> ## Documentation Index
> Fetch the complete documentation index at: https://docs.siliconflow.cn/llms.txt
> Use this file to discover all available pages before exploring further.
# 语言模型
语言模型(LLM)使用说明手册
## 1. 模型核心能力
### 1.1 基础功能
文本生成:根据上下文生成连贯的自然语言文本,支持多种文体和风格。
语义理解:深入解析用户意图,支持多轮对话管理,确保对话的连贯性和准确性。
知识问答:覆盖广泛的知识领域,包括科学、技术、文化、历史等,提供准确的知识解答。
代码辅助:支持多种主流编程语言(如Python、Java、C++等)的代码生成、解释和调试。
### 1.2 进阶能力
长文本处理:支持4k至64k tokens的上下文窗口,适用于长篇文档生成和复杂对话场景。
指令跟随:精确理解复杂任务指令,如“用Markdown表格对比A/B方案”。
风格控制:通过系统提示词调整输出风格,支持学术、口语、诗歌等多种风格。
多模态支持:除了文本生成,还支持图像描述、语音转文字等多模态任务。
## 2. 接口调用规范
### 2.1 基础请求结构
您可以通过 openai sdk进行端到端接口请求
```python theme={null}
from openai import OpenAI
client = OpenAI(api_key="YOUR_KEY", base_url="https://api.siliconflow.cn/v1")
response = client.chat.completions.create(
model="deepseek-ai/DeepSeek-V3",
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Write a haiku about recursion in programming."}
],
temperature=0.7,
max_tokens=1024,
stream=True
)
# 逐步接收并处理响应
for chunk in response:
if not chunk.choices:
continue
if chunk.choices[0].delta.content:
print(chunk.choices[0].delta.content, end="", flush=True)
if chunk.choices[0].delta.reasoning_content:
print(chunk.choices[0].delta.reasoning_content, end="", flush=True)
```
```python theme={null}
from openai import OpenAI
client = OpenAI(api_key="YOUR_KEY", base_url="https://api.siliconflow.cn/v1")
response = client.chat.completions.create(
model="deepseek-ai/deepseek-vl2",
messages=[
{
"role": "user",
"content": [
{
"type": "image_url",
"image_url": {
"url": "https://sf-maas-uat-prod.oss-cn-shanghai.aliyuncs.com/outputs/658c7434-ec12-49cc-90e6-fe22ccccaf62_00001_.png",
},
},
{
"type": "text",
"text": "What's in this image?"
}
],
}
],
temperature=0.7,
max_tokens=1024,
stream=True
)
# 逐步接收并处理响应
for chunk in response:
if not chunk.choices:
continue
if chunk.choices[0].delta.content:
