completions.create(
model="deepseek-ai/DeepSeek-V2.5",
messages=messages,
temperature=0.01,
top_p=0.95,
stream=False,
tools=tools
)
# 处理 API 返回的工具调用请求
func1_name = response.choices[0].message.tool_calls[0].function.name
func1_args = response.choices[0].message.tool_calls[0].function.arguments
func1_out = eval(f'{func1_name}(**{func1_args})')
# 将结果添加到对话中并返回
messages.append(response.choices[0].message)
messages.append({
'role': 'tool',
'content': f'{func1_out}',
'tool_call_id': response.choices[0].message.tool_calls[0].id
})
# 返回模型响应
response = client.chat.completions.create(
model="deepseek-ai/DeepSeek-V2.5",
messages=messages,
temperature=0.01,
top_p=0.95,
stream=False,
tools=tools
)
return response.choices[0].message.content
# 示例使用
prompt = "how is the weather today in beijing?"
print(function_call_playground(prompt))
```
模型将输出:
```shell
The weather in Beijing today is sunny with a temperature of 21.4°C.
```
# JSON 模式
Source: https://docs.siliconflow.cn/cn/userguide/guides/json-mode
## 1. 使用场景
目前,硅基流动的大模型 API 平台 SiliconCloud 默认生成**非结构化文本**,但在某些应用场景中,您可能希望模型以**结构化**的形式输出内容,但用提示词的方式直接告诉大模型却无法获得正确的结构化输出。
作为一种标准化、轻量级的数据交换格式,JSON 模式是支持大模型 API 进行结构化输出的重要功能。当您调用大模型的 API 进行请求时,模型返回的结果以 JSON 格式呈现,易于人类阅读和编写,同时也易于机器解析和生成。
现在,SiliconCloud 平台上除了 VL 模型外,其他主要语言模型均已支持 JSON 模式,能让模型输出 JSON 格式的字符串,以确保模型以预期的结构输出,便于后续对输出内容进行逻辑解析。
比如,您现在可以通过 SiliconCloud API 对以下案例尝试结构化输出:
* 从公司相关报道中构建新闻数据库,包括新闻标题、链接等。
* 从商品购买评价中提取出情感分析结构,包括情感极性(正面、负面、中性)、情感强度、情感关键词等。
* 从商品购买历史中提取出产品列表,包括产品信息、推荐理由、价格、促销信息等。
## 2. 使用方式
在请求中添加
```json
response_format={"type": "json_object"}
```
## 3. 支持模型列表
目前线上,平台提供的大语言类模型都支持上述参数。
注意:支持的模型情况可能会发生变化,请查阅本文档了解最新支持的模型列表。
你的应用必须检测并处理可能导致模型输出不完整JSON对象的边缘案例。
请合理设置max\_tokens,防止JSON字符串被中断。
## 4. 使用示例
下面是在 OpenAI 中使用的例子:
```python
import json
from openai import OpenAI
client = OpenAI(
api_key="您的 APIKEY", # 从https://cloud.siliconflow.cn/account/ak获取
base_url="https://api.siliconflow.cn/v1"
)
response = client.chat.completions.create(
model="deepseek-ai/DeepSeek-V2.5",
messages=[
{"role": "system", "content": "You are a helpful assistant designed to output JSON."},
{"role": "user", "content": "? 2020 年世界奥运会乒乓球男子和女子单打冠军分别是谁? "
"Please respond in the format {\"男子冠军\": ..., \"女子冠军\": ...}"}
],
response_format={"type": "json_object"}
)
print(response.choices[0].message.content)
```
模型将输出:
```json
{"男子冠军": "马龙", "女子冠军": "陈梦"}
```