print(chunk.choices[0].delta.content, end="", flush=True)
if chunk.choices[0].delta.reasoning_content:
print(chunk.choices[0].delta.reasoning_content, end="", flush=True)
```
```python theme={null}
import json
from openai import OpenAI
client = OpenAI(
api_key="您的 APIKEY", # 从https://cloud.siliconflow.cn/account/ak获取
base_url="https://api.siliconflow.cn/v1"
)
response = client.chat.completions.create(
model="deepseek-ai/DeepSeek-V2.5",
messages=[
{"role": "system", "content": "You are a helpful assistant designed to output JSON."},
{"role": "user", "content": "? 2020 年世界奥运会乒乓球男子和女子单打冠军分别是谁? "
"Please respond in the format {\"男子冠军\": ..., \"女子冠军\": ...}"}
],
response_format={"type": "json_object"}
)
print(response.choices[0].message.content)
```
### 2.2 消息体结构说明
| 消息类型 | 功能描述 | 示例内容 |
| --------- | ------------------------------- | ------------------ |
| system | 模型指令,设定AI角色,描述模型应一般如何行为和响应 | 例如:"你是有10年经验的儿科医生" |
| user | 用户输入,将最终用户的消息传递给模型 | 例如:"幼儿持续低烧应如何处理?" |
| assistant | 模型生成的历史回复,为模型提供示例,说明它应该如何回应当前请求 | 例如:"建议先测量体温..." |
你想让模型遵循分层指令时,消息角色可以帮助你获得更好的输出。但它们并不是确定性的,所以使用的最佳方式是尝试不同的方法,看看哪种方法能给你带来好的结果。
## 3. 模型系列选型指南
可以进入[模型广场](https://cloud.siliconflow.cn/models),根据左侧的筛选功能,筛选支持不同功能的语言模型,根据模型的介绍,了解模型具体的价格、模型参数大小、模型上下文支持的最大长度及模型价格等内容。
支持在[playground](https://cloud.siliconflow.cn/playground/chat)进行体验(playground只进行模型体验,暂时没有历史记录功能,如果您想要保存历史的回话记录内容,请自己保存会话内容),想要了解更多使用方式,可以参考[API文档](https://docs.siliconflow.cn/cn/api-reference/chat-completions/chat-completions)
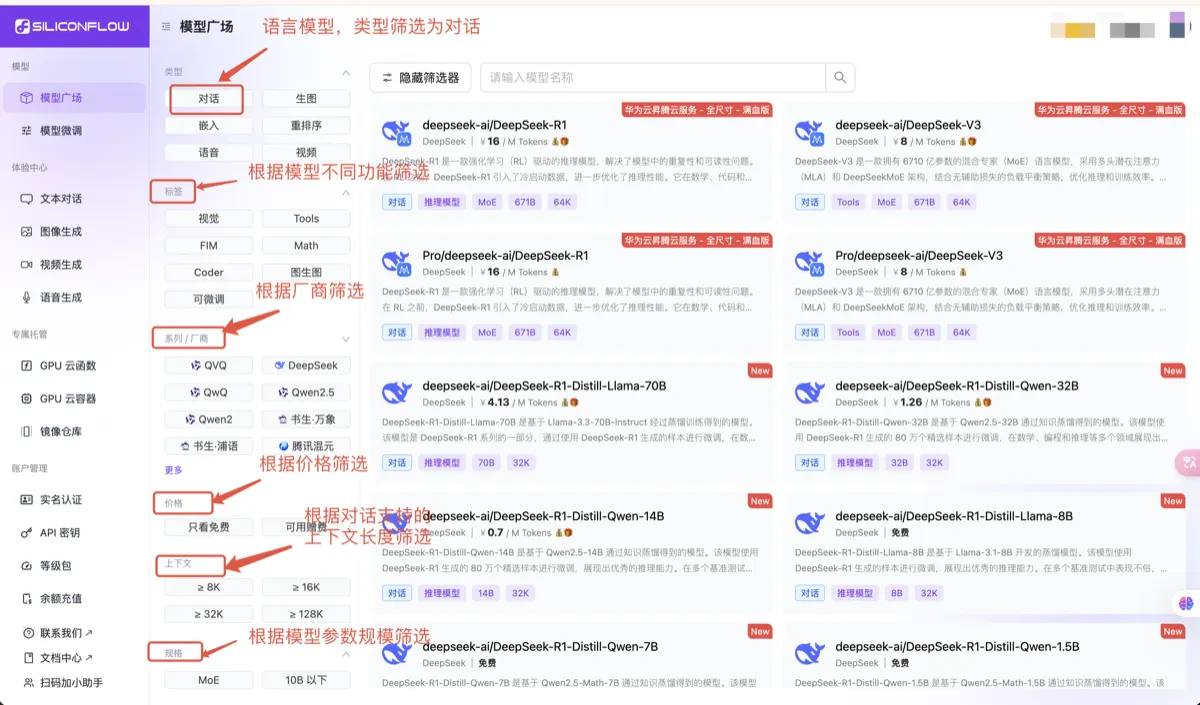 ## 4. 核心参数详解
### 4.1 创造性控制
```bash theme={null}
# 温度参数(0.0~2.0)
temperature=0.5 # 平衡创造性与可靠性
# 核采样(top_p)
top_p=0.9 # 仅考虑概率累积90%的词集
```
### 4.2 输出限制
```json theme={null}
max_tokens=1000 # 单词请求最大生成长度
stop=["\n##", "<|end|>"] # 终止序列,在返回中遇到数组中对应的字符串,就会停止输出
frequency_penalty=0.5 # 抑制重复用词(-2.0~2.0)
stream=true # 控制输出是否是流式输出,对于一些输出内容比较多的模型,建议设置为流式,防止输出过长,导致输出超时
```