# 前缀续写
Source: https://docs.siliconflow.cn/cn/userguide/guides/prefix
## 1. 使用场景
前缀续写中,用户提供希望输出的前缀信息,来让模型基于用户提供的前缀信息来补全其余的内容。
基于上述能力,模型能有更好的指令遵循能力,满足用户一些特定场景的指定格式的问题。
## 2. 使用方式
在请求中添加
```json
extra_body={"prefix":"希望的前缀内容"}
```
## 3. 支持模型列表
目前[大语言类模型](https://cloud.siliconflow.cn/models?types=chat)支持上述参数。
注意:支持的模型情况可能会发生变化,请查阅本文档了解最新支持的模型列表。
## 4. 使用示例
下面是基于 OpenAI 库使用前缀续写的例子:
````python
client = OpenAI(
api_key="您的 APIKEY", # 从https://cloud.siliconflow.cn/account/ak获取
base_url="https://api.siliconflow.cn/v1"
)
messages = [
{"role": "user", "content": "Please write quick sort code"},
]
response = client.chat.completions.create(
model="deepseek-ai/DeepSeek-V2.5",
messages=messages,
extra_body={"prefix":"```python\n"}
)
print(response.choices[0].message.content)
````
# 产品简介
Source: https://docs.siliconflow.cn/cn/userguide/introduction
## 1. 产品介绍
* 作为集合顶尖大模型的一站式云服务平台,[SiliconCloud](https://siliconflow.cn/zh-cn/siliconcloud) 致力于为开发者提供更快、更全面、体验更丝滑的模型 API,助力开发者和企业聚焦产品创新,无须担心产品大规模推广所带来的高昂算力成本。
## 2. 产品功能
1. 提供开箱即用的大模型 API,按量收费,助力应用开发轻松实现。
* 已上架包括 Qwen2.5-72B、DeepSeek-V2.5、Qwen2、InternLM2.5-20B-Chat、BCE、BGE、SenseVoice-Small、DeepSeek-Coder-V2、SD3 Medium、GLM-4-9B-Chat、InstantID 在内的多种开源大语言模型、图片生成模型、代码生成模型、向量与重排序模型以及多模态大模型,覆盖语言、语音、图片、视频等多场景。
* 其中,Qwen2.5(7B)等多个大模型 API 免费使用,让开发者与产品经理无需担心研发阶段和大规模推广所带来的算力成本,实现“Token 自由”。
* 25 年 1 月,SiliconCloud 平台上线基于华为云昇腾云服务的 DeepSeek-V3、DeepSeek-R1 推理服务。通过双方联合创新,在硅基流动自研推理加速引擎加持下,平台上的 DeepSeek 模型可获得持平全球高端 GPU 部署模型的效果。
2. 提供高效能大模型推理加速服务,提升 GenAI 应用的用户体验。
3. 提供模型微调与部署的托管服务,用户可直接托管经过微调的大语言模型,在支撑业务迭代的同时,无需关注底层资源、服务质量,有效降低维护成本。
## 3. 产品特性
1. **高速推理**
* 自研高效算子和优化框架,推理加速引擎全球领先。
* 极致提升吞吐能力,全面支持高吞吐场景的业务需求。
* 显著优化计算延迟,为低延迟场景提供卓越性能保障。
2. **高扩展性**
* 动态扩容支持弹性业务模型,无缝适配多种复杂场景。
* 一键部署自定义模型,轻松应对规模化挑战。
* 灵活架构设计,满足多样化任务需求,支持混合云部署。
3. **高性价比**
* 端到端极致优化,推理和部署成本显著降低。
* 提供灵活按需付费模式,减少资源浪费,精准控制预算。
* 支持国产异构 GPU 部署,基于企业已有投资,节省企业投入。
4. **高稳定性**
* 经过开发者验证,保证高可靠稳定运行。
* 提供完善的监控和容错机制,保障服务能力。
* 提供专业技术支持,满足企业级场景需求,确保服务高可用性。
5. **高智能**
* 提供多种先进模型服务,包括大语言模型、音视频等多模态模型。
* 智能扩展功能,灵活适配业务规模,满足多种服务需求。
* 智能成本分析,为业务优化提供支持,助力成本管控与效益提升。
6. **高安全性**
* 支持 BYOC 部署,全面保护数据隐私与业务安全。
* 计算隔离/网络隔离/存储隔离,保障数据安全。
* 符合行业标准与合规要求,全面满足企业级用户的安全需求。
# BizyAir 文档
Source: https://docs.siliconflow.cn/cn/userguide/products/bizyair
# OneDiff 多模态推理加速引擎
Source: https://docs.siliconflow.cn/cn/userguide/products/onediff
# SiliconCloud 平台
Source: https://docs.siliconflow.cn/cn/userguide/products/siliconcloud
# SiliconLLM 大语言推理加速引擎
Source: https://docs.siliconflow.cn/cn/userguide/products/siliconllm
# 快速上手
Source: https://docs.siliconflow.cn/cn/userguide/quickstart
## 1. 登录平台
访问[ SiliconCloud官网 ](https://siliconflow.cn/zh-cn/siliconcloud)并点击右上角[“登录”](https://cloud.siliconflow.cn/)按钮,按照提示填写您的基本信息进行登录。
(目前平台支持短信登录、邮箱登录,以及 GitHub、Google 的 OAuth 登录)
## 2. 查看模型列表和模型详情
通过[ 模型广场 ](https://cloud.siliconflow.cn/models)查看当前可用的模型详情、模型价格、用户可用的最高限速等信息,并可以通过模型详情页的“在线体验”进入到模型体验中心。
## 3. 在 playground 体验 GenAI 能力
进入[“体验中心( playground )”](https://cloud.siliconflow.cn/)页面,左侧栏可选择语言模型、文生图模型和图生图模型,选择相应模型即可开始实时体验。输入相关参数及 prompt ,点击“运行”按钮,即可看到模型生成的结果。
## 4. 使用 SiliconCloud API 调用GenAI 能力
### 4.1 创建API key
进入[API密钥](https://cloud.siliconflow.cn/account/ak)页面,点击“新建API密钥”,创建您的API key
### 4.2 通过REST 接口进行服务调用
您可以直接在平台的[“文档链接”](https://docs.siliconflow.cn/cn/api-reference/chat-completions/chat-completions)中使用您的 API key 进行在线调用,此处可以生成对应语言的代码。
### 4.3 通过 OpenAI 接口调用
当前大语言模型部分支持以 OpenAI 库进行调用,
安装 Python3.7.1 或更高版本并设置虚拟环境后,即可安装 OpenAI Python 库。从终端/命令行运行:
```shell
pip install --upgrade openai
```
完成此操作后, running 将显示您在当前环境中安装的 Python 库,确认 OpenAI Python 库已成功安装。
之后可以直接通过 OpenAI 的相关接口进行调用,目前平台支持 OpenAI 相关的大多数参数。
```python
from openai import OpenAI
client = OpenAI(api_key="YOUR_API_KEY_FROM_CLOUD_SILICONFLOW_CN",
base_url="https://api.siliconflow.cn/v1")
response = client.chat.completions.create(
# model='Pro/deepseek-ai/DeepSeek-R1',
model="Qwen/Qwen2.5-72B-Instruct",
messages=[
{'role': 'user',
'content': "推理模型会给市场带来哪些新的机会"}
],
stream=True
)
for chunk in response:
if not chunk.choices:
continue
if chunk.choices[0].delta.content:
print(chunk.choices[0].delta.content, end="", flush=True)
if chunk.choices[0].delta.reasoning_content:
print(chunk.choices[0].delta.reasoning_content, end="", flush=True)
```
# Rate Limits
Source: https://docs.siliconflow.cn/cn/userguide/rate-limits/rate-limit-and-upgradation
## 1. Rate Limits 概述
### 1.1 什么是 Rate Limits
Rate Limits 是指用户 API 在指定时间内访问 SiliconCloud 平台服务频次规则。
### 1.2 为什么做 Rate Limits
Rate Limits 是 API 的常见做法,其实施原因如下:
* **保障资源的公平性及合理利用**:确保资源公平使用。 防止某些用户过多请求,影响其他用户的正常使用体验。
* **防止请求过载**:提高服务可靠性。帮助管理平台总体负载,避免因请求激增而导致服务器出现性能问题。
* **安全防护**:防止恶意性攻击,导致平台过载甚至服务中断。
### 1.3 Rate Limits 指标
目前Rate Limit以七种指标衡量:
* RPM( requests per minute,一分钟最多发起的请求数)
* RPH( requests per hour,每小时允许的最大请求数)
* RPD (Requests per day,每天允许的最大请求数)