### 4.3 语言模型场景问题汇总
**1. 模型输出乱码**
目前看到部分模型在不设置参数的情况下,容易出现乱码,遇到上述情况,可以尝试设置`temperature`,`top_k`,`top_p`,`frequency_penalty`这些参数。
对应的 payload 修改为如下形式,不同语言酌情调整
```python theme={null}
payload = {
"model": "Qwen/Qwen2.5-Math-72B-Instruct",
"messages": [
{
"role": "user",
"content": "1+1=?",
}
],
"max_tokens": 200, # 按需添加
"temperature": 0.7, # 按需添加
"top_k": 50, # 按需添加
"top_p": 0.7, # 按需添加
"frequency_penalty": 0 # 按需添加
}
```
**2. 关于`max_tokens`说明**
max\_tokens 与`上下文长度`相等,由于部分模型推理服务尚在更新中,请不要在请求时将 max\_tokens 设置为最大值(上下文长度),建议留出 10k 左右作为输入内容的空间。
**3. 关于`context_length`说明**
不同的LLM模型,`context_length`是有差别的,具体可以在[模型广场](https://cloud.siliconflow.cn/models)上搜索对应的模型,
查看模型具体信息。
**4. 模型输出截断问题**
可以从以下几方面进行问题的排查:
* 通过API请求时候,输出截断问题排查:
* max\_tokens设置:max\_token设置到合适值,输出大于max\_token的情况下,会被截断。
* 设置流式输出请求:非流式请求时候,输出内容比较长的情况下,容易出现504超时。
* 设置客户端超时时间:把客户端超时时间设置大一些,防止未输出完成,达到客户端超时时间被截断。
* 通过第三方客户端请求,输出截断问题排查:
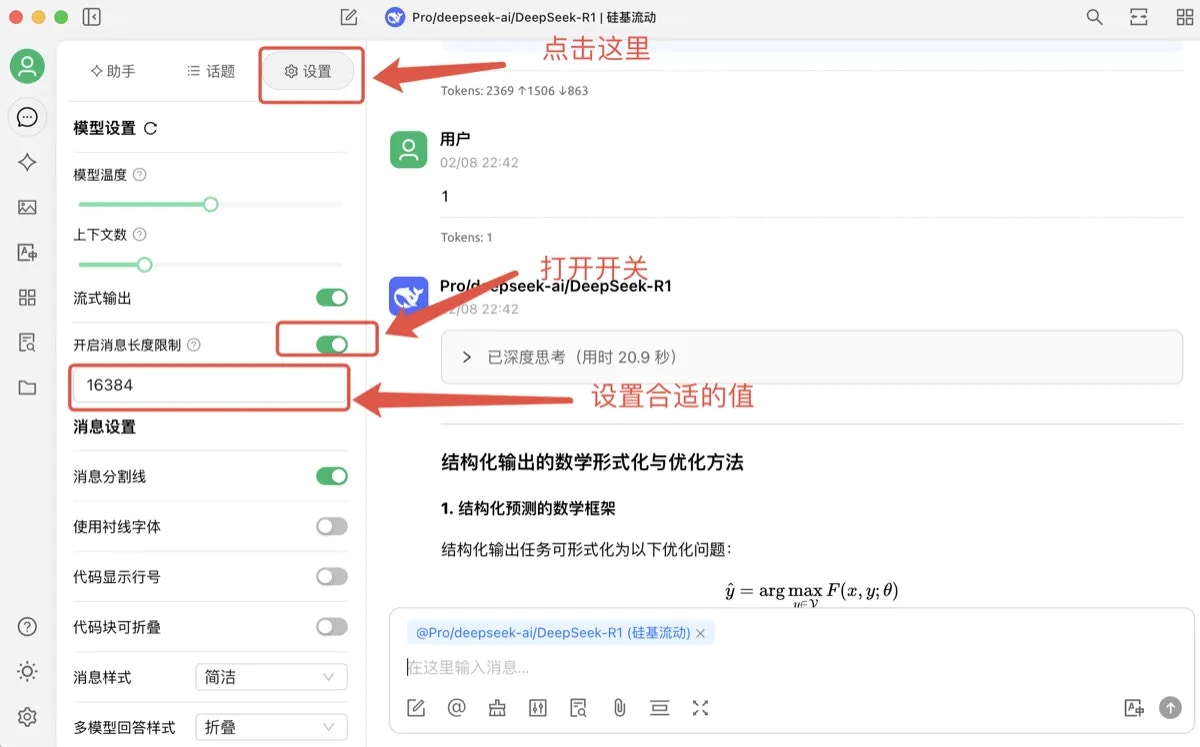
* CherryStdio 默认的 max\_tokens 是 4096,用户可以通过设置,打开“开启消息长度限制”的开关,将max\_token设置到合适值
## 4. 核心参数详解
### 4.1 创造性控制
```bash theme={null}
# 温度参数(0.0~2.0)
temperature=0.5 # 平衡创造性与可靠性
# 核采样(top_p)
top_p=0.9 # 仅考虑概率累积90%的词集
```
### 4.2 输出限制
```json theme={null}
max_tokens=1000 # 单词请求最大生成长度
stop=["\n##", "<|end|>"] # 终止序列,在返回中遇到数组中对应的字符串,就会停止输出
frequency_penalty=0.5 # 抑制重复用词(-2.0~2.0)
stream=true # 控制输出是否是流式输出,对于一些输出内容比较多的模型,建议设置为流式,防止输出过长,导致输出超时
```
### 4.3 语言模型场景问题汇总
**1. 模型输出乱码**
目前看到部分模型在不设置参数的情况下,容易出现乱码,遇到上述情况,可以尝试设置`temperature`,`top_k`,`top_p`,`frequency_penalty`这些参数。
对应的 payload 修改为如下形式,不同语言酌情调整
```python theme={null}
payload = {
"model": "Qwen/Qwen2.5-Math-72B-Instruct",
"messages": [
{
"role": "user",
"content": "1+1=?",
}
],
"max_tokens": 200, # 按需添加
"temperature": 0.7, # 按需添加
"top_k": 50, # 按需添加
"top_p": 0.7, # 按需添加
"frequency_penalty": 0 # 按需添加
}
```
**2. 关于`max_tokens`说明**
max\_tokens 与`上下文长度`相等,由于部分模型推理服务尚在更新中,请不要在请求时将 max\_tokens 设置为最大值(上下文长度),建议留出 10k 左右作为输入内容的空间。