* TPM( tokens per minute,一分钟最多允许的 token 数)
* TPD( tokens per day,每天最多允许的 token 数)
* IPM( images per minute,一分钟最多生成的图片数)
* IPD( images per day,一天最多生成的图片数)
### 1.4 不同模型的 Rate Limits 指标
| 模型名称 | Rate Limit指标 | 当前指标 |
| ------------------------- | ------------ | ---------------------------------- |
| 语言模型(Chat) | RPM、 TPM | RPM=1000-10000 TPM=50000-5000000 |
| 向量模型(Embedding) | RPM、 TPM | RPM:2000-10000 TPM:500000-10000000 |
| 重排序模型(Reranker) | RPM、 TPM | RPM:2000 TPM:500000 |
| 图像生成模型(Image) | IPM、IPD | IPM:2- IPD:400- |
| 多模态模型 (Multimodal Models) | - | - |
Rate Limits 可能会因在任一选项(RPM、RPH、RPD、TPM、TPD、IPM、IPD)中达峰而触发,取决于哪个先发生。
例如,在 RPM 限制为20,TPM 限制为 200K 时,一分钟内,账户向 ChatCompletions 发送了 20 个请求,每个请求有 100个Token ,限制即触发,即使账户在这些 20 个请求中没有发满 200K 个 Token。
### 1.5 Rate Limits 主体
1. Rate Limit是在用户账户级别定义的,而不是密钥(API key)维度。
2. 每个模型**单独设置 Rate Limits**,一个模型请求超出 Rate Limits 不影响其他模型正常使用。
## 2. Rate Limits 规则
* 当前免费模型 Rate Limits 指标是固定值,收费模型根据账户[用量级别](https://account.siliconflow.cn/user/settings)有不同的 [Rate Limits 指标](https://cloud.siliconflow.cn/models)。
* 同一用量级别下,模型类别不同、模型参数量不同,Rate Limits 峰值不同。
### 2.1 免费模型Rate Limits
1. **[实名认证](/faqs/authentication)后使用全部的免费模型。**
2. **免费模型调用免费**,账户的[费用账单](https://cloud.siliconflow.cn/bills)中看到此类模型的费用为调用消耗是 0。
3. **免费模型的 Rate Limits 固定**。对于部分模型,平台同时提供**免费版**和**收费版**。免费版按照原名称命名;收费版会在**名称前加上“Pro/”以示区分**。例如,Qwen2.5-7B-Instruct 的免费版命名为“Qwen/Qwen2.5-7B-Instruct”,收费版则命名为“Pro/Qwen/Qwen2.5-7B-Instruct”。
### 2.2 收费模型 Rate Limits
1. 按照用量付费。API 调用消耗**计入**账户[费用账单](https://cloud.siliconflow.cn/bills)。
2. 根据账户**用量级别**进行分层 Rate Limits 。 Rate Limits 峰值随着用量级别提升而增大。
3. 同一用量级别下,模型类别不同、模型参数量大小不同, Rate Limits 峰值不同。
### 2.3 用户用量级别与 Rate Limits
平台依据账户每月消费金额将其划分为不同的用量级别,每个级别有各自的 Rate Limits 标准。月消费达到更高级别标准时,自动升级至相应用量级别。升级立即生效,并提供更宽松的 Rate Limits。
* **月消费金额**:包含充值金额消费和赠送金额在内的账户每个月的总[消费金额](https://cloud.siliconflow.cn/bills)。
* **级别设置**:比较**上个自然月**和**当月 1 号到今日**的消费金额,取最高值换算成对应的用量级别。新用户注册后初始用量级别为L0。
| 用量级别 | 资质(单位:人民币元) |
| ---- | ------------------------------ |
| L0 | 上月或当月消费金额最高值 \< ¥50 |
| L1 | ¥50 ≤ 上月或当月消费金额最高值 \< ¥200 |
| L2 | ¥200 ≤ 上月或当月消费金额最高值 \< ¥2000 |
| L3 | ¥2000 ≤ 上月或当月消费金额最高值 \< ¥5000 |
| L4 | ¥5000 ≤ 上月或当月消费金额最高值 \< ¥10000 |
| L5 | ¥10000 ≤ 上月或当月消费金额最高值 |
### 2.4 具体模型的 Rate Limits
平台目前提供文本生成、图像生成、向量化、重排序和语音五大类,具体模型的 Rate Limits 指标在[模型广场](https://cloud.siliconflow.cn/models)中查看。
{/*### 2.5 `deepseek-ai/DeepSeek-R1` 和 `deepseek-ai/DeepSeek-V3` Rate Limits具体规则:
1. 新增 RPH 限制(Requests Per Hour,每小时请求数)
* 模型范围:deepseek-ai/DeepSeek-R1、deepseek-ai/DeepSeek-V3
* 适用对象:所有用户
* 限制标准:30次/小时
2. 新增 RPD 限制(Requests Per Day,每日请求数)
* 模型范围:deepseek-ai/DeepSeek-R1、deepseek-ai/DeepSeek-V3
* 适用对象:未完成实名认证用户
* 限制标准:100次/天
随着流量和负载变化,策略可能会不定时调整,硅基流动保留解释权。*/}
## 3. 超出 Rate Limits 处理
### 3.1 超出 Rate Limits 报错信息
如果超出 Rate Limits 调用限制,用户的 API 请求将会因为超过 Rate Limits 而失败。用户需要等待一段时间待满足 Rate Limits 条件后方能再次调用。对应的 HTTP 错误信息为:
```shell
HTTP/1.1 429
Too Many Requests
Content Type: application/json
Request was rejected due to rate limiting. If you want more, please contact contact@siliconflow.cn
```
### 3.2 超出 Rate Limits 处理方式
* 在已有的Rate Limits下,可以参考 [超出 Rate Limits 处理](https://github.com/siliconflow/siliconcloud-cookbook/blob/main/examples/how-to-handle-rate-limit-in-siliconcloud.ipynb)
进行错误回避。
* 也可以通过提升用量级别来提升模型 Rate Limits 峰值,业务目标。
## 4. 如何提升模型 Rate Limits 指标
### 4.1 提升 Rate Limits 的方式
* 根据用量自动升级:您可以通过提高用量来增加[月消费金额](https://cloud.siliconflow.cn/bills),满足下一级别资质时,会自动升级。
* 购买等级包快速提升:如果您需要**快速达到**更高用量级别、提高 Rate Limits 峰值,可以通过[购买等级包](https://cloud.siliconflow.cn/package)来提升用量级别。
### 4.2 等级包购买细则
* 在线购买:请前往平台在线购买 [等级包](https://cloud.siliconflow.cn/package)
* 有效时间:等级包购买后立即生效,适用于当月(N)和下一个自然月(N+1)。自下下个自然月(N+2)起,将根据上一个月(N+1)的消费金额重新计算账户的最新用量级别。
* 支付方式:等级包仅支持使用平台充值余额支付,不支持使用平台赠送余额支付。
* 发票开具:关于等级包的发票开具,参考[开具发票](/faqs/invoice)部分。
* 专属实例:等级包不适用于专属实例需求,若有相关需求,请联系您的专属客户经理。
### 4.3 其他情况
* 联系我们:不属于上述情况的场景,请[联系我们](https://siliconflow.feishu.cn/share/base/form/shrcnaamvQ4C7YKMixVnS32k1G3)。
# 在编程工具中使用本文档
Source: https://docs.siliconflow.cn/cn/userguide/use-docs-with-cursor
SiliconCloud 文档站支持 [llms.txt 协议](https://llmstxt.org/),既可供用户直接查阅,也可无缝对接各类支持该协议的工具进行使用。
考虑到部分用户可能对 [llms.txt 协议](https://llmstxt.org/) 不够熟悉,下面将简要介绍使用流程及相关概述。
## 1. 在 Cursor 中使用本文档
### 1.1 在 Cursor 中增加 SiliconCloud 模型
* 进入 Cursor 设置的 Models 页面,在 Models Names 列表底部输入框填写 SiliconCloud 平台的模型名称,点击`Add model`添加模型;
* 在 Models Names 列表中打开刚刚填入的模型开关;
* 在 OpenAI API Key 中 填写 SiliconCloud API Base URL 和 SiliconCloud API Key,点击 Verify 验证成功。
 ### 1.2 在 Cursor 中配置 SiliconCloud 文档
配置 `Cursor` 的 `@Docs` 数据源,可以很方便的将本文档丢给 `Cursor` 使用。
### 1.2 在 Cursor 中配置 SiliconCloud 文档
配置 `Cursor` 的 `@Docs` 数据源,可以很方便的将本文档丢给 `Cursor` 使用。


 ### 1.3 在 Cursor 中使用文档
### 1.3 在 Cursor 中使用文档
 ## 2. 关于 llmx.txt 的相关介绍
### 2.1 协议背景
llms.txt 是一种新兴的 Web 标准,旨在帮助大型语言模型(LLMs)更有效地访问和理解网站内容。通过在网站根目录下创建 llms.txt 文件,网站所有者可以为 AI 系统提供清晰的导航和指引,从而提升信息检索的效率。