**3. 关于`context_length`说明**
不同的LLM模型,`context_length`是有差别的,具体可以在[模型广场](https://cloud.siliconflow.cn/models)上搜索对应的模型,
查看模型具体信息。
**4. 模型输出截断问题**
可以从以下几方面进行问题的排查:
* 通过API请求时候,输出截断问题排查:
* max\_tokens设置:max\_token设置到合适值,输出大于max\_token的情况下,会被截断。
* 设置流式输出请求:非流式请求时候,输出内容比较长的情况下,容易出现504超时。
* 设置客户端超时时间:把客户端超时时间设置大一些,防止未输出完成,达到客户端超时时间被截断。
* 通过第三方客户端请求,输出截断问题排查:
* CherryStdio 默认的 max\_tokens 是 4096,用户可以通过设置,打开“开启消息长度限制”的开关,将max\_token设置到合适值
 **5. 错误码处理**
| 错误码 | 常见原因 | 解决方案 |
| ------- | -------------- | --------------------------- |
| 400 | 参数格式错误 | 检查temperature等请求参数的取值范围 |
| 401 | API Key 没有正确设置 | 检查API Key |
| 403 | 权限不够 | 最常见的原因是该模型需要实名认证,其他情况参考报错信息 |
| 429 | 请求频率超限 | 实施指数退避重试机制 |
| 503/504 | 模型过载 | 切换备用模型节点 |
**6. x-siliconcloud-trace-id**
响应头(Response Headers)
| 参数名 | 类型 | 示例值 | 描述 |
| ----------------------- | ------ | ------- | ------------------------- |
| x-siliconcloud-trace-id | string | ti\_xxx | 用于追踪请求的唯一标识符,便于日志查询和问题排查。 |
**说明**
* x-siliconcloud-trace-id 是一个全局唯一的字符串,通常以 UUID 格式生成。
* 客户端可以在调试或排查问题时,将该 x-siliconcloud-trace-id 提供给后端开发人员,以便快速定位请求链路中的日志信息。
* 此字段由服务端自动生成并返回,客户端无需主动设置
## 5. 计费与配额管理
### 5.1 计费公式
`总费用 = (输入tokens × 输入单价) + (输出tokens × 输出单价) `
### 5.2 支持模型列表及单价
支持的模型及具体价格可以进入[模型广场](https://cloud.siliconflow.cn/me/models?types=chat)下的模型详情页查看。
## 6. 应用案例
### 6.1 技术文档生成
```python theme={null}
from openai import OpenAI
client = OpenAI(api_key="YOUR_KEY", base_url="https://api.siliconflow.cn/v1")
response = client.chat.completions.create(
model="Qwen/Qwen2.5-Coder-32B-Instruct",
messages=[{
"role": "user",
"content": "编写Python异步爬虫教程,包含代码示例和注意事项"
}],
temperature=0.7,
max_tokens=4096
)
```
### 6.2 数据分析报告
```python theme={null}
from openai import OpenAI
client = OpenAI(api_key="YOUR_KEY", base_url="https://api.siliconflow.cn/v1")
response = client.chat.completions.create(
model="Qwen/QVQ-72B-Preview",