### 2.2 文件结构:
llms.txt 文件采用 Markdown 格式,通常包含以下部分:
1. 标题:网站名称或项目名称。
2. 描述(可选):对网站或项目的简要介绍。
3. 详细信息(可选):提供更多背景信息或链接到其他文档。
4. 章节:列出网站的重要部分,每个部分包含链接和可选的详细说明。
示例如下(参考:[https://docs.siliconflow.cn/llms.txt](https://docs.siliconflow.cn/llms.txt) 和 [https://docs.siliconflow.cn/llms-full.txt](https://docs.siliconflow.cn/llms-full.txt) 文件)
```markdown
# SiliconFlow
## Docs
- [创建语音转文本请求](https://docs.siliconflow.cn/api-reference/audio/create-audio-transcriptions): Creates an audio transcription.
- [创建文本转语音请求](https://docs.siliconflow.cn/api-reference/audio/create-speech): 从输入文本生成音频。根据输入的文本生成音频。接口生成的数据为音频的二进制数据,需要使用者自行处理。参考:https://docs.siliconflow.cn/capabilities/text-to-speech#5
- [删除参考音频](https://docs.siliconflow.cn/api-reference/audio/delete-voice): 删除用户预置音色
- [上传参考音频](https://docs.siliconflow.cn/api-reference/audio/upload-voice): 上传用户预置音色,支持以 base64 编码或者文件形式上传,参考https://docs.siliconflow.cn/capabilities/text-to-speech#2-2)
- [参考音频列表获取](https://docs.siliconflow.cn/api-reference/audio/voice-list): 获取用户预置音色列表
...
```
### 2.3 文件作用
#### 2.3.1 /llms.txt:
* 大规模人工智能友好导航:该文件提供了整个文档导航的简化视图,使 Cursor 或 ChatGPT 等 LLM 可以更轻松地索引您的内容。
* 将其视为人工智能的搜索引擎优化--用户现在可以直接通过通用的 LLM 找到特定产品的信息。
#### 2.3.2 /llms-full.txt:
* 文件会将所有文档文本编译成一个标记符文件,便于人工智能工具基于该文件将信息直接载入其上下文窗口。
* 可以将文档输入到 Cursor 等人工智能编码助手中,让它们根据您产品的具体细节提供上下文感知建议。
### 2.4 与现有标准的区别:
虽然 llms.txt 与 robots.txt 和 sitemap.xml 等现有标准在功能上有所重叠,但它们的目的和作用不同:
* robots.txt:用于指示搜索引擎爬虫哪些页面可以或不可以抓取,主要关注访问权限控制。
* sitemap.xml:提供网站的结构地图,帮助搜索引擎了解网站的页面布局,主要用于索引目的。
* llms.txt:为大型语言模型提供结构化的内容概述,帮助 AI 系统更好地理解和处理网站信息,提升与 AI 交互的效果。
## 3. 在其他工具中使用
其他平台如果支持[llms.txt 协议](https://llmstxt.org/),也可以直接使用。
比如在 ChatGPT 中使用:
## 2. 关于 llmx.txt 的相关介绍
### 2.1 协议背景
llms.txt 是一种新兴的 Web 标准,旨在帮助大型语言模型(LLMs)更有效地访问和理解网站内容。通过在网站根目录下创建 llms.txt 文件,网站所有者可以为 AI 系统提供清晰的导航和指引,从而提升信息检索的效率。
### 2.2 文件结构:
llms.txt 文件采用 Markdown 格式,通常包含以下部分:
1. 标题:网站名称或项目名称。
2. 描述(可选):对网站或项目的简要介绍。
3. 详细信息(可选):提供更多背景信息或链接到其他文档。
4. 章节:列出网站的重要部分,每个部分包含链接和可选的详细说明。
示例如下(参考:[https://docs.siliconflow.cn/llms.txt](https://docs.siliconflow.cn/llms.txt) 和 [https://docs.siliconflow.cn/llms-full.txt](https://docs.siliconflow.cn/llms-full.txt) 文件)
```markdown
# SiliconFlow
## Docs
- [创建语音转文本请求](https://docs.siliconflow.cn/api-reference/audio/create-audio-transcriptions): Creates an audio transcription.