messages=[
{"role": "system", "content": "你是数据分析专家,用Markdown输出结果"},
{"role": "user", "content": "分析2023年新能源汽车销售数据趋势"}
],
temperature=0.7,
max_tokens=4096
)
```
模型能力持续更新中,建议定期访问[模型广场](https://cloud.siliconflow.cn/models)获取最新信息。
**5. 错误码处理**
| 错误码 | 常见原因 | 解决方案 |
| ------- | -------------- | --------------------------- |
| 400 | 参数格式错误 | 检查temperature等请求参数的取值范围 |
| 401 | API Key 没有正确设置 | 检查API Key |
| 403 | 权限不够 | 最常见的原因是该模型需要实名认证,其他情况参考报错信息 |
| 429 | 请求频率超限 | 实施指数退避重试机制 |
| 503/504 | 模型过载 | 切换备用模型节点 |
**6. x-siliconcloud-trace-id**
响应头(Response Headers)
| 参数名 | 类型 | 示例值 | 描述 |
| ----------------------- | ------ | ------- | ------------------------- |
| x-siliconcloud-trace-id | string | ti\_xxx | 用于追踪请求的唯一标识符,便于日志查询和问题排查。 |
**说明**
* x-siliconcloud-trace-id 是一个全局唯一的字符串,通常以 UUID 格式生成。
* 客户端可以在调试或排查问题时,将该 x-siliconcloud-trace-id 提供给后端开发人员,以便快速定位请求链路中的日志信息。
* 此字段由服务端自动生成并返回,客户端无需主动设置
## 5. 计费与配额管理
### 5.1 计费公式
`总费用 = (输入tokens × 输入单价) + (输出tokens × 输出单价) `
### 5.2 支持模型列表及单价
支持的模型及具体价格可以进入[模型广场](https://cloud.siliconflow.cn/me/models?types=chat)下的模型详情页查看。
## 6. 应用案例
### 6.1 技术文档生成
```python theme={null}
from openai import OpenAI
client = OpenAI(api_key="YOUR_KEY", base_url="https://api.siliconflow.cn/v1")
response = client.chat.completions.create(
model="Qwen/Qwen2.5-Coder-32B-Instruct",
messages=[{
"role": "user",
"content": "编写Python异步爬虫教程,包含代码示例和注意事项"
}],
temperature=0.7,
max_tokens=4096
)
```
### 6.2 数据分析报告
```python theme={null}
from openai import OpenAI
client = OpenAI(api_key="YOUR_KEY", base_url="https://api.siliconflow.cn/v1")
response = client.chat.completions.create(
model="Qwen/QVQ-72B-Preview",
messages=[
{"role": "system", "content": "你是数据分析专家,用Markdown输出结果"},
{"role": "user", "content": "分析2023年新能源汽车销售数据趋势"}
],
temperature=0.7,
max_tokens=4096
)
```
模型能力持续更新中,建议定期访问[模型广场](https://cloud.siliconflow.cn/models)获取最新信息。