- [创建文本转语音请求](https://docs.siliconflow.cn/api-reference/audio/create-speech): 从输入文本生成音频。根据输入的文本生成音频。接口生成的数据为音频的二进制数据,需要使用者自行处理。参考:https://docs.siliconflow.cn/capabilities/text-to-speech#5
- [删除参考音频](https://docs.siliconflow.cn/api-reference/audio/delete-voice): 删除用户预置音色
- [上传参考音频](https://docs.siliconflow.cn/api-reference/audio/upload-voice): 上传用户预置音色,支持以 base64 编码或者文件形式上传,参考https://docs.siliconflow.cn/capabilities/text-to-speech#2-2)
- [参考音频列表获取](https://docs.siliconflow.cn/api-reference/audio/voice-list): 获取用户预置音色列表
...
```
### 2.3 文件作用
#### 2.3.1 /llms.txt:
* 大规模人工智能友好导航:该文件提供了整个文档导航的简化视图,使 Cursor 或 ChatGPT 等 LLM 可以更轻松地索引您的内容。
* 将其视为人工智能的搜索引擎优化--用户现在可以直接通过通用的 LLM 找到特定产品的信息。
#### 2.3.2 /llms-full.txt:
* 文件会将所有文档文本编译成一个标记符文件,便于人工智能工具基于该文件将信息直接载入其上下文窗口。
* 可以将文档输入到 Cursor 等人工智能编码助手中,让它们根据您产品的具体细节提供上下文感知建议。
### 2.4 与现有标准的区别:
虽然 llms.txt 与 robots.txt 和 sitemap.xml 等现有标准在功能上有所重叠,但它们的目的和作用不同:
* robots.txt:用于指示搜索引擎爬虫哪些页面可以或不可以抓取,主要关注访问权限控制。
* sitemap.xml:提供网站的结构地图,帮助搜索引擎了解网站的页面布局,主要用于索引目的。
* llms.txt:为大型语言模型提供结构化的内容概述,帮助 AI 系统更好地理解和处理网站信息,提升与 AI 交互的效果。
## 3. 在其他工具中使用
其他平台如果支持[llms.txt 协议](https://llmstxt.org/),也可以直接使用。
比如在 ChatGPT 中使用:
 ## 4. 扩展阅读
1. The /llms.txt file, [https://llmstxt.org/](https://llmstxt.org/)
2. @Docs, [https://docs.cursor.com/context/@-symbols/@-docs](https://docs.cursor.com/context/@-symbols/@-docs)
3. LLMs.txt:AI时代的站点地图, [https://juejin.cn/post/7447083753187328050](https://juejin.cn/post/7447083753187328050)
## 4. 扩展阅读
1. The /llms.txt file, [https://llmstxt.org/](https://llmstxt.org/)
2. @Docs, [https://docs.cursor.com/context/@-symbols/@-docs](https://docs.cursor.com/context/@-symbols/@-docs)
3. LLMs.txt:AI时代的站点地图, [https://juejin.cn/post/7447083753187328050](https://juejin.cn/post/7447083753187328050)